En este artículo, discutiremos el índice múltiple para las operaciones Pandas Dataframe y Groupby .
El índice múltiple le permite seleccionar más de una fila y columna en su índice. Es un objeto de varios niveles o jerárquico para el objeto pandas. Ahora hay varios métodos de índices múltiples que se utilizan, como MultiIndex.from_arrays, MultiIndex.from_tuples, MultiIndex.from_product, MultiIndex.from_frame , etc., que nos ayudan a crear múltiples índices a partir de arrays, tuplas, marcos de datos, etc.
Sintaxis: pandas.MultiIndex(niveles=Ninguno, códigos=Ninguno, ordenación=Ninguno, nombres=Ninguno, dtype=Ninguno, copia=Falso, nombre=Ninguno, verificar_integridad=Verdadero)
- niveles : es una secuencia de arrays que muestra las etiquetas únicas para cada nivel.
- codes : También es una secuencia de arrays donde los números enteros en cada nivel nos ayudan a designar las etiquetas en esa ubicación.
- orden de clasificación : opcional int. Nos ayuda a ordenar lexicográficamente los niveles.
- dtype : tipo de datos (tamaño de los datos que pueden ser de 32 bits o 64 bits)
- copy : Es un parámetro de tipo booleano con valor por defecto como False. Nos ayuda a copiar los metadatos.
- verificar_integridad : Es un parámetro de tipo booleano con valor por defecto como Verdadero. Comprueba la integridad de los niveles y codifica si son válidos.
Veamos algunos ejemplos para entender mejor el concepto.
Ejemplo 1:
En este ejemplo, crearemos varios índices a partir de arrays. Se prefieren las arrays a las tuplas porque las tuplas son inmutables, mientras que si queremos cambiar el valor de un elemento en una array, podemos hacerlo. Así que pasemos al código y su explicación:
Después de importar todas las bibliotecas importantes, estamos creando una array de nombres junto con arrays de marcas y edad, respectivamente. Ahora, con la ayuda de MultiIndex.from_arrays, estamos combinando las tres arrays de manera que los elementos de las tres arrays formen múltiples índices juntos. Después de eso, estamos mostrando el resultado anterior.
Python3
# importing pandas library from
# python
import pandas as pd
# Creating an array of names
arrays = ['Sohom','Suresh','kumkum','subrata']
# Creating an array of ages
age= [10, 11, 12, 13]
# Creating an array of marks
marks=[90,92,23,64]
# Using MultiIndex.from_arrays, we are
# combining the arrays together along
# with their names and creating multi-index
# with each element from the 3 arrays into
# different rows
pd.MultiIndex.from_arrays([arrays,age,marks], names=('names', 'age','marks'))
Producción:

Ejemplo 2:
En este ejemplo, crearemos un índice múltiple a partir de un marco de datos utilizando pandas. Crearemos datos manuales y luego usaremos pd.dataframe , crearemos un marco de datos con el conjunto de datos. Ahora, usando la sintaxis de índice múltiple, crearemos un índice múltiple con un marco de datos.
En este ejemplo, estamos haciendo lo mismo que en el ejemplo anterior. La diferencia es que, en el ejemplo anterior, estábamos creando índices múltiples a partir de una lista de arrays, mientras que aquí creamos un marco de datos usando pd.dataframe y luego estamos creando índices múltiples a partir de ese marco de datos usando índices múltiples. from_frame() junto con los nombres .
Python3
# importing pandas library from
# python
import pandas as pd
# Creating data
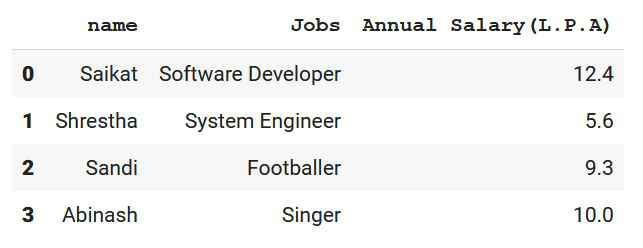
Information = {'name': ["Saikat", "Shrestha", "Sandi", "Abinash"],
'Jobs': ["Software Developer", "System Engineer",
"Footballer", "Singer"],
'Annual Salary(L.P.A)': [12.4, 5.6, 9.3, 10]}
# Dataframing the whole data
df = pd.DataFrame(dict)
# Showing the above data
print(df)
Producción:
Ahora usando MultiIndex.from_frame, estamos creando múltiples índices con este marco de datos.
Python3
# creating multiple indexes from # the dataframe pd.MultiIndex.from_frame(df)
Producción:

Ejemplo 3:
En este ejemplo, aprenderemos sobre dataframe.set_index([col1,col2,..]), donde aprenderemos sobre múltiples índices. Este es otro concepto de índice múltiple.
Después de importar la biblioteca requerida, es decir, pandas, estamos creando datos y luego, con la ayuda de pandas.DataFrame , los estamos convirtiendo a un formato tabular. Después de eso, usando Dataframe.set_index , estamos configurando algunas columnas como columnas de índice (Índice múltiple). El parámetro de eliminación se mantiene como falso, lo que no eliminará las columnas mencionadas como columna de índice y, a partir de entonces, el parámetro de adición se usa para agregar columnas pasadas a las columnas de índice ya existentes.
Python3
# importing the pandas library
import pandas as pd
# making data for dataframing
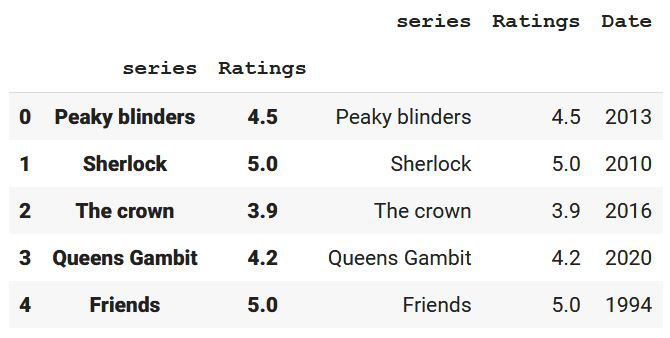
data = {
'series': ['Peaky blinders', 'Sherlock', 'The crown',
'Queens Gambit', 'Friends'],
'Ratings': [4.5, 5, 3.9, 4.2, 5],
'Date': [2013, 2010, 2016, 2020, 1994]
}
# Dataframing the whole data created
df = pd.DataFrame(data)
# setting first and the second name
# as index column
df.set_index(["series", "Ratings"], inplace=True,
append=True, drop=False)
# display the dataframe
print(df)
Producción:
Ahora, estamos imprimiendo el índice del marco de datos en forma de índice múltiple.
Python3
print(df.index)
Producción:

Agrupar por
Una operación groupby en Pandas nos ayuda a dividir el objeto aplicando una función y luego combinar los resultados. Después de agrupar las columnas según nuestra elección, podemos realizar varias operaciones que eventualmente nos pueden ayudar en el análisis de los datos.
Sintaxis: DataFrame.groupby(by=Ninguno, eje=0, nivel=Ninguno, as_index=Verdadero, sort=Verdadero, group_keys=Verdadero, squeeze=<objeto objeto>, observado=Falso, dropna=Verdadero)
- by: Nos ayuda a agrupar por columnas específicas o múltiples en el marco de datos.
- eje : tiene un valor predeterminado de 0, donde 0 representa el índice y 1 representa las columnas.
- level: Consideremos que el dataframe con el que estamos trabajando tiene indexación jerárquica. En ese caso level nos ayuda a determinar el nivel del índice con el que estamos trabajando.
- as_index: es un tipo de datos booleano con valor predeterminado como verdadero . Devuelve un objeto con etiquetas de grupo como índice.
- sort: Nos ayuda a ordenar los valores clave. Es preferible mantenerlo como falso para un mejor rendimiento.
- group_keys: también es un valor booleano con valor predeterminado como verdadero. Agrega claves de grupo a los índices para identificar piezas.
- dropna : ayuda a eliminar los valores ‘ NA ‘ en un conjunto de datos
Ejemplo 1:
En el siguiente ejemplo, exploraremos los conceptos de groupby utilizando datos creados por nosotros. Pasemos a la implementación del código.
Python3
# importing pandas library
import numpy as np
# Creating pandas dataframe
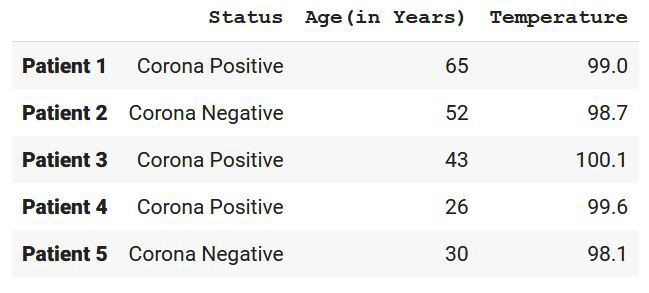
df = pd.DataFrame(
[
("Corona Positive", 65, 99),
("Corona Negative", 52, 98.7),
("Corona Positive", 43, 100.1),
("Corona Positive", 26, 99.6),
("Corona Negative", 30, 98.1),
],
index=["Patient 1", "Patient 2", "Patient 3",
"Patient 4", "Patient 5"],
columns=("Status", "Age(in Years)", "Temperature"),
)
# show dataframe
print(df)
Producción:
Ahora vamos a agruparlos según algunas características:
Python3
# Grouping with only status
grouped1 = df.groupby("Status")
# Grouping with temperature and status
grouped3 = df.groupby(["Temperature", "Status"])
Como vemos, los hemos agrupado según ‘ Estado ‘ y ‘ Temperatura y Estado ‘. Vamos a realizar algunas funciones ahora:
Python3
# Finding the mean of the # patients reports according to # the status grouped1.mean()
Esto creará la media de los valores numéricos según el ‘ estado ‘.
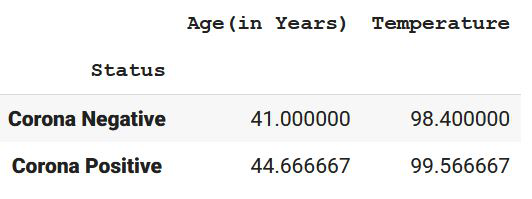
Python3
# Grouping temperature and status together # results in giving us the index values of # the particular patient grouped3.groups
Producción:
{(98.1, ‘Corona Negativo’): [‘Paciente 5’], (98.7, ‘Corona Negativo’): [‘Paciente 2’],
(99.0, ‘Corona positiva’): [‘Paciente 1’], (99.6, ‘Corona positiva’): [‘Paciente 4’],
(100.1, ‘Corona positiva’): [‘Paciente 3’]}