Pandas Groupby se usa en situaciones en las que queremos dividir los datos y establecerlos en grupos para que podamos realizar varias operaciones en esos grupos, como: agregación de datos, transformación a través de algunos cálculos grupales o filtración según condiciones específicas aplicadas en los grupos.
De manera similar, podemos realizar la clasificación dentro de estos grupos.
Ejemplo 1: Tomemos un ejemplo de un marco de datos:
df = pd.DataFrame({'X': ['B', 'B', 'A', 'A'],
'Y': [1, 2, 3, 4]})
# using groupby function
df.groupby('X').sum()
Producción:![]()
Pasemos el parámetro sort como False.
# using groupby function
# with sort
df.groupby('X', sort = False).sum()
Producción: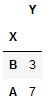
Aquí, vemos un marco de datos con valores ordenados dentro de los grupos.
Ejemplo 2:
Ahora, tomemos un ejemplo de un marco de datos con edades de diferentes personas. El uso de ordenar junto con la función groupby organizará el marco de datos transformado en función de los pases de teclas, para posibles aceleraciones.
data = {'Name':['Elle', 'Chloe', 'Noah', 'Marco',
'Lee', 'Elle', 'Rachel', 'Noah'],
'Age':[17, 19, 18, 17,
22, 18, 21, 20]}
df = pd.DataFrame(data)
df
Producción: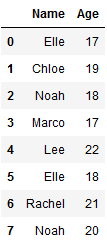
Agrupemos el marco de datos anterior según el nombre.
# using groupby without sort df.groupby(['Name']).sum()
Producción: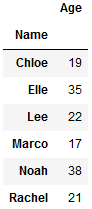
Pasar el parámetro de clasificación como falso
# using groupby function # with sort df.groupby(['Name'], sort = False).sum()
Producción: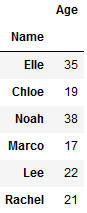
Ejemplo 3:
Tomemos otro ejemplo de un marco de datos que consta de velocidades máximas de varios autos y bicicletas.
Intentaremos ordenar las velocidades máximas dentro de los grupos de tipo de vehículo.
import pandas as pd
df = pd.DataFrame([('Bike', 'Kawasaki', 186),
('Bike', 'Ducati Panigale', 202),
('Car', 'Bugatti Chiron', 304),
('Car', 'Jaguar XJ220', 210),
('Bike', 'Lightning LS-218', 218),
('Car', 'Hennessey Venom GT', 270),
('Bike', 'BMW S1000RR', 188)],
columns =('Type', 'Name', 'top_speed(mph)'))
df
Producción: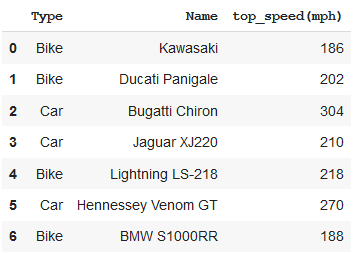
Después de usar la función groupby
# Using groupby function grouped = df.groupby(['Type'])['top_speed(mph)'].nlargest() # using nlargest() function will get the # largest values of top_speed(mph) within # groups created print(grouped)
Producción:
Publicación traducida automáticamente
Artículo escrito por devanshigupta1304 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA