Prerrequisitos: Pandas
Se pueden emplear pandas para contar la frecuencia de cada valor en el marco de datos por separado. Veamos cómo los valores de Groupby cuentan en el marco de datos de pandas. Para contar los valores de Groupby en el marco de datos de pandas, vamos a utilizar el método groupby() size() y unstack().
Funciones utilizadas:
- groupby(): la función groupby() se usa para dividir los datos en grupos según algunos criterios. Los objetos de Pandas se pueden dividir en cualquiera de sus ejes. La definición abstracta de agrupación es proporcionar un mapeo de etiquetas a nombres de grupos
Sintaxis:
DataFrame.groupby(by=Ninguno, axis=0, level=Ninguno, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parámetros:
- por: mapeo, función, str, o iterable
- eje: int, por defecto 0
- level : si el eje es un MultiIndex (jerárquico), agrupar por un nivel o niveles en particular
- as_index : para la salida agregada, devuelva el objeto con etiquetas de grupo como índice. Solo relevante para la entrada de DataFrame. as_index=False es efectivamente una salida agrupada de «estilo SQL»
- sort : Ordenar claves de grupo. Obtenga un mejor rendimiento desactivando esto. Tenga en cuenta que esto no influye en el orden de las observaciones dentro de cada grupo. groupby conserva el orden de las filas dentro de cada grupo.
- group_keys: al llamar a apply, agregue claves de grupo al índice para identificar piezas
- squeeze : reduce la dimensionalidad del tipo de retorno si es posible, de lo contrario, devuelve un tipo consistente
Devuelve: objeto GroupBy
- size(): el método de tamaño se utiliza para obtener el número entero que representa el número de elementos en el objeto. El método de tamaño devuelve el número de filas por el número de columnas si DataFrame.
Sintaxis:
Marco de datos.tamaño()
- unstack(): el método unstack funciona con los objetos MultiIndex en DataFrame, produciendo un DataFrame remodelado con un nuevo nivel más interno de etiquetas de columna.
Sintaxis:
Marco de datos.unstack()
Acercarse
- Módulo de importación
- Crear o cargar datos
- Crear marco de datos
- Contar el valor de las ocurrencias de cada valor
- Imprime el marco de datos resultante
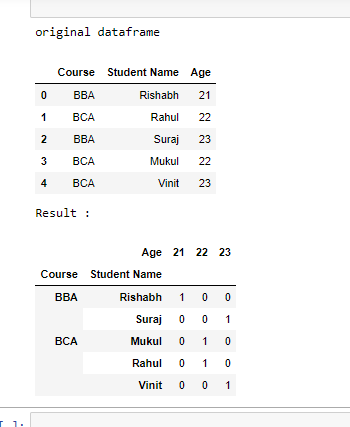
Ejemplo 1:
Python
# import pandas
import pandas as pd
# create dataframe
df = pd.DataFrame({
'Course': ['BBA', 'BCA', 'BBA', 'BCA', 'BCA'],
'Student Name': ['Rishabh', 'Rahul', 'Suraj', 'Mukul', 'Vinit'],
'Age': [21, 22, 23, 22, 23]})
# print original dataframe
print("original dataframe")
display(df)
# counts Groupby value
df = df.groupby(['Course', 'Student Name', 'Age']).size().unstack(fill_value=0)
# print dataframe
print("Result :")
display(df)
Producción:
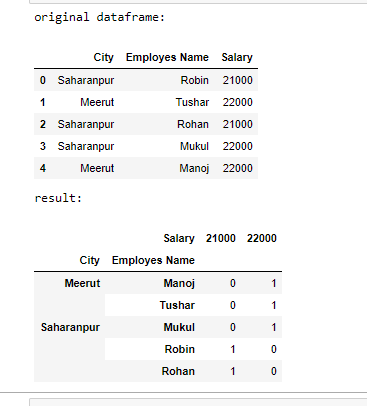
Ejemplo 2:
Python
# import pandas
import pandas as pd
# create dataframe
df = pd.DataFrame({
'City': ['Saharanpur', 'Meerut', 'Saharanpur', 'Saharanpur', 'Meerut'],
'Employes Name': ['Robin', 'Tushar', 'Rohan', 'Mukul', 'Manoj'],
'Salary': [21000, 22000, 21000, 22000, 22000]})
# print original dataframe
print("original dataframe: ")
display(df)
# counts Groupby value
df = df.groupby(['City', 'Employes Name', 'Salary']
).size().unstack(fill_value=0)
# print dataframe
print("result: ")
display(df)
Producción: