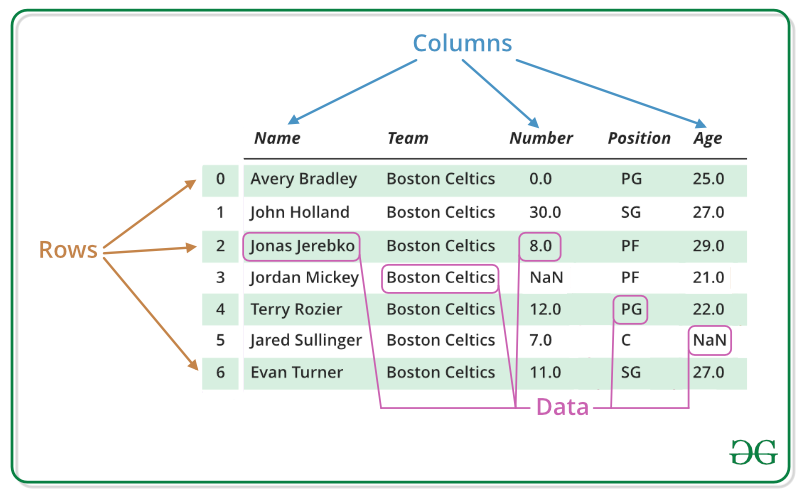
Los DataFrames son objetos de datos genéricos de R que se utilizan para almacenar los datos tabulares. Los marcos de datos se consideran los objetos de datos más populares en la programación R porque es más cómodo analizar los datos en forma tabular. Los marcos de datos también se pueden enseñar como colchones donde cada columna de una array puede ser de diferentes tipos de datos. DataFrame se compone de tres componentes principales, los datos, las filas y las columnas.
Las operaciones que se pueden realizar en un DataFrame son:
- Creación de un marco de datos
- Acceso a filas y columnas
- Seleccionar el subconjunto del marco de datos
- Edición de marcos de datos
- Agregar filas y columnas adicionales al marco de datos
- Agregue nuevas variables al marco de datos en función de las existentes
- Eliminar filas y columnas en un marco de datos
Creación de un marco de datos
En el mundo real, se creará un marco de datos cargando los conjuntos de datos del almacenamiento existente, el almacenamiento puede ser una base de datos SQL, un archivo CSV y un archivo de Excel. DataFrame también se puede crear a partir de los vectores en R. Las siguientes son algunas de las diversas formas que se pueden usar para crear un DataFrame:
Creación de un marco de datos usando vectores: para crear un marco de datos, usamos la función data.frame() en R. Para crear un marco de datos, use el comando data.frame() y luego pase cada uno de los vectores que ha creado como argumentos al función.
Ejemplo:
Python3
# R program to illustrate dataframe
# A vector which is a character vector
Name = c("Amiya", "Raj", "Asish")
# A vector which is a character vector
Language = c("R", "Python", "Java")
# A vector which is a numeric vector
Age = c(22, 25, 45)
# To create dataframe use data.frame command and
# then pass each of the vectors
# we have created as arguments
# to the function data.frame()
df = data.frame(Name, Language, Age)
print(df)
Producción:
Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45
Crear un marco de datos usando datos de un archivo: Los marcos de datos también se pueden crear importando los datos de un archivo. Para esto, tienes que usar la función llamada ‘ read.table() ‘.
Sintaxis:
newDF = read.table(path="Path of the file")
Para crear un marco de datos a partir de un archivo CSV en R:
Sintaxis:
newDF = read.csv("FileName.csv")
Acceso a filas y columnas
La sintaxis para acceder a filas y columnas se proporciona a continuación,
df[val1, val2] df = dataframe object val1 = rows of a data frame val2 = columns of a data frame
Entonces, este ‘ val1 ‘ y ‘ val2 ‘ pueden ser una array de valores como «1:2» o «2:3», etc. Si especifica solo df[val2], esto se refiere solo al conjunto de columnas que necesita acceder desde el marco de datos.
Ejemplo: Selección de fila
Python3
# R program to illustrate operations
# on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
print(df)
# Accessing first and second row
cat("Accessing first and second row\n")
print(df[1:2, ])
Producción:
Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 Accessing first and second row Name Language Age 1 Amiya R 22 2 Raj Python 25
Ejemplo: Selección de columna
Python3
# R program to illustrate operations
# on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
print(df)
# Accessing first and second column
cat("Accessing first and second column\n")
print(df[, 1:2])
Producción:
Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 Accessing first and second column Name Language 1 Amiya R 2 Raj Python 3 Asish Java
Selección del subconjunto del DataFrame
También se puede crear un subconjunto de un DataFrame en función de ciertas condiciones con la ayuda de la siguiente sintaxis.
newDF = subconjunto (df, condiciones)
df = Condiciones del marco de datos original
= Ciertas condiciones
Ejemplo:
Python3
# R program to illustrate operations
# on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
print(df)
# Selecting the subset of the data frame
# where Name is equal to Amiya
# OR age is greater than 30
newDf = subset(df, Name =="Amiya"|Age>30)
cat("After Selecting the subset of the data frame\n")
print(newDf)
Producción:
Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 After Selecting the subset of the data frame Name Language Age 1 Amiya R 22 3 Asish Java 45
Edición de tramas de datos
En R, los marcos de datos se pueden editar de dos maneras:
Edición de marcos de datos mediante asignaciones directas: al igual que la lista en R, puede editar los marcos de datos mediante una asignación directa.
Ejemplo:
Python3
# R program to illustrate operation on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
cat("Before editing the dataframe\n")
print(df)
# Editing dataframes by direct assignments
# [[3]] accessing the top level components
# Here Age in this case
# [[3]][3] accessing inner level components
# Here Age of Asish in this case
df[[3]][3] = 30
cat("After edited the dataframe\n")
print(df)
Producción:
Before editing the data frame Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 After edited the data frame Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 30
Edición de marcos de datos usando el comando editar():
siga los pasos dados para editar un marco de datos:
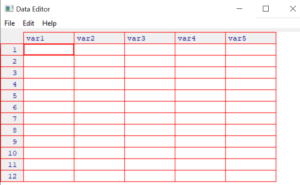
Paso 1 : Entonces, lo que debe hacer para esto es crear una instancia de marco de datos, por ejemplo, puede ver que aquí se crea una instancia de un marco de datos y se nombra como «miTabla» usando el comando datos .frame() y esto crea un marco de datos vacío.
miTabla = data.frame()
Paso 2 : A continuación, usaremos la función de edición para iniciar el visor. Tenga en cuenta que el marco de datos «myTable» se devuelve al objeto «myTable» y, de esta manera, los cambios que hagamos en este módulo se guardarán en el objeto original.
miTabla = edit(miTabla)
Entonces, cuando se ejecuta el comando anterior, aparecerá una ventana como esta,
Paso 3 : Ahora, la tabla se completa con esta pequeña lista.
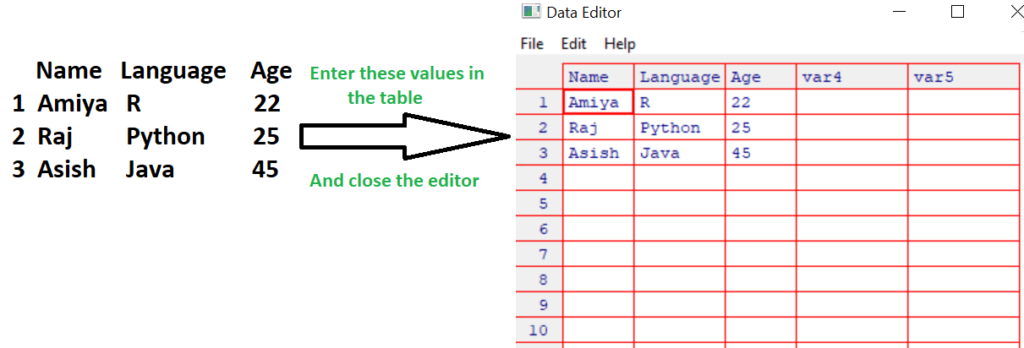
Tenga en cuenta que cambie los nombres de las variables haciendo clic en sus etiquetas y escribiendo sus cambios. Las variables también se pueden establecer como numéricas o de carácter. Una vez que los datos en el DataFrame se vean como los anteriores, cierre la tabla. Los cambios se guardan automáticamente.
Paso 4: verifique el marco de datos resultante imprimiéndolo.
> miMesa
Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45
Agregar filas y columnas al marco de datos
Agregar filas adicionales: podemos agregar filas adicionales usando el comando rbind() . La sintaxis para esto se da a continuación,
newDF = rbind(df, las entradas para la nueva fila que debe agregar)
df = Marco de datos original
Tenga en cuenta que las entradas para la nueva fila que debe agregar debe tener cuidado al usar rbind() porque los tipos de datos en cada entrada de columna deben ser iguales a los tipos de datos que ya son filas existentes.
Ejemplo:
Python3
# R program to illustrate operation on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
cat("Before adding row\n")
print(df)
# Add a new row using rbind()
newDf = rbind(df, data.frame(Name = "Sandeep",
Language = "C",
Age = 23
))
cat("After Added a row\n")
print(newDf)
Producción:
Before adding row
Name Language Age
1 Amiya R 22
2 Raj Python 25
3 Asish Java 45
After Added a row
Name Language Age
1 Amiya R 22
2 Raj Python 25
3 Asish Java 45
4 Sandeep C 23
Agregar columnas adicionales: podemos agregar una columna adicional usando el comando cbind() . La sintaxis para esto se da a continuación,
newDF = cbind(df, las entradas para la nueva columna que debe agregar)
df = Marco de datos original
Ejemplo:
Python3
# R program to illustrate operation on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
cat("Before adding column\n")
print(df)
# Add a new column using cbind()
newDf = cbind(df, Rank=c(3, 5, 1))
cat("After Added a column\n")
print(newDf)
Producción:
Before adding column Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 After Added a column Name Language Age Rank 1 Amiya R 22 3 2 Raj Python 25 5 3 Asish Java 45 1
Agregar nuevas variables a DataFrame
En R, podemos agregar nuevas variables a un marco de datos en función de las existentes. Para hacer eso, primero debemos llamar a la biblioteca dplyr usando el comando library() . Y luego llamar a la función mutate() agregará columnas variables adicionales basadas en las existentes.
Sintaxis:
biblioteca (dplyr)
newDF = mutar (df, new_var=[existing_var])
df = marco de datos original
new_var = Nombre de la nueva variableexistent_var
= La acción de modificación que está tomando (por ejemplo, valor de registro, multiplicar por 10)
Ejemplo:
Python3
# R program to illustrate operation on a data frame
# Importing the dplyr library
library(dplyr)
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
cat("Original Dataframe\n")
print(df)
# Creating an extra variable column
# "log_Age" which is log of variable column "Age"
# Using mutate() command
newDf = mutate(df, log_Age = log(Age))
cat("After creating extra variable column\n")
print(newDf)
Producción:
Original Dataframe Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 After creating extra variable column Name Language Age log_Age 1 Amiya R 22 3.091042 2 Raj Python 25 3.218876 3 Asish Java 45 3.806662
Eliminar filas y columnas de un marco de datos
Para eliminar una fila o una columna, en primer lugar, debe acceder a esa fila o columna y luego insertar un signo negativo antes de esa fila o columna. Indica que tuviste que eliminar esa fila o columna.
Sintaxis:
newDF = df[-rowNo, -colNo]
df = marco de datos original
Ejemplo:
Python3
# R program to illustrate operation on a data frame
# Creating a dataframe
df = data.frame(
"Name" = c("Amiya", "Raj", "Asish"),
"Language" = c("R", "Python", "Java"),
"Age" = c(22, 25, 45)
)
cat("Before deleting the 3rd row and 2nd column\n")
print(df)
# delete the third row and the second column
newDF = df[-3, -2]
cat("After Deleted the 3rd row and 2nd column\n")
print(newDF)
Producción:
Before deleting the 3rd row and 2nd column Name Language Age 1 Amiya R 22 2 Raj Python 25 3 Asish Java 45 After Deleted the 3rd row and 2nd column Name Age 1 Amiya 22 2 Raj 25
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA