En este artículo, vamos a discutir por qué la iteración sobre un dict es tan lenta en Python. Antes de llegar a una conclusión, echemos un vistazo a la diferencia de rendimiento entre las arrays NumPy y los diccionarios en python:
Python
# import modules
import numpy as np
import sys
# compute numpy performance
def np_performance():
array = np.empty(100000000)
for i in range(100000000):
array[i] = i
print("SIZE : ",
sys.getsizeof(array)/1024.0**2,
"MiB")
# compute dictionary performance
def dict_performance():
dic = dict()
for i in range(100000000):
dic[i] = i
print("SIZE : ",
sys.getsizeof(dic)/1024.0**2,
"MiB")
En el script de Python anterior tenemos dos funciones:
- np_performance: esta función crea una array NumPy vacía para 10,00,000 elementos e itera sobre toda la array actualizando el valor del elemento individual a la ubicación del iterador (‘i’ en este caso)
- dict_performance: esta función crea un diccionario vacío para 10,00,000 elementos e itera sobre todo el diccionario actualizando el valor del elemento individual a la ubicación del iterador (‘i’ en este caso)
Y finalmente, una llamada a la función sys.getsizeof() para calcular el uso de la memoria por las estructuras de datos respectivas.
Ahora llamamos a estas dos funciones, y para medir el tiempo que tarda cada función usamos la función %time que nos da el tiempo de ejecución de una declaración o expresión de Python. La función %time se puede utilizar tanto como magia de línea como de celda:
- En el modo en línea, puede cronometrar una declaración de una sola línea (aunque se pueden enstringr varias usando punto y coma).
- En el modo de celda, puede cronometrar el cuerpo de la celda (una declaración que sigue directamente genera un error).
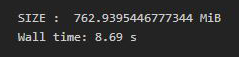
Llamar a estas funciones desde el modo en línea usando el método %time:
Python3
# compute time taken %time np_performance()
Producción:
Python3
# compute time taken %time dict_performance()
Producción:
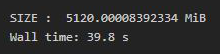
Como podemos ver, hay una gran diferencia en el tiempo de Wall entre iterar en una array NumPy y un diccionario de Python.
- Esta diferencia en el rendimiento se debe a las diferencias internas de trabajo entre las arrays y los diccionarios, ya que después de Python 3.6 , los diccionarios en python se basan en un híbrido de HashTables y una array de elementos. Entonces, cada vez que sacamos/eliminamos una entrada del diccionario, en lugar de eliminar una clave de esa ubicación en particular, permite que la siguiente clave sea reemplazada por la posición de la clave eliminada. Lo que hace el diccionario de Python es reemplazar el valor de la array hash con un valor ficticio que representa nulo. Entonces, al atravesar cuando encuentra estos valores nulos ficticios, continúa iterando hasta que encuentra la siguiente clave con valor real.
- Dado que puede haber muchos espacios vacíos, atravesaremos sin ningún beneficio real y, por lo tanto, los diccionarios son generalmente más lentos que sus contrapartes de array/lista.
- Para conjuntos de datos de gran tamaño, el acceso a la memoria sería el cuello de botella. Los diccionarios son mutables y ocupan más memoria que las arrays o las tuplas (nombradas) (cuando se organizan de manera eficiente, sin duplicar la información de tipo).
Publicación traducida automáticamente
Artículo escrito por devashish_ y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA