Introducción:
El algoritmo find-S es un algoritmo de aprendizaje de conceptos básicos en el aprendizaje automático. El algoritmo find-S encuentra la hipótesis más específica que se ajusta a todos los ejemplos positivos. Tenemos que señalar aquí que el algoritmo considera solo aquellos ejemplos de entrenamiento positivos. El algoritmo find-S comienza con la hipótesis más específica y generaliza esta hipótesis cada vez que falla al clasificar un dato de entrenamiento positivo observado. Por lo tanto, el algoritmo Find-S se mueve de la hipótesis más específica a la hipótesis más general.
Representación importante:
- ? indica que cualquier valor es aceptable para el atributo.
- especifique un solo valor obligatorio (p. ej., Frío) para el atributo.
- ϕ indica que ningún valor es aceptable.
- La hipótesis más general está representada por: {?, ?, ?, ?, ?, ?}
- La hipótesis más específica está representada por: {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ}
Pasos involucrados en Find-S:
- Comience con la hipótesis más específica.
h = {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ} - Tome el siguiente ejemplo y si es negativo, entonces no se producen cambios en la hipótesis.
- Si el ejemplo es positivo y encontramos que nuestra hipótesis inicial es demasiado específica, entonces actualizamos nuestra hipótesis actual a una condición general.
- Siga repitiendo los pasos anteriores hasta completar todos los ejemplos de entrenamiento.
- Una vez que hayamos completado todos los ejemplos de entrenamiento, tendremos la hipótesis final cuando podamos clasificar los nuevos ejemplos.
Ejemplo :
Considere el siguiente conjunto de datos que tiene los datos sobre qué semillas en particular son venenosas.
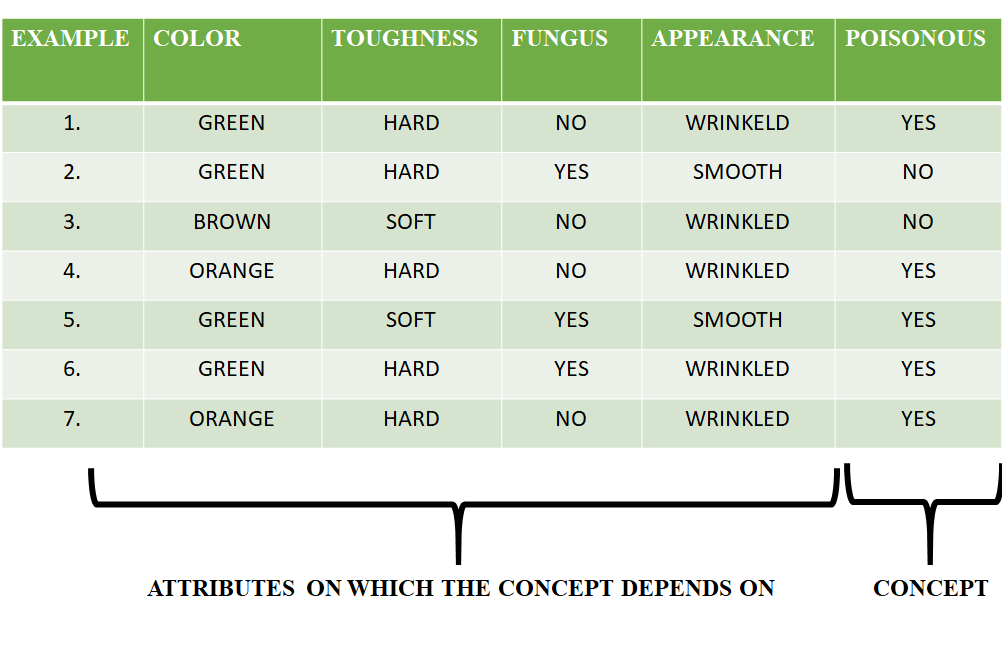
En primer lugar, consideramos que la hipótesis es una hipótesis más específica. Por tanto, nuestra hipótesis sería:
h = {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ}
Considere el ejemplo 1:
Los datos del ejemplo 1 son { VERDE, DURO, NO, ARRUGADO }. Vemos que nuestra hipótesis inicial es más específica y tenemos que generalizarla para este ejemplo. Por lo tanto, la hipótesis se convierte en:
h = { VERDE, DURO, NO, ARRUGADO }
Considere el ejemplo 2:
Aquí vemos que este ejemplo tiene un resultado negativo. Por lo tanto, ignoramos este ejemplo y nuestra hipótesis sigue siendo la misma.
h = { VERDE, DURO, NO, ARRUGADO }
Considere el ejemplo 3:
Aquí vemos que este ejemplo tiene un resultado negativo. Por lo tanto, ignoramos este ejemplo y nuestra hipótesis sigue siendo la misma.
h = { VERDE, DURO, NO, ARRUGADO }
Considere el ejemplo 4:
Los datos presentes en el ejemplo 4 son { NARANJA, DURO, NO, ARRUGADO }. Comparamos cada atributo individual con los datos iniciales y, si se encuentra alguna discrepancia, reemplazamos ese atributo en particular con un caso general ( ” ? ” ). Después de hacer el proceso la hipótesis se convierte en:
h = { ?, DURO, NO, ARRUGADO }
Considere el ejemplo 5:
Los datos presentes en el ejemplo 5 son { VERDE, SUAVE, SÍ, SUAVE }. Comparamos cada atributo individual con los datos iniciales y, si se encuentra alguna discrepancia, reemplazamos ese atributo en particular con un caso general ( ” ? ” ). Después de hacer el proceso la hipótesis se convierte en:
h = { ?, ?, ?, ? }
Como hemos llegado a un punto en el que todos los atributos de nuestra hipótesis tienen la condición general, el ejemplo 6 y el ejemplo 7 darían como resultado las mismas hipótesis con todos los atributos generales.
h = { ?, ?, ?, ? }
Por tanto, para los datos dados la hipótesis final sería: Hipótesis
final: h = { ?, ?, ?, ? }
Algoritmo:
1. Initialize h to the most specific hypothesis in H
2. For each positive training instance x
For each attribute constraint a, in h
If the constraint a, is satisfied by x
Then do nothing
Else replace a, in h by the next more general constraint that is satisfied by x
3. Output hypothesis h
Publicación traducida automáticamente
Artículo escrito por sunilkannur98 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA