En algún momento de la década de 2000, los desarrolladores de PostgreSQL encontraron una laguna importante en el diseño de su sistema de gestión de bases de datos relacionales con respecto al espacio de almacenamiento y la velocidad de las transacciones. Resultó que la consulta ACTUALIZAR se estaba convirtiendo en una rutina costosa. ACTUALIZAR estaba duplicando la fila anterior y reescribiendo nuevos datos, lo que significaba que el tamaño de la base de datos o las tablas no estaban sujetos a ningún límite. Además, la eliminación de una fila solo MARCÓ la fila eliminada mientras que los datos reales permanecieron intactos; el análisis forense de datos se admitió más adelante.
Esto puede sonar familiar, ya que es en lo que se basan los sistemas de archivos y el software de recuperación de datos actuales, es decir, los datos, cuando se eliminan, permanecen intactos en el disco magnético en su forma original, pero se ocultan en la interfaz. Sin embargo, mantener los datos antiguos también era importante para las transacciones más antiguas. Entonces, técnicamente, no era correcto comprometer la integridad transaccional. Siendo este un estímulo suficiente, el equipo de Postgres pronto introdujo la característica de ‘vacío’ que literalmente aspiraba las filas eliminadas. Sin embargo, este era un proceso manual y debido a los varios parámetros involucrados en la función, no era deseable. Por lo tanto, se desarrolló el autovacío.
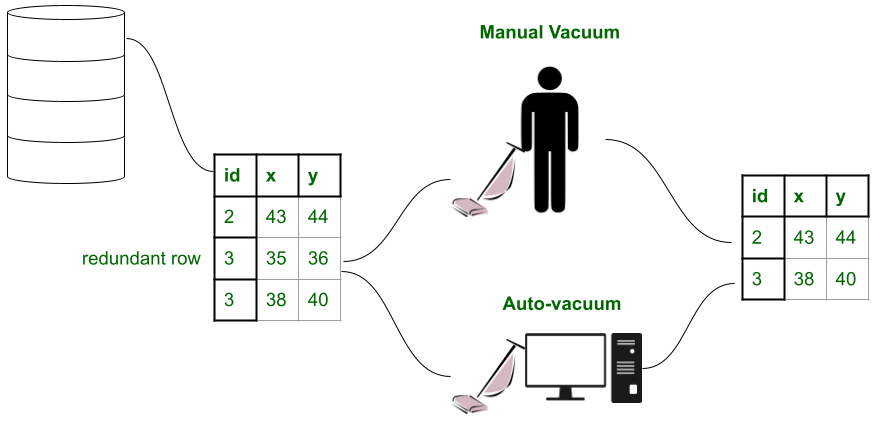
¿Qué es el Autovacío?
Autovacuum es un demonio o proceso de utilidad en segundo plano ofrecido por PostgreSQL a los usuarios para realizar una limpieza regular de datos redundantes en la base de datos y el servidor. No requiere que el usuario emita manualmente el vaciado y, en su lugar, se define en el archivo postgresql.conf . Para acceder a este archivo, simplemente diríjase al siguiente directorio en su terminal y luego abra el archivo en un editor adecuado.
>> cd C:\Program Files\PostgreSQL\13\data >> "postgresql.conf"
Cuando se implementa en el símbolo del sistema:

La utilidad autovacuum reasigna el bloque de datos eliminado (bloques que se marcaron como eliminados) a nuevas transacciones eliminando primero las tuplas muertas/obsoletas y luego informando a las transacciones en cola dónde se pueden colocar actualizaciones o inserciones en la tabla. Esto contrasta marcadamente con el procedimiento antiguo y anterior en el que una transacción insertaría ciegamente una nueva fila de datos con los mismos elementos de identificación y atributos actualizados. Los beneficios de la autoaspiración son bastante evidentes:
- El espacio de almacenamiento está bien utilizado.
- Se ha mejorado la visibilidad del mapa de espacio libre. Un FSM es un mapa de múltiples árboles binarios que indican los espacios disponibles en las relaciones/tablas.
- A diferencia de las aspiradoras manuales, no requieren mucho tiempo ni recursos.
- No colocan bloqueos exclusivos en las tablas (las aspiradoras FULL colocan bloqueos en las transacciones que desean acceder a las tablas).
- Se previene la hinchazón de la mesa. La hinchazón es un proceso por el cual el tamaño de una tabla alcanza valores enormes con datos innecesarios e inválidos.
Una forma de monitorear el tamaño de los datos antes y después de las transacciones es simplemente ejecutando las siguientes líneas de código en el Shell después de conectarse a una base de datos específica:
postgresql=# SELECT pg_size_pretty(pg_relation_size('table_name');
Considere una tabla que almacena las cuentas de los clientes en una cabina de peaje:
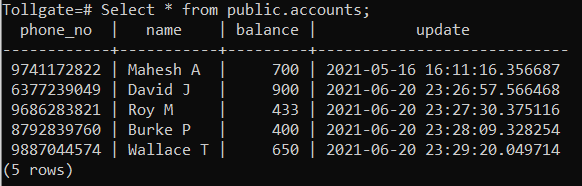
El tamaño de esta tabla entonces viene dado por:

Si se producen transacciones, esta consulta se puede realizar nuevamente para demostrar el cambio en el tamaño de la tabla. Los cambios desproporcionados en el tamaño sugerirían un autovacío fallido (si el tamaño no cambia aunque las transacciones no tengan ningún uso para el estado obsoleto de las filas).
Configuración de vacío automático
Dado que autovacuum es una utilidad en segundo plano, está activada de forma predeterminada. Sin embargo, tenga en cuenta que se desarrolló hace bastante tiempo y, por lo tanto, los parámetros establecidos fueron conservadores, es decir, los parámetros se establecieron de acuerdo con la disponibilidad del hardware y la versión del software. Las aplicaciones modernas exigen revisar estos parámetros y ajustarlos proporcionalmente. Echaremos un vistazo rápido a los parámetros nodales:

La sección AUTOVACUUM en el archivo postgresql.conf.
- autovacuum: está configurado en ‘on’ de forma predeterminada, por lo que no se puede declarar exclusivamente en el shell o terminal.
- autovacuum_naptime: este parámetro se establece en 1 min o 60 s, lo que indica la duración entre llamadas o despertares de autovacuum consecutivos.
- autovacuum_max_workers: esto indica la cantidad de procesos que se aspiran cada vez que la función se activa después de la «hora de la siesta».
- autovacuum_vacuum_scale_factor: generalmente establecido en 0.2, significa que autovacuum realiza una limpieza solo si el 20% de la relación/tabla ha sido modificada/actualizada.
- autovacuum_vacuum_threshold: como medida de precaución, este parámetro garantiza que el autovacuuming ocurra solo si se realiza un número determinado de cambios en la tabla (50 de forma predeterminada).
- autovacuum_analyze_scale_factor: esta es la utilidad de análisis que crea estadísticas periódicas de las tablas durante las transacciones. Si se establece en 0.1, el análisis se realiza solo si el 10 % de la tabla observa actualizaciones (eliminaciones, actualizaciones, inserciones, alteraciones, etc.).
- autovacuum_analyze_threshold: similar a autovacuum_vacuum_threshold, aunque aquí la acción que se realiza es de análisis. El análisis se realiza solo si las transacciones han realizado un mínimo de 50 cambios.
Estos parámetros se modifican en función de la frecuencia con la que las transacciones afectan a la base de datos y el tamaño de la base de datos o el crecimiento esperado. Por lo tanto, si las transacciones parecen estar ocurriendo a tasas más rápidas, se puede aumentar autovacuum_max_workers o se puede disminuir autovacuum_vacuum_scale_factor si no se espera que las transacciones exijan datos más antiguos . Además, el desarrollador puede ajustar los parámetros de análisis para formular mejores técnicas de consulta.
Esto nos lleva a cuestionar la idea detrás del análisis de tablas con tanta frecuencia.
¿Qué tablas requieren análisis?
El análisis se puede realizar manualmente o simplemente manteniendo activado el autovacío. El análisis proporciona información estadística específica sobre la base de datos que ayuda a los desarrolladores a mejorar la eficiencia. Esencialmente, el análisis proporciona la siguiente información:
- Una lista de los valores más comunes en una columna específica de una relación/tabla. En algunos casos, esto no es necesario ya que la columna puede ser el identificador único; no se puede esperar que los identificadores únicos se repitan en una tabla.
- Un histograma de la distribución de datos. Esto puede incluir los tamaños de los datos correspondientes a las columnas o qué columnas están sujetas a las actualizaciones más altas y más bajas de las transacciones.
Ahora respondiendo la pregunta pertinente: qué tablas realmente requieren análisis. Mediante autovacío, la mayoría de las tablas se someten a análisis. Sin embargo, en el caso probable de que se emita la función ANALIZAR explícita, se hace por las siguientes razones:
- Se usa cuando las actividades de ACTUALIZACIÓN no parecen afectar directamente a ciertas columnas. Puede suceder que se requieran las estadísticas de ciertas columnas que no se modifican por las transacciones en curso. Por lo tanto, el análisis automático puede ser insignificante.
- El análisis puede ser importante para controlar las tablas en las que la velocidad a la que se producen las actualizaciones es relevante.
- Comprender qué aspectos de los datos son menos propensos a cambios para establecer un patrón.
Otra pregunta más que puede plantearse es: ¿Cómo preseleccionar tablas en las que el demonio de análisis debe emitirse por separado?
Existe una regla general simple: el análisis en tablas tiene sentido siempre que los valores mínimos o máximos de las columnas sean propensos a cambios. Por ejemplo, una tabla que muestra las velocidades de los vehículos medidos por una pistola de velocidad seguramente cambiará sus valores máximos. Por lo tanto, el análisis arrojará algo concluyente.

Publicación traducida automáticamente
Artículo escrito por siddhant_baroth y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA