ETL es un proceso en Data Warehousing y significa Extraer , Transformar y Cargar . Es un proceso en el que una herramienta ETL extrae los datos de varios sistemas de origen de datos, los transforma en el área de preparación y, finalmente, los carga en el sistema de almacenamiento de datos.
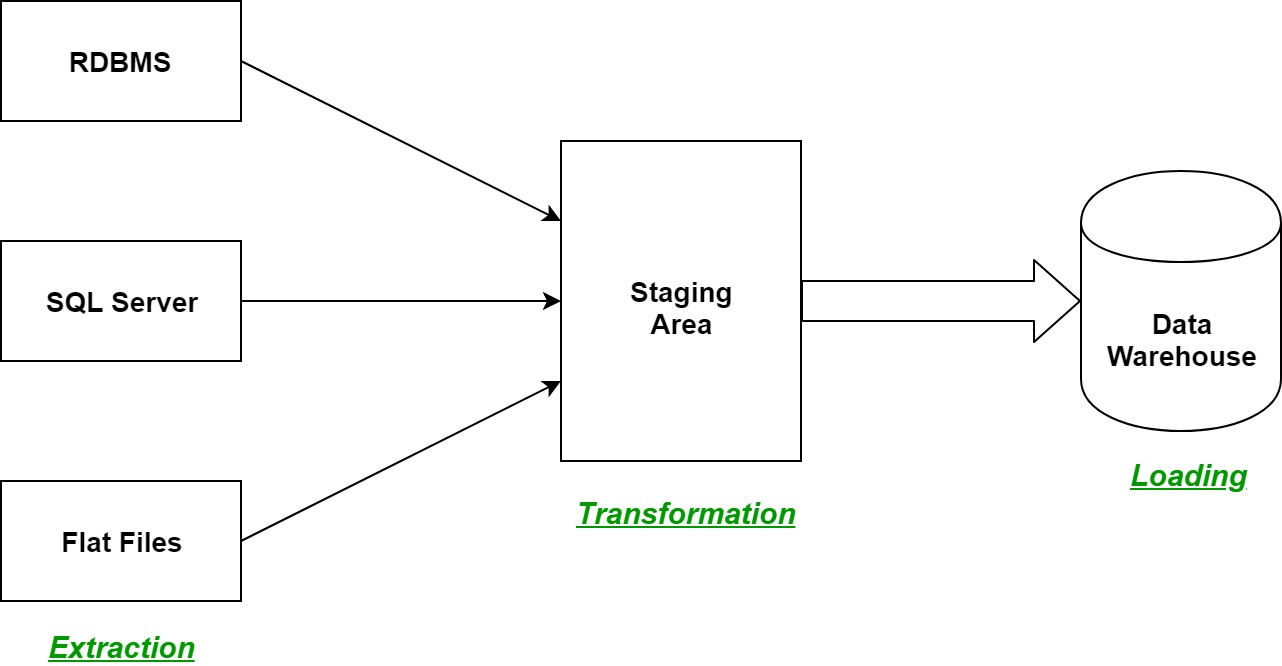
Comprendamos cada paso del proceso ETL en profundidad:
- Extracción:
El primer paso del proceso ETL es la extracción. En este paso, se extraen datos de varios sistemas de origen que pueden estar en varios formatos, como bases de datos relacionales, No SQL, XML y archivos planos en el área de ensayo. Es importante extraer los datos de varios sistemas de origen y almacenarlos primero en el área de preparación y no directamente en el almacén de datos porque los datos extraídos están en varios formatos y también pueden corromperse. Por lo tanto, cargarlo directamente en el almacén de datos puede dañarlo y la reversión será mucho más difícil. Por lo tanto, este es uno de los pasos más importantes del proceso ETL. - Transformación:
El segundo paso del proceso ETL es la transformación. En este paso, se aplica un conjunto de reglas o funciones sobre los datos extraídos para convertirlos en un único formato estándar. Puede implicar los siguientes procesos/tareas:- Filtrado: cargar solo ciertos atributos en el almacén de datos.
- Limpieza: completar los valores NULL con algunos valores predeterminados, mapear EE. UU., Estados Unidos y América en EE. UU., etc.
- Unirse: unir múltiples atributos en uno.
- Dividir: dividir un solo atributo en múltiples atributos.
- Clasificación: clasificación de tuplas en función de algún atributo (generalmente atributo clave).
- Carga:
el tercer y último paso del proceso ETL es la carga. En este paso, los datos transformados finalmente se cargan en el almacén de datos. A veces, los datos se actualizan cargándolos en el almacén de datos con mucha frecuencia y, a veces, se hace después de intervalos más largos pero regulares. La velocidad y el período de carga dependen únicamente de los requisitos y varían de un sistema a otro.
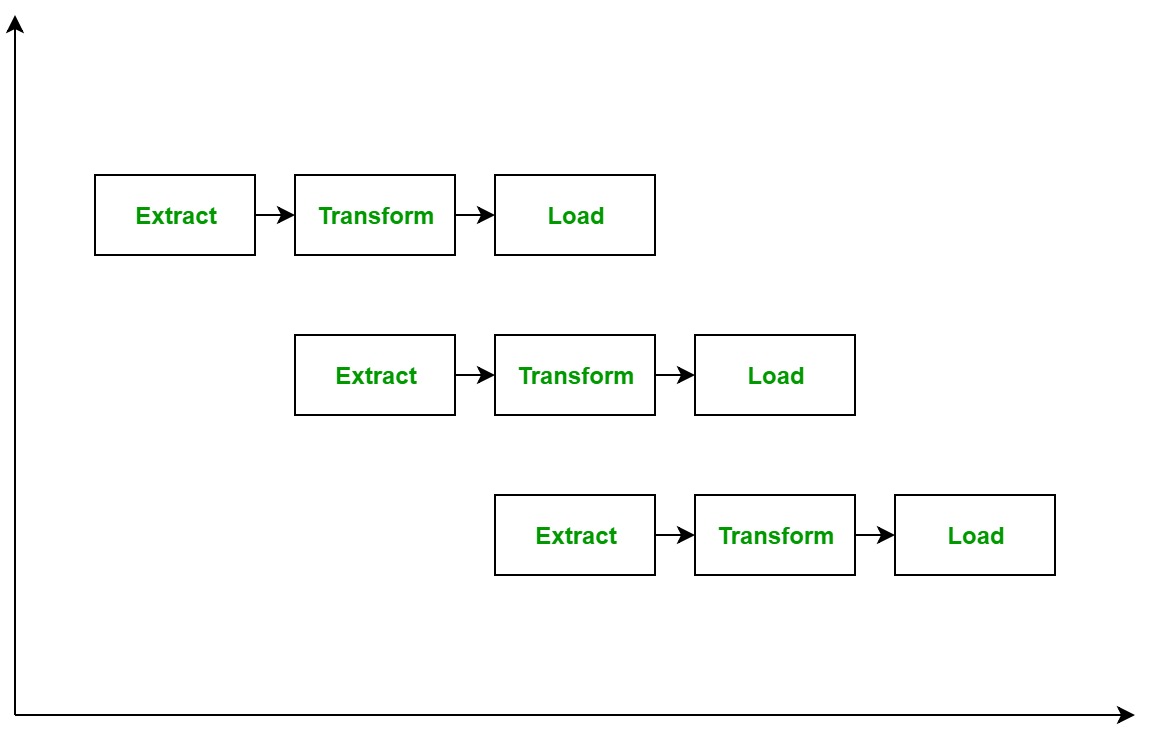
El proceso ETL también puede utilizar el concepto de canalización, es decir, tan pronto como se extraen algunos datos, se pueden transformar y durante ese período se pueden extraer algunos datos nuevos. Y mientras los datos transformados se cargan en el almacén de datos, los datos ya extraídos se pueden transformar. El diagrama de bloques de la canalización del proceso ETL se muestra a continuación:
Herramientas ETL: las herramientas ETL más utilizadas son Hevo , Sybase, Oracle Warehouse builder, CloverETL y MarkLogic.
Almacenes de datos: los almacenes de datos más utilizados son Snowflake , Redshift, BigQuery y Firebolt.