Requisito previo: Hadoop y HDFS
Snakebite es un paquete de python muy popular que permite a los usuarios acceder a HDFS usando algún tipo de programa con la aplicación python. El paquete Snakebite Python está desarrollado por Spotify. Snakebite también proporciona una biblioteca cliente de Python. Los mensajes de protobuf son utilizados por la biblioteca del cliente de mordedura de serpiente para comunicarse directamente con el NameNode que almacena todos los metadatos. Todos los permisos de archivo, registros, ubicación donde se crean los bloques de datos, todo se incluye en los metadatos. La CLI, es decir, la interfaz de línea de comandos, también está disponible en este paquete de Python de mordedura de serpiente que se basa en la biblioteca del cliente.
Analicemos cómo instalar y configurar el paquete Snakebite para HDFS.
Requisito:
- Se requiere Python 2 y python-protobuf 2.4.1 o superior para la mordedura de serpiente.
La biblioteca de mordedura de serpiente se puede instalar fácilmente con pip .
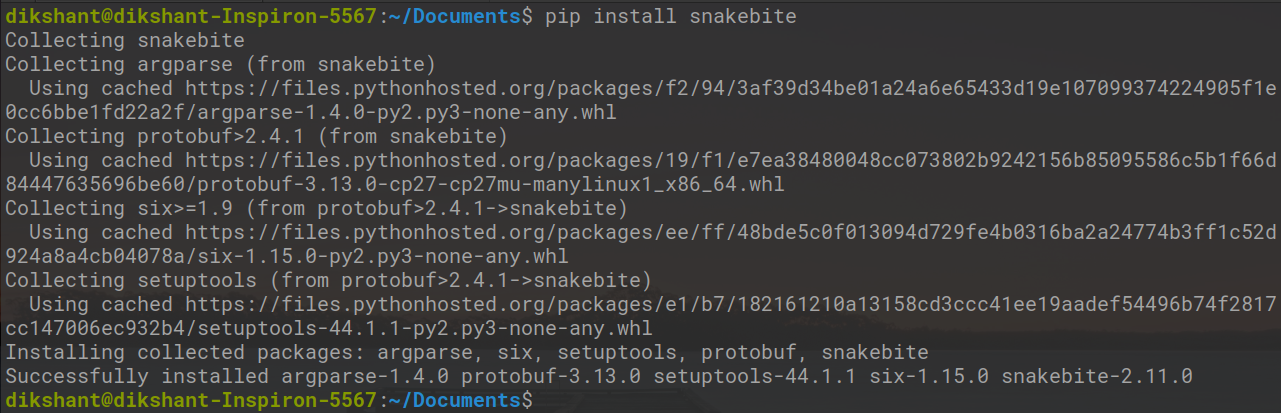
# Make sure you have pip for python version 2 otherwise you will face error while importing module pip install snakebite
Ya tenemos mordedura de serpiente por lo que se cumple el requisito.
La biblioteca del cliente
La biblioteca del cliente está construida usando python y usa el protocolo Hadoop RPC y mensajes protobuf para comunicarse con el NameNode que maneja todos los metadatos del clúster. Con la ayuda de esta biblioteca cliente, las aplicaciones de Python se comunican directamente con HDFS, es decir, el sistema de archivos distribuidos de Hadoop, sin establecer ninguna conexión con hdfs dfs mediante una llamada al sistema.
Escribamos un programa de python simple para comprender el funcionamiento del paquete de python de mordedura de serpiente.
Tarea: Enumere todo el contenido del directorio raíz de HDFS utilizando la biblioteca del cliente Snakebite.
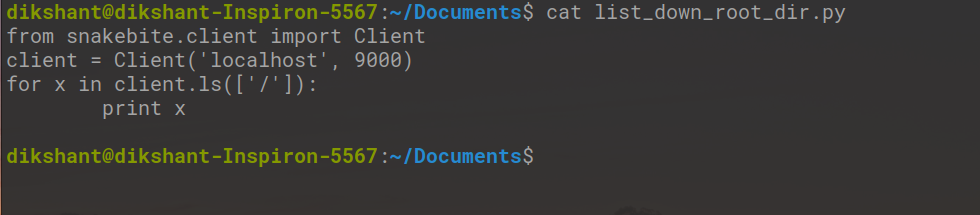
Paso 1: Cree un archivo python con el nombre list_down_root_dir.py en la ubicación deseada en el sistema.
cd Documents/ # Changing directory to Documents(You can choose as per your requirement) touchlist_down_root_dir.py # touch command is used to create file in linux enviournment.

Paso 2: Escriba el siguiente código en el archivo python list_down_root_dir.py .
Python
# importing the package
from snakebite.client import Client
# the below line create client connection to the HDFS NameNode
client = Client('localhost', 9000)
# the loop iterate in root directory to list all the content
for x in client.ls(['/']):
print x
Explicación del método Client():
El método Client() puede aceptar todos los argumentos enumerados a continuación:
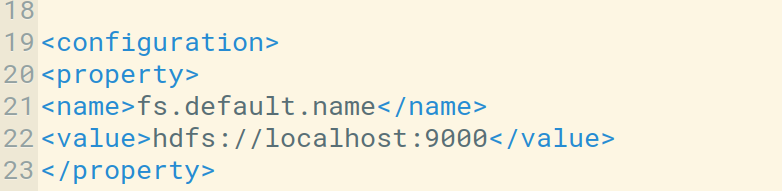
- host (string): dirección IP de NameNode.
- port(int): puerto RPC de Namenode.
Podemos verificar el host y el puerto predeterminado en el archivo core-site.xml . También podemos configurarlo según nuestro uso.
- hadoop_version (int): versión del protocolo Hadoop (por defecto es: 9)
- use_trash (booleano): use la papelera al eliminar los archivos.
- uso_efectivo (string): usuario efectivo para las operaciones de HDFS (el usuario predeterminado es el usuario actual).
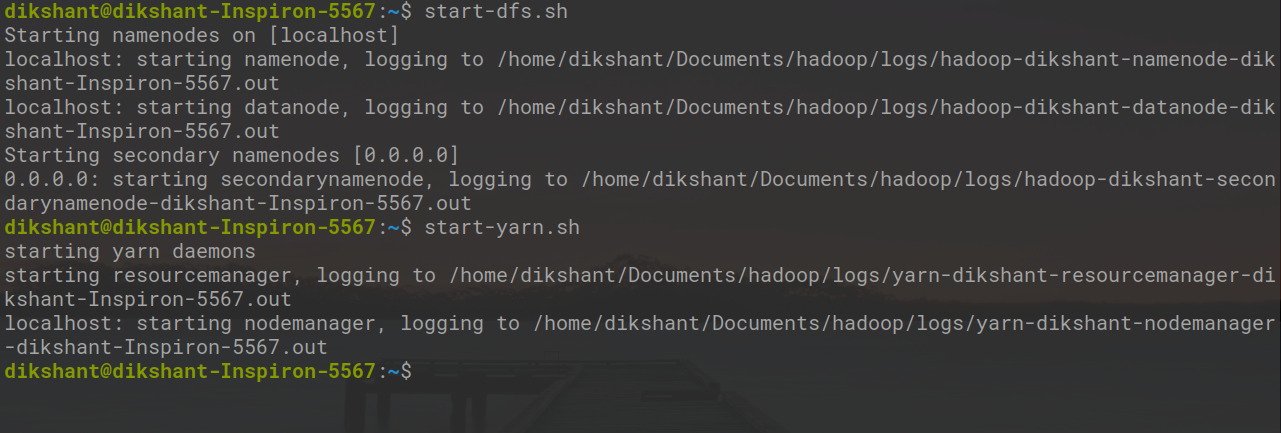
Paso 3: Inicie Hadoop Daemon con el siguiente comando .
start-dfs.sh // start your namenode datanode and secondary namenode start-yarn.sh // start resourcemanager and nodemanager
Paso 4: Ejecute el archivo list_down_root_dir.py y observe el resultado.
python list_down_root_dir.py
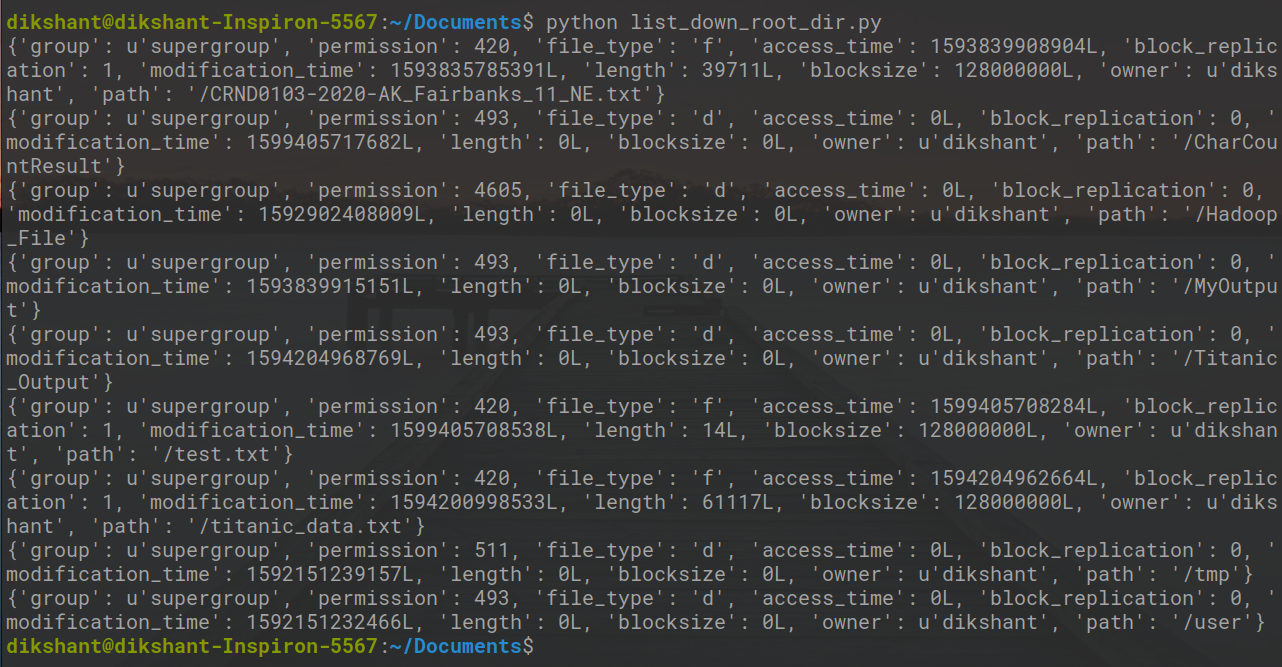
En la imagen de arriba, puede ver todo el contenido que está disponible en el directorio raíz de mi HDFS.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA