En este artículo, discutiremos cómo hacer la agregación de múltiples criterios en PySpark Dataframe.
Trama de datos en uso:
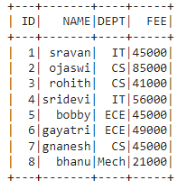
En PySpark, groupBy() se usa para recopilar datos idénticos en grupos en PySpark DataFrame y realizar funciones agregadas en los datos agrupados. Entonces, con esto podemos hacer múltiples agregaciones a la vez.
Sintaxis :
dataframe.groupBy(‘column_name_group’).agg(funciones)
dónde,
- column_name_group es la columna que se agrupará
- funciones son las funciones de agregación
Entendamos primero qué son las agregaciones. Están disponibles en el módulo de funciones en pyspark.sql, por lo que debemos importarlo para empezar. Las funciones agregadas son:
- count(): esto devolverá el recuento de filas para cada grupo.
Sintaxis:
funciones.contar(‘nombre_columna’)
- mean(): Esto devolverá la media de los valores para cada grupo.
Sintaxis:
funciones.mean(‘nombre_columna’)
- max() : Esto devolverá el máximo de valores para cada grupo.
Sintaxis:
funciones.max(‘nombre_columna’)
- min(): Esto devolverá el mínimo de valores para cada grupo.
Sintaxis:
funciones.min(‘nombre_columna’)
- sum(): Esto devolverá los valores totales para cada grupo.
Sintaxis:
funciones.sum(‘nombre_columna’)
- avg(): Esto devolverá el promedio de valores para cada grupo.
Sintaxis:
funciones.avg(‘nombre_columna’)
Podemos agregar múltiples funciones usando la siguiente sintaxis.
Sintaxis:
dataframe.groupBy(‘column_name_group’).agg(funciones….)
Ejemplo: agregaciones múltiples en la columna DEPT con la columna FEE
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# aggregating DEPT column with min.max,sum,mean,avg and count functions
dataframe.groupBy('DEPT').agg(functions.min('FEE'),
functions.max('FEE'),
functions.sum('FEE'),
functions.mean('FEE'),
functions.count('FEE'),
functions.avg('FEE')).show()
Producción:

Ejemplo 2: agregación múltiple en la agrupación de departamento y columna de nombre
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# aggregating DEPT, NAME column with min.max,
# sum,mean,avg and count functions
dataframe.groupBy('DEPT', 'NAME').agg(functions.min('FEE'),
functions.max('FEE'),
functions.sum('FEE'),
functions.mean('FEE'),
functions.count('FEE'),
functions.avg('FEE')).show()
Producción:

Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA