Prerrequisito: Introducción a la computación en paralelo
El paralelismo de nivel de instrucción (ILP) se utiliza para referirse a la arquitectura en la que se pueden realizar múltiples operaciones en paralelo en un proceso particular, con su propio conjunto de recursos: espacio de direcciones, registros, identificadores, estado, contadores de programa. Se refiere a las técnicas de diseño de compiladores y procesadores diseñados para ejecutar operaciones, como carga y almacenamiento de memoria, suma de enteros, multiplicación flotante, en paralelo para mejorar el rendimiento de los procesadores. Ejemplos de arquitecturas que explotan ILP son VLIWs, Superscalar Architecture.
Los procesadores ILP tienen el mismo hardware de ejecución que los procesadores RISC . Las máquinas sin ILP tienen un hardware complejo que es difícil de implementar. Un ILP típico permite canalizar operaciones de ciclos múltiples.
Ejemplo:
suponga que se pueden realizar 4 operaciones en un solo ciclo de reloj. Por lo tanto, habrá 4 unidades funcionales, cada una adjunta a una de las operaciones, la unidad de sucursal y el archivo de registro común en el hardware de ejecución de ILP. Las suboperaciones que pueden realizar las unidades funcionales son ALU de enteros, multiplicación de enteros, operaciones de punto flotante, carga, almacenamiento. Sean las latencias respectivas 1, 2, 3, 2, 1.
Sea la secuencia de instrucciones:
- y1 = x1*1010
- y2 = x2*1100
- z1 = y1+0010
- z2 = y2+0101
- t1 = t1+1
- p = q*1000
- clr = clr+0010
- r = r+0001
Registro secuencial de ejecución frente a nivel de instrucción Registro paralelo de ejecución:
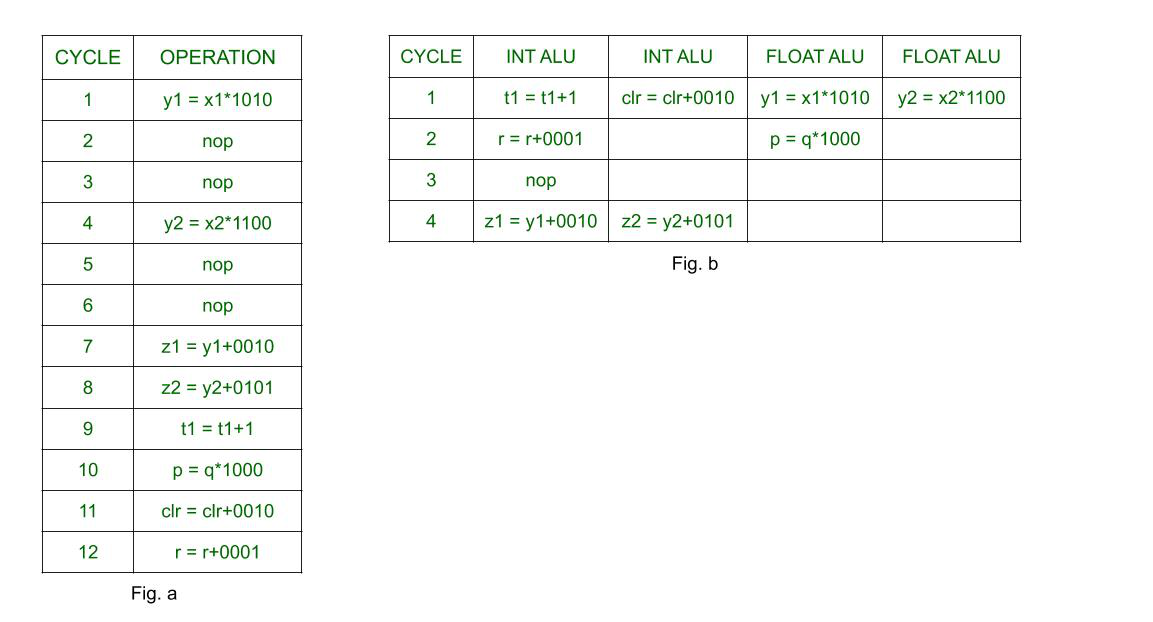
La figura a muestra la ejecución secuencial de operaciones.
La Fig. b muestra el uso de ILP para mejorar el rendimiento del procesador.
Los «nop» o «sin operaciones» en el diagrama anterior se utilizan para mostrar el tiempo de inactividad del procesador. Dado que la latencia de las operaciones de punto flotante es 3, las multiplicaciones toman 3 ciclos y el procesador debe permanecer inactivo durante ese período de tiempo. Sin embargo, en la Fig. b, el procesador puede utilizar esos nop para ejecutar otras operaciones mientras se siguen ejecutando las anteriores.
Mientras que en ejecución secuencial, cada ciclo tiene una sola operación en ejecución, en procesador con ILP, el ciclo 1 tiene 4 operaciones, el ciclo 2 tiene 2 operaciones. En el ciclo 3 hay ‘nop’ ya que las siguientes dos operaciones dependen de las dos primeras operaciones de multiplicación. El procesador secuencial tarda 12 ciclos en ejecutar 8 operaciones, mientras que el procesador con ILP tarda solo 4 ciclos.
Arquitectura:
el paralelismo de nivel de instrucción se logra cuando se realizan múltiples operaciones en un solo ciclo, ya sea ejecutándolas simultáneamente o utilizando espacios entre dos operaciones sucesivas que se crean debido a las latencias.
Ahora, la decisión de cuándo ejecutar una operación depende en gran medida del compilador más que del hardware. Sin embargo, el alcance del control del compilador depende del tipo de arquitectura ILP donde varía la información sobre el paralelismo proporcionado por el compilador al hardware a través del programa. La clasificación de las arquitecturas ILP se puede hacer de las siguientes maneras:
- Arquitectura secuencial:
aquí, no se espera que el programa transmita explícitamente ninguna información sobre el paralelismo al hardware, como la arquitectura superescalar. - Arquitecturas de dependencia:
aquí, el programa menciona explícitamente información sobre dependencias entre operaciones como la arquitectura de flujo de datos. - Arquitectura de independencia:
aquí, el programa brinda información sobre qué operaciones son independientes entre sí para que puedan ejecutarse en lugar de los ‘nop’.
Para aplicar ILP, el compilador y el hardware deben determinar las dependencias de datos, las operaciones independientes y la programación de estas operaciones independientes, la asignación de unidades funcionales y el registro para almacenar datos.
Publicación traducida automáticamente
Artículo escrito por srishtiganguly1999 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA