En este artículo, discutiremos cómo comparar dos DataFrames en pandas. Primero, creemos dos DataFrames.
Creando dos marcos de datos
Python3
import pandas as pd
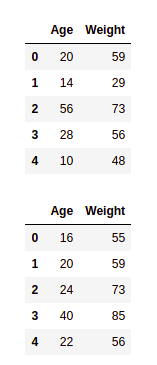
# first dataframe
df1 = pd.DataFrame({
'Age': ['20', '14', '56', '28', '10'],
'Weight': [59, 29, 73, 56, 48]})
display(df1)
# second dataframe
df2 = pd.DataFrame({
'Age': ['16', '20', '24', '40', '22'],
'Weight': [55, 59, 73, 85, 56]})
display(df2)
Producción:
Comprobando si dos marcos de datos son exactamente iguales
Al usar la función equals() podemos verificar directamente si df1 es igual a df2. Esta función se utiliza para determinar si dos objetos de marco de datos en consideración son iguales o no. A diferencia del método dataframe.eq(), el resultado de la operación es un valor booleano escalar que indica si los objetos del marco de datos son iguales o no.
Sintaxis:
Marco de datos.equals(df)
Ejemplo:
Python3
df1.equals(df2)
Producción:
False
También podemos verificar una columna en particular también.
Ejemplo:
Python3
df2['Age'].equals(df1['Age'])
Producción:
False
Encontrar las filas comunes entre dos DataFrames
Podemos usar la función merge() o la función concat() .
- La función merge() sirve como punto de entrada para todas las operaciones estándar de combinación de bases de datos entre objetos DataFrame. La función de combinación es similar a la combinación interna de SQL, encontramos las filas comunes entre dos marcos de datos.
- La función concat() hace todo el trabajo pesado de realizar operaciones de concatenación junto con un eje de objetos Pandas mientras realiza una lógica de conjunto opcional (unión o intersección) de los índices (si los hay) en los otros ejes.
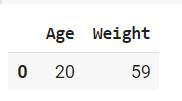
Ejemplo 1: Uso de la función de combinación
Python3
df = df1.merge(df2, how = 'inner' ,indicator=False) df
Producción:
Ejemplo 2: Uso de la función concat
Agregamos el segundo marco de datos (df2) debajo del primer marco de datos (df1) usando la función concat. Luego agrupamos por el nuevo marco de datos usando columnas y luego vemos qué filas tienen un conteo mayor a 1. Estas son las filas comunes. Así es como podemos usar-
Python3
df = pd.concat([df1, df2]) df = df.reset_index(drop=True) df_group = df.groupby(list(df.columns)) idx = [x[0] for x in df_group.groups.values() if len(x) > 1] df.reindex(idx)
Producción:
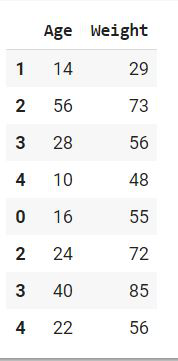
Encontrar las filas poco comunes entre dos DataFrames
Hemos visto cómo podemos obtener las filas comunes entre dos marcos de datos. Ahora, para filas poco comunes, podemos usar la función concat con un parámetro drop_duplicate.
Ejemplo:
Python3
pd.concat([df1,df2]).drop_duplicates(keep=False)
Producción:
Publicación traducida automáticamente
Artículo escrito por vanisinghal0201 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA