Pandas en Python es conocida como la herramienta más popular y poderosa para realizar análisis de datos. Es por la belleza de la funcionalidad de Pandas y la capacidad de trabajar en conjuntos y subconjuntos de un gran conjunto de datos. Entonces, en este artículo, vamos a estudiar cómo funciona la funcionalidad Agrupar por de pandas y cómo ahorra mucho esfuerzo mientras se trabaja en un gran conjunto de datos. Además, resolveremos problemas del mundo real utilizando las funcionalidades de Pandas Group By y Median.
Grupo de pandas()
El método groupby() en pandas divide el conjunto de datos en subconjuntos para facilitar los cálculos. Generalmente, groupby() divide los datos, aplica las funcionalidades y luego combina el resultado para nosotros. Tomemos un ejemplo si tenemos datos sobre el consumo de alcohol de diferentes países y queremos realizar un análisis de datos por continente, este problema se puede minimizar usando el método groupby() en pandas. Divide los datos por continentes y calcula la mediana utilizando el método mediana().
Sintaxis:
DataFrame.groupby(by=Ninguno, eje=0, nivel=Ninguno, as_index=True, sort=True, group_keys=True, squeeze=<objeto objeto>, observado=False, dropna=True)
Ejemplo 1 : Encuentre la mediana del consumo de alcohol por continente en un conjunto de datos determinado.
Conjunto de datos: Drinksbycountry.csv
Python3
# import the packages
import pandas as pd
# read Dataset
data = pd.read_csv("drinksbycountry.csv")
data.head()
# perform groupby on continent and find median
# of total_litres_of_pure_alcohol
data.groupby(["continent"])["total_litres_of_pure_alcohol"].median()
# perform groupby on continent and find median
# of wine_serving
data.groupby(["continent"])["wine_servings"].median()
Producción :

mediana de litros_totales_de_alcohol_puro
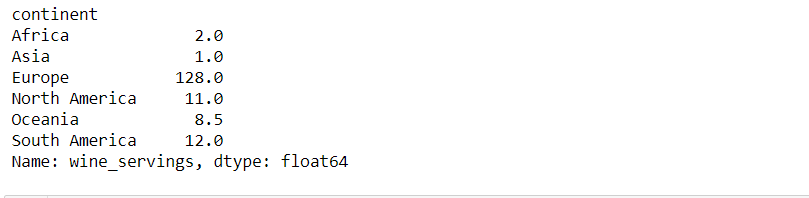
mediana de vino_servido
Ejemplo 2: Encuentre la mediana del grupo de población total por edad en un conjunto de datos determinado.
Conjunto de datos: WorldPopulationByAge2020.csv
Python3
# import packages
import pandas as pd
# read Dataset
data = pd.read_csv("WorldPopulationByAge2020.csv")
data.head()
# perform group by AgeGrp and find median
data.groupby(["AgeGrp"])["PopTotal"].median()
Producción :
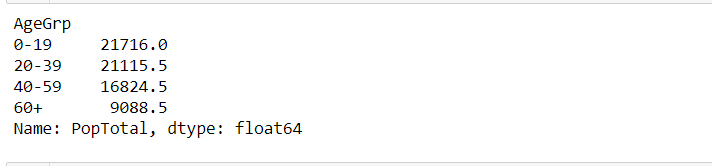
Agrupar por edad
Publicación traducida automáticamente
Artículo escrito por abhijitmahajan772 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA