PostgreSQL tiene está usando la instrucción DELETE USING.
Syntax: DELETE FROM table_name row1 USING table_name row2 WHERE condition;
Para fines de demostración, configuremos una tabla de muestra (por ejemplo, una canasta ) que almacene frutas de la siguiente manera:
CREATE TABLE basket(
id SERIAL PRIMARY KEY,
fruit VARCHAR(50) NOT NULL
);
Ahora agreguemos algunos datos a la tabla de cesta recién creada.
INSERT INTO basket(fruit) values('apple');
INSERT INTO basket(fruit) values('apple');
INSERT INTO basket(fruit) values('orange');
INSERT INTO basket(fruit) values('orange');
INSERT INTO basket(fruit) values('orange');
INSERT INTO basket(fruit) values('banana');
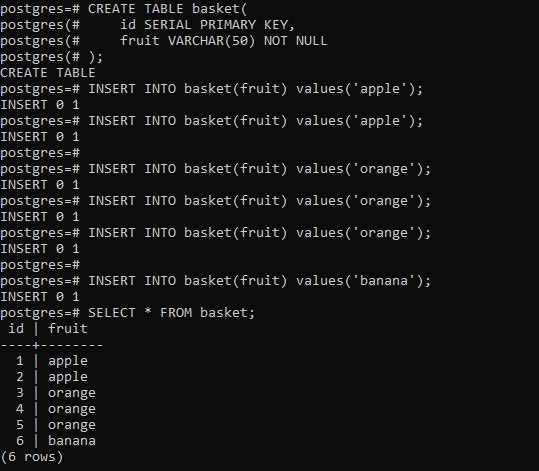
Ahora verifiquemos la tabla de la canasta usando la siguiente declaración:
SELECT * FROM basket;
Esto debería resultar en lo siguiente:
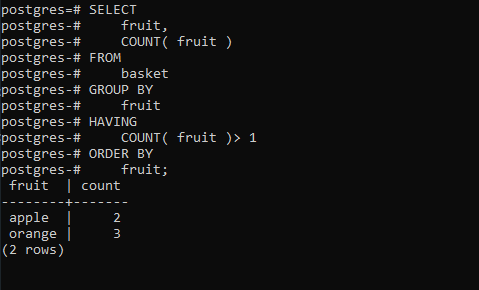
Ahora que hemos configurado la tabla de muestra, buscaremos los duplicados usando lo siguiente:
SELECT
fruit,
COUNT( fruit )
FROM
basket
GROUP BY
fruit
HAVING
COUNT( fruit )> 1
ORDER BY
fruit;
Esto debería conducir a los siguientes resultados:
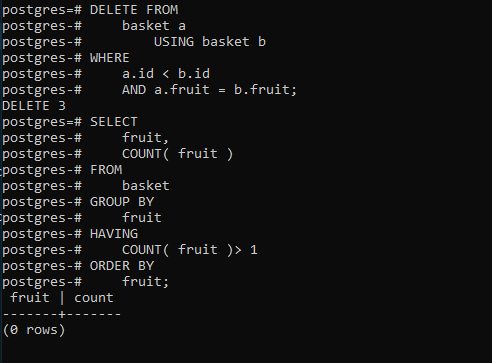
Ahora que conocemos las filas duplicadas, podemos usar DELETE USINGfollows
DELETE FROM
basket a
USING basket b
WHERE
a.id < b.id
AND a.fruit = b.fruit;
Esto debería eliminar todos los duplicados de la cesta de la mesa y, para verificarlo, utilice la siguiente consulta:
SELECT
fruit,
COUNT( fruit )
FROM
basket
GROUP BY
fruit
HAVING
COUNT( fruit )> 1
ORDER BY
fruit;
Esto debería resultar en lo siguiente:
Publicación traducida automáticamente
Artículo escrito por RajuKumar19 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA