- Definición de una gramática para analizar 3 tipos de frases.
- La clase ChunkRule que busca un determinante opcional seguido de uno o más sustantivos se usa para frases nominales.
- Para agregar un adjetivo al frente de un fragmento de sustantivo, se usa la clase MergeRule.
- Cualquier palabra IN simplemente se fragmenta para las frases preposicionales.
- una palabra modal opcional (como debería) seguida de un verbo se fragmenta para las frases verbales.
Código #1:
chunker = RegexpParser(r'''
NP:
# chunk optional determiner with nouns
{<DT>?<NN.*>+}
# merge adjective with noun chunk
<JJ>{}<NN.*>
PP:
# chunk preposition
{<IN>}
VP:
# chunk optional modal with verb
{<MD>?<VB.*>} ''')
from nltk.corpus import conll2000
score = chunker.evaluate(conll2000.chunked_sents())
print ("Accuracy : ", score.accuracy())
Producción :
Accuracy : 0.6148573545757688
El corpus treebank_chunk es una versión especial del corpus treebank y proporciona un método chunked_sents(). Debido a su formato de archivo, el corpus regular de treebank no puede proporcionar ese método.
Código #2: Usar treebank_chunk
from nltk.corpus import treebank_chunk
treebank_score = chunker.evaluate(
treebank_chunk.chunked_sents())
print ("Accuracy : ", treebank_score.accuracy()
Producción :
Accuracy : 0.49033970276008493
Chunk Score Metrices
Proporciona otras métricas además de la precisión. De los fragmentos,
la precisión significa cuántos fueron correctos.
Recordar significa qué tan bien lo hizo el fragmentador para encontrar los fragmentos correctos en comparación con el total de fragmentos que había. 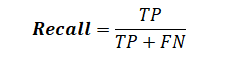
Código n.º 3: métricas de puntuación de fragmentos
print ("Precision : ", score.precision())
print ("\nRecall : ", score.recall())
print ("\nLength for missed one : ", len(score.missed()))
print ("\nLength for incorrect one : ", len(score.incorrect()))
print ("\nLength for correct one : ", len(score.correct()))
print ("\nLength for guessed one : ", len(score.guessed()))
Producción :
Precision : 0.60201948127375 Recall : 0.606072502505847 Length for missed one : 47161 Length for incorrect one : 47967 Length for correct one : 119720 Length for guessed one : 120526
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA