Usamos el aprendizaje profundo para los grandes conjuntos de datos, pero para comprender el concepto de aprendizaje profundo, usamos el pequeño conjunto de datos de calidad del vino. Puede encontrar el conjunto de datos de calidad del vino en el Repositorio de aprendizaje automático de UCI, que está disponible de forma gratuita. El objetivo de este artículo es comenzar con las bibliotecas de aprendizaje profundo como Keras, etc. y familiarizarse con la base de la red neuronal.
Acerca del conjunto de datos:
antes de comenzar a cargar los datos, es muy importante conocer sus datos. El conjunto de datos consta de 12 variables que se incluyen en los datos. Algunos de ellos son los siguientes:
- Acidez fija: La acidez total se divide en dos grupos: los ácidos volátiles y los ácidos no volátiles o fijos . El valor de esta variable se representa en gm/dm3 en los conjuntos de datos.
- Acidez volátil: La acidez volátil es un proceso en el que el vino se convierte en vinagre. En estos conjuntos de datos, la acidez volátil se expresa en gm/dm3.
- Ácido cítrico: El ácido cítrico es uno de los ácidos fijos en los vinos. Se expresa en g/dm3 en los conjuntos de datos.
- Azúcar residual: El azúcar residual es el azúcar que queda después de que se detiene o se detiene la fermentación. Se expresa en g/dm3 en el conjunto de datos.
- Cloruros: Puede ser un contribuyente importante a la salinidad en el vino. El valor de esta variable se representa en gm/dm3 en los conjuntos de datos.
- Anhídrido sulfuroso libre: Es la parte del anhídrido sulfuroso que se añade a un vino. El valor de esta variable se representa en gm/dm3 en los conjuntos de datos.
- Dirust de azufre total: Es la suma del dirust de azufre ligado y libre. El valor de esta variable se representa en gm/dm3 en los conjuntos de datos.
Paso #1: Conozca sus datos.
Cargando los datos.
Python3
# Import Required Libraries
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# Read in white wine data
white = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep =';')
# Read in red wine data
red = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep =';')
Primeras filas de `rojo`.
Python3
# First rows of `red` red.head()
Producción:

Últimas filas de `blanco`.
Python3
# Last rows of `white` white.tail()
Producción:

Tome una muestra de cinco filas de `rojo`.
Python3
# Take a sample of five rows of `red` red.sample(5)
Producción:

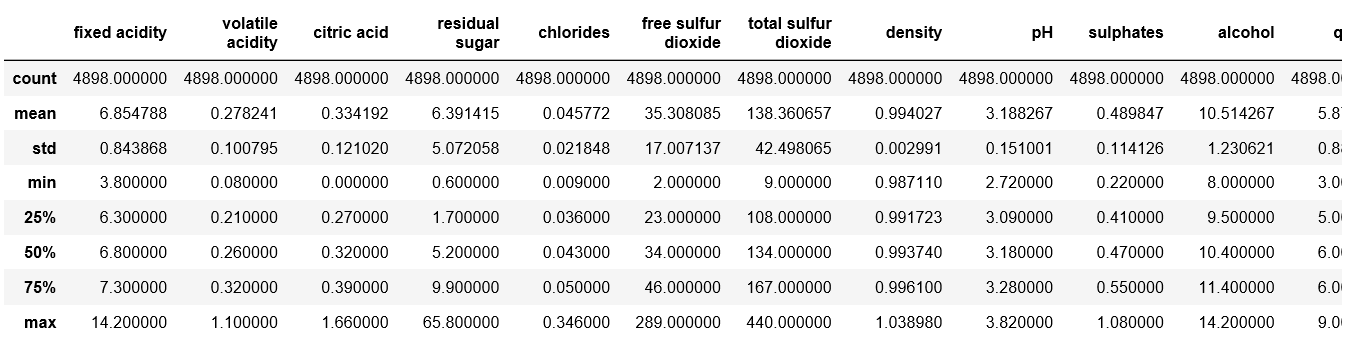
Descripción de datos –
Python3
# Describe `white` white.describe()
Producción:
Compruebe si hay valores nulos en `rojo`.
Python3
# Double check for null values in `red` pd.isnull(red)
Producción:
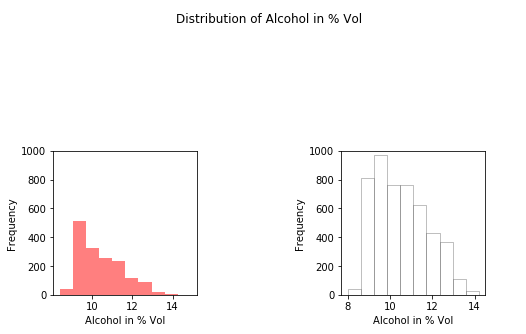
Paso #2: Distribución de Alcohol.
Creación de histograma.
Python3
# Create Histogram
fig, ax = plt.subplots(1, 2)
ax[0].hist(red.alcohol, 10, facecolor ='red',
alpha = 0.5, label ="Red wine")
ax[1].hist(white.alcohol, 10, facecolor ='white',
ec ="black", lw = 0.5, alpha = 0.5,
label ="White wine")
fig.subplots_adjust(left = 0, right = 1, bottom = 0,
top = 0.5, hspace = 0.05, wspace = 1)
ax[0].set_ylim([0, 1000])
ax[0].set_xlabel("Alcohol in % Vol")
ax[0].set_ylabel("Frequency")
ax[1].set_ylim([0, 1000])
ax[1].set_xlabel("Alcohol in % Vol")
ax[1].set_ylabel("Frequency")
fig.suptitle("Distribution of Alcohol in % Vol")
plt.show()
Producción:
Dividir el conjunto de datos para entrenamiento y validación.
Python3
# Add `type` column to `red` with price one red['type'] = 1 # Add `type` column to `white` with price zero white['type'] = 0 # Append `white` to `red` wines = red.append(white, ignore_index = True) # Import `train_test_split` from `sklearn.model_selection` from sklearn.model_selection import train_test_split X = wines.ix[:, 0:11] y = np.ravel(wines.type) # Splitting the data set for training and validating X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.34, random_state = 45)
Paso #3: Estructura de la Red
Python3
# Import `Sequential` from `keras.models` from keras.models import Sequential # Import `Dense` from `keras.layers` from keras.layers import Dense # Initialize the constructor model = Sequential() # Add an input layer model.add(Dense(12, activation ='relu', input_shape =(11, ))) # Add one hidden layer model.add(Dense(9, activation ='relu')) # Add an output layer model.add(Dense(1, activation ='sigmoid')) # Model output shape model.output_shape # Model summary model.summary() # Model config model.get_config() # List all weight tensors model.get_weights() model.compile(loss ='binary_crossentropy', optimizer ='adam', metrics =['accuracy'])
Producción:

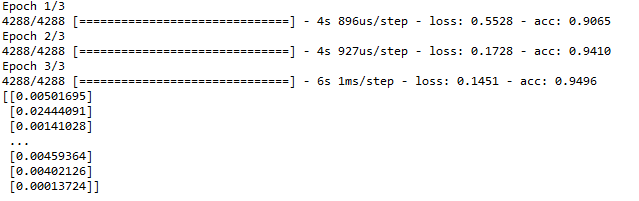
Paso #4: Entrenamiento y Predicción
Python3
# Training Model model.fit(X_train, y_train, epochs = 3, batch_size = 1, verbose = 1) # Predicting the Value y_pred = model.predict(X_test) print(y_pred)
Producción:
Publicación traducida automáticamente
Artículo escrito por AniketSingh1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA