En este artículo, analicemos cómo ordenar filas o columnas en Pandas Dataframe según los valores. El método Pandas sort_values() ordena un marco de datos en orden ascendente o descendente de la columna pasada. Es diferente a la función ordenada de Python, ya que no puede ordenar un marco de datos y no se puede seleccionar una columna en particular.
Sintaxis: DataFrame.sort_values(by, axis=0, ascendente=True, inplace=False, kind=’quicksort’, na_position=’last’)
Parámetros: Este método tomará los siguientes parámetros:
por: Único/Lista de nombres de columna para ordenar el marco de datos por.
eje: 0 o ‘índice’ para filas y 1 o ‘columnas’ para Columna.
ascendente: valor booleano que ordena el marco de datos en orden ascendente si es verdadero.
inplace: valor booleano. Realiza los cambios en el marco de datos pasado si es True.
kind: string que puede tener tres entradas (‘quicksort’, ‘mergesort’ o ‘heapsort’) del algoritmo utilizado para ordenar el marco de datos.
na_position: toma la entrada de dos strings ‘último’ o ‘primero’ para establecer la posición de los valores nulos. El valor predeterminado es ‘último’.Tipo de devolución: devuelve un marco de datos ordenado con las mismas dimensiones que el marco de datos de la persona que llama a la función.
Ahora, vamos a crear un marco de datos de muestra:
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# show the dataframe
details
Producción: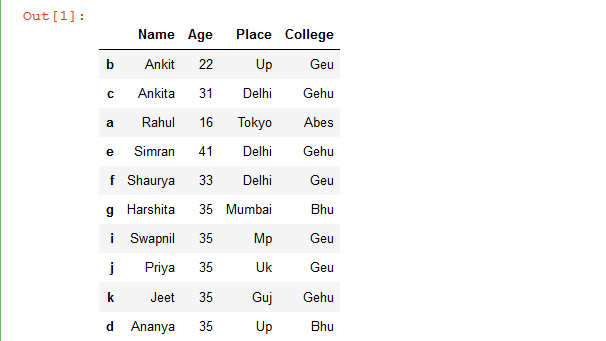
Ejemplo 1: ordenar las filas del marco de datos en función de una sola columna.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# Sort the rows of dataframe by 'Name' column
rslt_df = details.sort_values(by = 'Name')
# show the resultant Dataframe
rslt_df
Producción: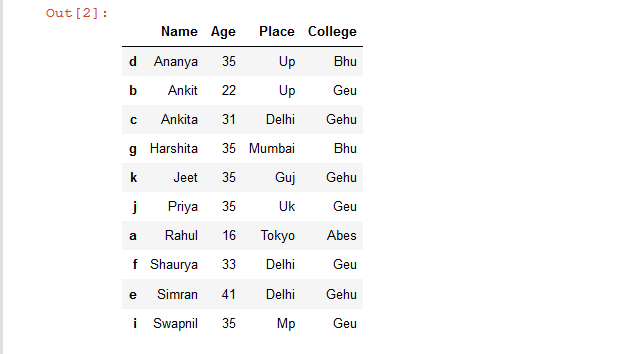
Ejemplo 2: ordenar las filas del marco de datos en función de varias columnas.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ananya', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Priya', 35, 'Mp', 'Geu'),
('Priya', 34, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort Dataframe rows based on a 'Name' & 'Age' columns
# if duplicate value is present in 'Name' column
# then sorting will be done according to 'Age' column
rslt_df = details.sort_values(by = ['Name', 'Age'])
# show the resultant Dataframe
rslt_df
Producción: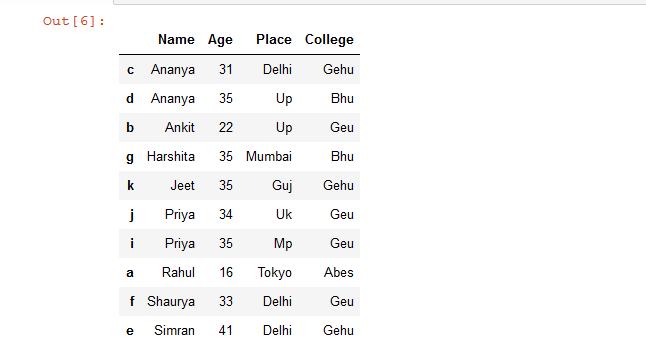
Ejemplo 3: ordenar las filas del marco de datos en función de las columnas en orden descendente.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ananya', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Priya', 35, 'Mp', 'Geu'),
('Priya', 34, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort Dataframe rows based on "Name'
# column in Descending Order
rslt_df = details.sort_values(by = 'Name', ascending = False)
# show the resultant Dataframe
rslt_df
Producción: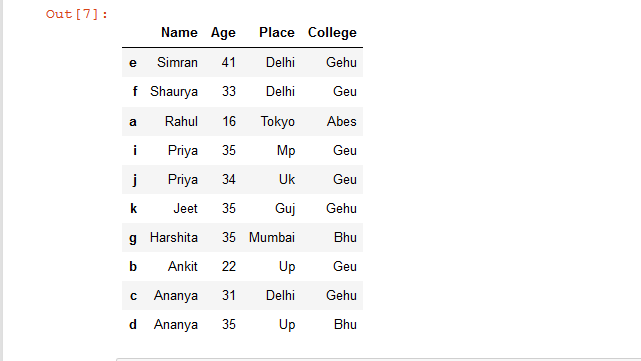
Ejemplo 4: ordenar las filas del marco de datos en función de una columna en el lugar.
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ananya', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Priya', 35, 'Mp', 'Geu'),
('Priya', 34, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# Sort the rows of dataframe by 'Name'
# column inplace
details.sort_values(by = 'Name', inplace = True)
# show the resultant Dataframe
details
Producción: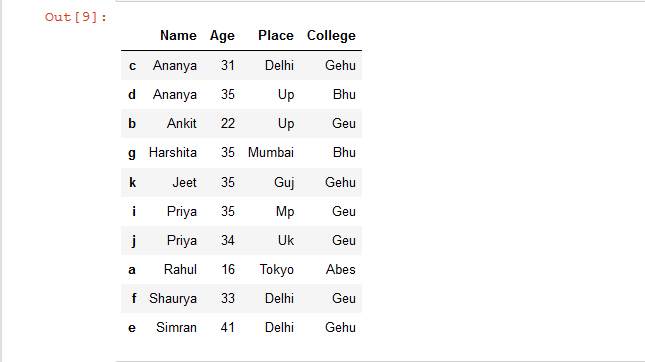
Veamos otro marco de datos simple en el que podemos ordenar las columnas en función de las filas.
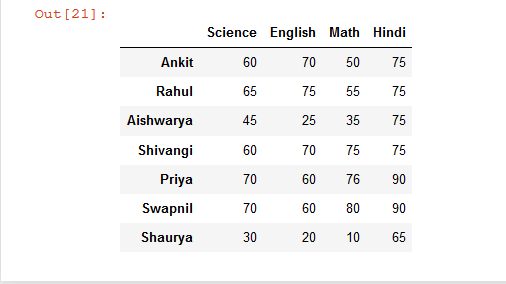
# import pandas library as pd import pandas as pd # List of Tuples students = [ (75, 50, 60, 70), (75, 55, 65, 75), (75, 35, 45, 25), (75, 90, 60, 70), (76, 90, 70, 60), (90, 80, 70, 60), (65, 10, 30, 20) ] # Create a DataFrame object from # list of tuples with columns # and indices. details = pd.DataFrame(students, columns =['Hindi', 'Math', 'Science', 'English'], index = ['Ankit', 'Rahul', 'Aishwarya', 'Shivangi', 'Priya', 'Swapnil', 'Shaurya']) # show the dataframe details
Producción: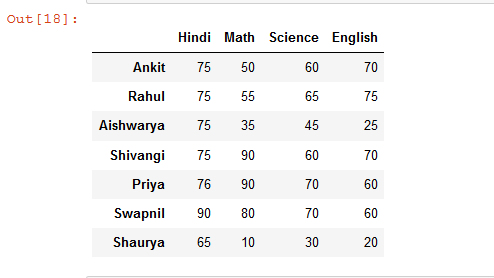
Ejemplo 1: ordenar las columnas de un marco de datos en función de una sola fila.
# import pandas library as pd import pandas as pd # List of Tuples students = [ (75, 50, 60, 70), (75, 55, 65, 75), (75, 35, 45, 25), (75, 90, 60, 70), (76, 90, 70, 60), (90, 80, 70, 60), (65, 10, 30, 20) ] # Create a DataFrame object from # list of tuples with columns # and indices. details = pd.DataFrame(students, columns =['Hindi', 'Math', 'Science', 'English'], index = ['Ankit', 'Rahul', 'Aishwarya', 'Shivangi', 'Priya', 'Swapnil', 'Shaurya']) # sort columns of a Dataframe based # on a 'Shivangi' row rslt_df = details.sort_values(by = 'Shivangi', axis = 1) # show the dataframe rslt_df
Producción: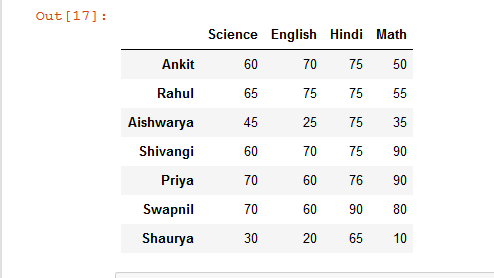
Ejemplo 2: ordenar las columnas de un marco de datos en orden descendente en función de una sola fila.
# import pandas library as pd import pandas as pd # List of Tuples students = [ (75, 50, 60, 70), (75, 55, 65, 75), (75, 35, 45, 25), (75, 90, 60, 70), (76, 90, 70, 60), (90, 80, 70, 60), (65, 10, 30, 20) ] # Create a DataFrame object from # list of tuples with columns # and indices. details = pd.DataFrame(students, columns =['Hindi', 'Math', 'Science', 'English'], index = ['Ankit', 'Rahul', 'Aishwarya', 'Shivangi', 'Priya', 'Swapnil', 'Shaurya']) # Sort columns of a dataframe in descending order # based on a 'Shivangi' row rslt_df = details.sort_values(by = 'Shivangi', axis = 1, ascending = False) rslt_df
Producción: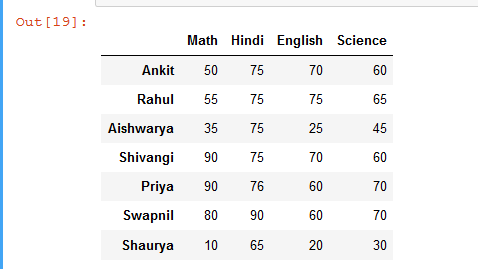
Ejemplo 3: ordenar las columnas de un marco de datos en función de varias filas.
# import pandas library as pd import pandas as pd # List of Tuples students = [ (75, 50, 60, 70), (75, 55, 65, 75), (75, 35, 45, 25), (75, 90, 60, 70), (76, 90, 70, 60), (90, 80, 70, 60), (65, 10, 30, 20) ] # Create a DataFrame object from # list of tuples with columns # and indices. details = pd.DataFrame(students, columns =['Hindi', 'Math', 'Science', 'English'], index = ['Ankit', 'Rahul', 'Aishwarya', 'Shivangi', 'Priya', 'Swapnil', 'Shaurya']) # sort Dataframe columns based on a 'Shivangi' & 'Priya' rows # if duplicate value is present in 'Shivangi' row # then sorting will be done according to 'Priya' row rslt_df = details.sort_values(by = ['Shivangi', 'Priya'], axis = 1) rslt_df
Producción: