Prerrequisito: Gráficos relacionales en Seaborn – Parte I
En la parte anterior de este artículo, aprendimos sobre el relplot(). Ahora, leeremos sobre los otros dos diagramas relacionales, a saber, el diagrama de dispersión() y el diagrama de líneas() proporcionados en la biblioteca Seaborn. Ambos gráficos también se pueden dibujar con la ayuda del parámetro kind en relplot(). Básicamente, relplot(), por defecto, solo nos da scatterplot(), y si le pasamos el parámetro kind = “line” , nos da lineplot().
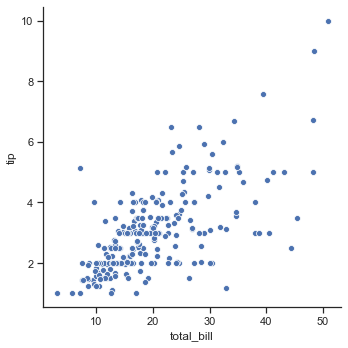
Ejemplo 1: uso de relplot() para visualizar un conjunto de datos de sugerencias
Python3
import seaborn as sns
sns.set(style ="ticks")
tips = sns.load_dataset('tips')
sns.relplot(x ="total_bill", y ="tip", data = tips)
Producción :
Ejemplo 2: Usar relplot() con kind=”scatter”.
Python3
import seaborn as sns
sns.set(style ="ticks")
tips = sns.load_dataset('tips')
sns.relplot(x ="total_bill",
y ="tip",
kind ="scatter",
data = tips)
Producción :
Ejemplo 3: Usar relplot() con kind=”line”.
Python3
import seaborn as sns
sns.set(style ="ticks")
tips = sns.load_dataset('tips')
sns.relplot(x ="total_bill",
y ="tip",
kind ="line",
data = tips)
Producción :

Aunque ambos gráficos se pueden dibujar usando relplot(), seaborn también tiene funciones separadas para visualizar este tipo de gráficos. Estas funciones también proporcionan otras funcionalidades, en comparación con relplot(). Discutamos sobre estas funciones con más detalle:
Seaborn.diagrama de dispersión()
El diagrama de dispersión es un pilar de la visualización estadística. Representa la distribución conjunta de dos variables usando una nube de puntos, donde cada punto representa una observación en el conjunto de datos. Esta representación permite al ojo inferir una cantidad sustancial de información sobre si existe alguna relación significativa entre ellos.
Sintaxis:
seaborn.scatterplot(x=None, y=None, data=None, **kwargs)
Parámetros:
| Parámetro | Valor | Usar |
|---|---|---|
| x, y | numérico | Variables de datos de entrada |
| datos | Marco de datos | Conjunto de datos que se está utilizando. |
| tono, tamaño, estilo | nombre en datos; opcional | Variable de agrupación que producirá elementos con diferentes colores. |
| paleta | nombre, lista o dictado; opcional | Colores a utilizar para los diferentes niveles de la variable matiz. |
| tono_orden | lista; opcional | Orden especificado para la aparición de los niveles de la variable de matiz. |
| tono_norma | tupla o Normalizar objeto; opcional | Normalización en unidades de datos para mapa de colores aplicado a la variable matiz cuando es numérica. |
| tamaños | lista, dictado o tupla; opcional | determina el tamaño de cada punto en el gráfico. |
| tamaño_pedido | lista; opcional | Orden especificado para la aparición de los niveles de la variable de tamaño |
| tamaño_norma | tupla o Normalizar objeto; opcional | Normalización en unidades de datos para escalar objetos de trazado cuando la variable de tamaño es numérica. |
| marcadores | booleano, lista o diccionario; opcional | objeto que determina la forma del marcador para cada punto de datos. |
| estilo_orden | lista; opcional | Orden especificado para la aparición de los niveles de variables de estilo |
| alfa | flotar | opacidad proporcional de los puntos. |
| leyenda | “breve”, “completo” o Falso; opcional | Si es «breve», las variables numéricas de tono y tamaño se representarán con una muestra de valores espaciados uniformemente. Si está «lleno», cada grupo obtendrá una entrada en la leyenda. Si es False, no se agregan datos de leyenda y no se dibuja ninguna leyenda. |
| hacha | ejes matplotlib; opcional | Objeto de ejes en el que se va a dibujar el gráfico. |
| kwargs | pares de clave y valor | Otros argumentos de palabras clave se pasan a la función de trazado subyacente. |
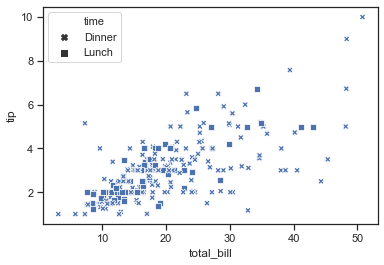
Ejemplo 1: Trazar un diagrama de dispersión usando un marcador para diferenciar entre los horarios de las personas que visitan el restaurante.
Python3
import seaborn as sns
sns.set(style ="ticks")
tips = sns.load_dataset('tips')
markers = {"Lunch": "s", "Dinner": "X"}
ax = sns.scatterplot(x ="total_bill",
y ="tip",
style ="time",
markers = markers,
data = tips)
Producción:
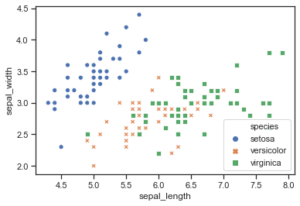
Ejemplo 2: pasar vectores de datos en lugar de nombres en un marco de datos.
Python3
import seaborn as sns
iris = sns.load_dataset("iris")
sns.scatterplot(x = iris.sepal_length,
y = iris.sepal_width,
hue = iris.species,
style = iris.species)
Producción:
Seaborn.lineplot()
Los diagramas de dispersión son muy efectivos, pero no existe un tipo de visualización universalmente óptimo. Para determinados conjuntos de datos, es posible que desee considerar los cambios como una función del tiempo en una variable o como una variable continua similar. En este caso, dibujar un gráfico de líneas es una mejor opción.
Sintaxis:
seaborn.lineplot(x=None, y=None, data=None, **kwargs)
Parámetros:
| Parámetro | Valor | Usar |
|---|---|---|
| x, y | numérico | Variables de datos de entrada |
| datos | Marco de datos | Conjunto de datos que se está utilizando. |
| tono, tamaño, estilo | nombre en datos; opcional | Variable de agrupación que producirá elementos con diferentes colores. |
| paleta | nombre, lista o dictado; opcional | Colores a utilizar para los diferentes niveles de la variable matiz. |
| tono_orden | lista; opcional | Orden especificado para la aparición de los niveles de la variable de matiz. |
| tono_norma | tupla o Normalizar objeto; opcional | Normalización en unidades de datos para mapa de colores aplicado a la variable matiz cuando es numérica. |
| tamaños | lista, dictado o tupla; opcional | determina el tamaño de cada punto en el gráfico. |
| tamaño_pedido | lista; opcional | Orden especificado para la aparición de los niveles de la variable de tamaño |
| tamaño_norma | tupla o Normalizar objeto; opcional | Normalización en unidades de datos para escalar objetos de trazado cuando la variable de tamaño es numérica. |
| marcadores, guiones | booleano, lista o diccionario; opcional | objeto que determina la forma del marcador para cada punto de datos. |
| estilo_orden | lista; opcional | Orden especificado para la aparición de los niveles de variables de estilo |
| unidades | long_form_var | Variable de agrupación que identifica las unidades de muestreo. Cuando se utilice, se dibujará una línea separada con la terminología correcta para cada unidad, pero no se insertará ninguna leyenda. Útil para mostrar la distribución de réplicas experimentales cuando las identidades exactas no son necesarias. |
| estimador | nombre del método pandas o invocable o Ninguno; opcional | Método para agregar el vector y en el mismo punto x a través de múltiples observaciones. Si es Ninguno, se extraerán todas las observaciones. |
| ci | int o “sd” o Ninguno; opcional | Tamaño del intervalo de confianza que se dibujará al agregar con un estimador. “sd” significa dibujar una desviación estándar. |
| n_boot | En t; opcional> | Número de bootstraps que se usarán para la medición del intervalo de confianza. |
| semilla | int, numpy.random.Generator o numpy.random.RandomState; opcional | Generador de semillas o números aleatorios para un arranque reproducible. |
| clasificar | bool; opcional | es True, ordena los datos. |
| err_estilo | “banda” o “barras”; opcional | Ya sea usando bandas de error translúcidas para mostrar los intervalos de confianza o barras de error discretas. |
| err_kws | dictado de argumentos de palabras clave | Parámetros adicionales para controlar la estética de las barras de error. |
| leyenda | “breve”, “completo” o Falso; opcional | Si es «breve», las variables numéricas de tono y tamaño se representarán con una muestra de valores espaciados uniformemente. Si está «lleno», cada grupo obtendrá una entrada en la leyenda. Si es False, no se agregan datos de leyenda y no se dibuja ninguna leyenda. |
| hacha | ejes matplotlib; opcional | Objeto de ejes en el que se va a dibujar el gráfico. |
| kwargs | pares de clave y valor | Otros argumentos de palabras clave se pasan a la función de trazado subyacente. |
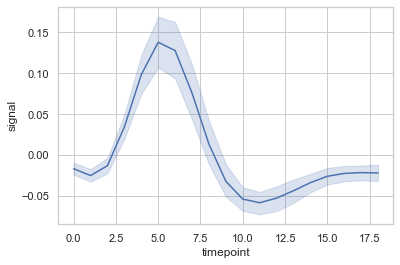
Ejemplo 1: Visualización básica del conjunto de datos «fmri» usando lineplot()
Python3
import seaborn as sns
sns.set(style = 'whitegrid')
fmri = sns.load_dataset("fmri")
sns.lineplot(x ="timepoint",
y ="signal",
data = fmri)
Producción :
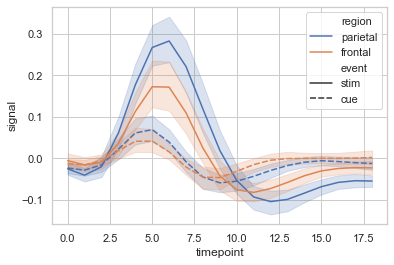
Ejemplo 2: Agrupación de puntos de datos en función de la categoría, aquí como región y evento.
Python3
import seaborn as sns
sns.set(style = 'whitegrid')
fmri = sns.load_dataset("fmri")
sns.lineplot(x ="timepoint",
y ="signal",
hue ="region",
style ="event",
data = fmri)
Producción :
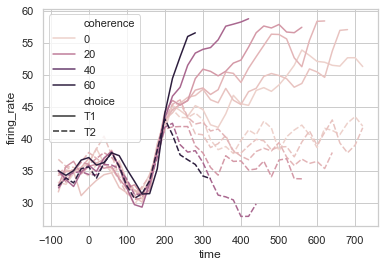
Ejemplo 3: Un gráfico complejo que visualiza un conjunto de datos de «puntos», para mostrar el poder de Seaborn. Aquí, en este ejemplo, se usa el mapeo de color cuantitativo.
Python3
import seaborn as sns
sns.set(style = 'whitegrid')
dots = sns.load_dataset("dots").query("align == 'dots'")
sns.lineplot(x ="time",
y ="firing_rate",
hue ="coherence",
style ="choice",
data = dots)
Producción :