Pandas es una biblioteca de código abierto que se basa en la biblioteca NumPy . Es un paquete de Python que ofrece varias estructuras de datos y operaciones para manipular datos numéricos y series de tiempo. Es principalmente popular para importar y analizar datos mucho más fácilmente. Pandas es rápido y tiene un alto rendimiento y productividad para los usuarios.
Groupby es un concepto bastante simple. Podemos crear una agrupación de categorías y aplicar una función a las categorías. Es un concepto simple, pero es una técnica extremadamente valiosa que se usa ampliamente en la ciencia de datos. Es útil en el sentido de que podemos:
- Calcular estadísticas de resumen para cada grupo
- Realizar transformaciones específicas de grupo
- Hacer la filtración de datos
groupby () implica una combinación de dividir el objeto, aplicar una función y combinar los resultados. Esto se puede usar para agrupar grandes cantidades de datos y calcular operaciones en estos grupos.
Ejemplo 1:
Python3
# import required module
import pandas as pd
# create dataframe
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', 'Parrot', 'Parrot'],
'Max Speed': [380., 370., 24., 26.]})
# use groupby() to compute mean
df.groupby(['Animal']).mean()
Producción

Ejemplo 2:
Python3
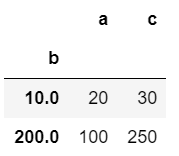
# import required module import pandas as pd # assign list l = [[100, 200, 300], [10, None, 40], [20, 10, 30], [100, 200, 200]] # create dataframe df = pd.DataFrame(l, columns=["a", "b", "c", ]) # use groupby() to generate mean df.groupby(by=["b"]).mean()
Producción:
Ejemplo 3:
Python3
# import required module
import pandas as pd
# assign data
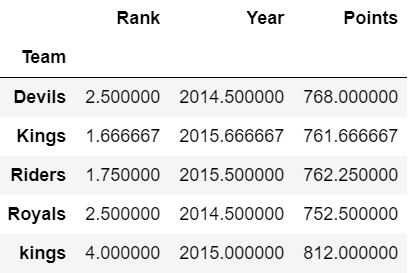
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3, 4, 1, 1, 2, 4, 1, 2],
'Year': [2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017],
'Points': [876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690]}
# create dataframe
df = pd.DataFrame(ipl_data)
# use groupby() to generate mean
df.groupby(['Team']).mean()
Producción:
Publicación traducida automáticamente
Artículo escrito por anitadesai73 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA