La similitud del documento, como sugiere el nombre, determina qué tan similares son los dos documentos dados. Por «documentos», nos referimos a una colección de strings. Por ejemplo, un ensayo o un archivo .txt. Muchas organizaciones utilizan este principio de similitud de documentos para comprobar el plagio. También lo utilizan muchas instituciones que realizan exámenes para verificar si un estudiante hizo trampa al otro. Por lo tanto, es muy importante a la vez que interesante saber cómo funciona todo esto.
La similitud del documento se calcula calculando la distancia del documento. La distancia del documento es un concepto en el que las palabras (documentos) se tratan como vectores y se calcula como el ángulo entre dos vectores de documentos dados. Los vectores de documentos son la frecuencia de aparición de palabras en un documento dado. Veamos un ejemplo:
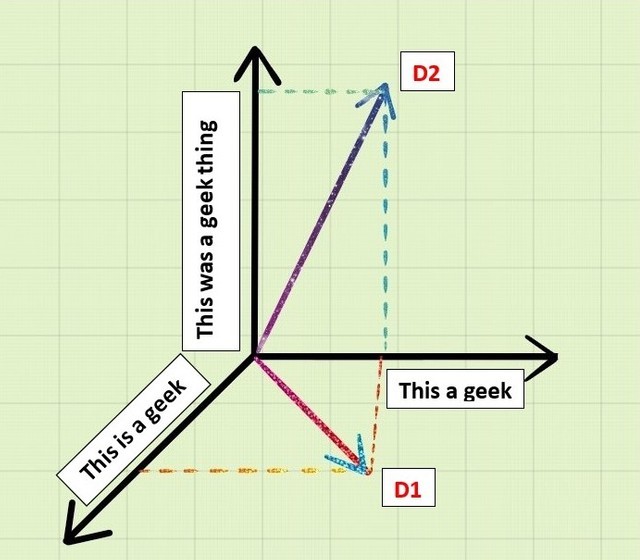
Digamos que nos dan dos documentos D1 y D2 como:
D1 : “Esto es un geek”
D2 : “Esto era una cosa de geek”
Las palabras similares en ambos documentos se convierten en:
"This a geek"
Si hacemos una representación tridimensional de esto como vectores tomando D1, D2 y palabras similares en geometría de 3 ejes, entonces obtenemos:
Ahora, si tomamos el producto escalar de D1 y D2 ,
D1.D2 = "This"."This"+"is"."was"+"a"."a"+"geek"."geek"+"thing".0
D1.D2 = 1+0+1+1+0
D1.D2 = 3
Ahora que sabemos cómo calcular el producto escalar de estos documentos, ahora podemos calcular el ángulo entre los vectores del documento:
cos d = D1.D2/|D1||D2|
Aquí d es la distancia del documento. Su valor oscila entre 0 y 90 grados. Donde 0 grados significa que los dos documentos son exactamente idénticos y 90 grados indican que los dos documentos son muy diferentes.
Ahora que sabemos acerca de la similitud y la distancia del documento, veamos un programa de Python para calcular lo mismo:
Programa de similitud de documentos:
Nuestro algoritmo para confirmar la similitud de los documentos constará de tres pasos fundamentales:
- Divide los documentos en palabras.
- Calcule las frecuencias de las palabras.
- Calcule el producto escalar de los vectores del documento.
Para el primer paso, primero usaremos el .read()método para abrir y leer el contenido de los archivos. A medida que leamos los contenidos, los dividiremos en una lista. A continuación, calcularemos la lista de frecuencia de palabras de la lectura en el archivo. Por lo tanto, se cuenta la aparición de cada palabra y la lista se ordena alfabéticamente.
import math
import string
import sys
# reading the text file
# This functio will return a
# list of the lines of text
# in the file.
def read_file(filename):
try:
with open(filename, 'r') as f:
data = f.read()
return data
except IOError:
print("Error opening or reading input file: ", filename)
sys.exit()
# splitting the text lines into words
# translation table is a global variable
# mapping upper case to lower case and
# punctuation to spaces
translation_table = str.maketrans(string.punctuation+string.ascii_uppercase,
" "*len(string.punctuation)+string.ascii_lowercase)
# returns a list of the words
# in the file
def get_words_from_line_list(text):
text = text.translate(translation_table)
word_list = text.split()
return word_list
Ahora que tenemos la lista de palabras, calcularemos la frecuencia de aparición de las palabras.
# counts frequency of each word
# returns a dictionary which maps
# the words to their frequency.
def count_frequency(word_list):
D = {}
for new_word in word_list:
if new_word in D:
D[new_word] = D[new_word] + 1
else:
D[new_word] = 1
return D
# returns dictionary of (word, frequency)
# pairs from the previous dictionary.
def word_frequencies_for_file(filename):
line_list = read_file(filename)
word_list = get_words_from_line_list(line_list)
freq_mapping = count_frequency(word_list)
print("File", filename, ":", )
print(len(line_list), "lines, ", )
print(len(word_list), "words, ", )
print(len(freq_mapping), "distinct words")
return freq_mapping
Por último, calcularemos el producto punto para dar la distancia del documento.
# returns the dot product of two documents def dotProduct(D1, D2): Sum = 0.0 for key in D1: if key in D2: Sum += (D1[key] * D2[key]) return Sum # returns the angle in radians # between document vectors def vector_angle(D1, D2): numerator = dotProduct(D1, D2) denominator = math.sqrt(dotProduct(D1, D1)*dotProduct(D2, D2)) return math.acos(numerator / denominator)
¡Eso es todo! Es hora de ver la función de similitud de documentos:
def documentSimilarity(filename_1, filename_2):
# filename_1 = sys.argv[1]
# filename_2 = sys.argv[2]
sorted_word_list_1 = word_frequencies_for_file(filename_1)
sorted_word_list_2 = word_frequencies_for_file(filename_2)
distance = vector_angle(sorted_word_list_1, sorted_word_list_2)
print("The distance between the documents is: % 0.6f (radians)"% distance)
Aquí está el código fuente completo.
import math
import string
import sys
# reading the text file
# This functio will return a
# list of the lines of text
# in the file.
def read_file(filename):
try:
with open(filename, 'r') as f:
data = f.read()
return data
except IOError:
print("Error opening or reading input file: ", filename)
sys.exit()
# splitting the text lines into words
# translation table is a global variable
# mapping upper case to lower case and
# punctuation to spaces
translation_table = str.maketrans(string.punctuation+string.ascii_uppercase,
" "*len(string.punctuation)+string.ascii_lowercase)
# returns a list of the words
# in the file
def get_words_from_line_list(text):
text = text.translate(translation_table)
word_list = text.split()
return word_list
# counts frequency of each word
# returns a dictionary which maps
# the words to their frequency.
def count_frequency(word_list):
D = {}
for new_word in word_list:
if new_word in D:
D[new_word] = D[new_word] + 1
else:
D[new_word] = 1
return D
# returns dictionary of (word, frequency)
# pairs from the previous dictionary.
def word_frequencies_for_file(filename):
line_list = read_file(filename)
word_list = get_words_from_line_list(line_list)
freq_mapping = count_frequency(word_list)
print("File", filename, ":", )
print(len(line_list), "lines, ", )
print(len(word_list), "words, ", )
print(len(freq_mapping), "distinct words")
return freq_mapping
# returns the dot product of two documents
def dotProduct(D1, D2):
Sum = 0.0
for key in D1:
if key in D2:
Sum += (D1[key] * D2[key])
return Sum
# returns the angle in radians
# between document vectors
def vector_angle(D1, D2):
numerator = dotProduct(D1, D2)
denominator = math.sqrt(dotProduct(D1, D1)*dotProduct(D2, D2))
return math.acos(numerator / denominator)
def documentSimilarity(filename_1, filename_2):
# filename_1 = sys.argv[1]
# filename_2 = sys.argv[2]
sorted_word_list_1 = word_frequencies_for_file(filename_1)
sorted_word_list_2 = word_frequencies_for_file(filename_2)
distance = vector_angle(sorted_word_list_1, sorted_word_list_2)
print("The distance between the documents is: % 0.6f (radians)"% distance)
# Driver code
documentSimilarity('GFG.txt', 'file.txt')
Producción:
File GFG.txt : 15 lines, 4 words, 4 distinct words File file.txt : 22 lines, 5 words, 5 distinct words The distance between the documents is: 0.835482 (radians)
Publicación traducida automáticamente
Artículo escrito por agarwalkeshav8399 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA