En primer lugar, el marco de datos de pandas almacena datos en forma de tabla. En algunas situaciones, necesitamos recuperar datos del marco de datos de acuerdo con algunas condiciones. Por ejemplo, si queremos obtener los N registros principales de cada grupo del marco de datos. Aquí usaremos la función Groupby() de pandas para agrupar las columnas. Entonces podemos hacerlo de la siguiente manera:
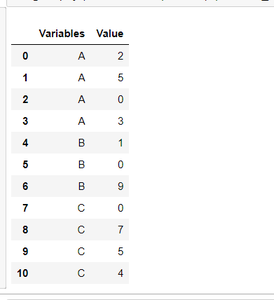
En primer lugar, creamos un marco de datos de pandas:
Python3
#importing pandas as pd
import pandas as pd
#creating dataframe
df=pd.DataFrame({ 'Variables': ['A','A','A','A','B','B',
'B','C','C','C','C'],
'Value': [2,5,0,3,1,0,9,0,7,5,4]})
df
Producción:
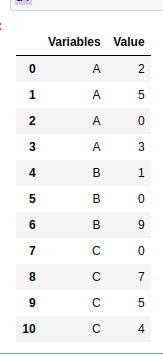
Ahora, obtendremos los valores N más altos de cada grupo de la columna ‘Variables’. Aquí reset_index() se usa para proporcionar un nuevo índice de acuerdo con la agrupación de datos. Y head() se usa para obtener valores N superiores desde la parte superior.
Ejemplo 1: Supongamos que el valor de N=2
Python3
# setting value of N as 2
N = 2
# using groupby to group acc. to
# column 'Variable'
df.groupby('Variables').head(N).reset_index(drop=True)
Producción:
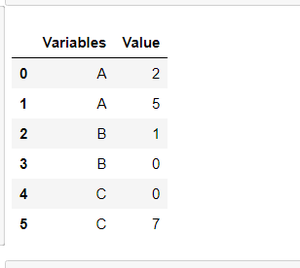
Ejemplo 2: Ahora, supongamos el valor de N=4
Python3
# setting value of N as 2
N = 4
# using groupby to group acc.
# to column 'Variable'
df.groupby('Variables').head(N).reset_index(drop=True)
Producción: