Hay dos listas enlazadas individualmente en un sistema. Por algún error de programación, el Node final de una de las listas vinculadas se vinculó a la segunda lista, formando una lista en forma de Y invertida. Escriba un programa para obtener el punto donde se fusionan dos listas enlazadas.
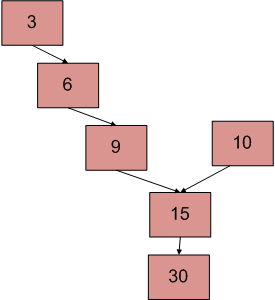
El diagrama anterior muestra un ejemplo con dos listas vinculadas que tienen 15 como puntos de intersección.
Método 1 (simplemente use dos bucles):
use 2 anidados para bucles. El bucle exterior será para cada Node de la primera lista y el bucle interior será para la segunda lista. En el bucle interno, verifique si alguno de los Nodes de la segunda lista es el mismo que el Node actual de la primera lista vinculada. La complejidad temporal de este método será O(M * N) donde m y n son los números de Nodes en dos listas.
Método 2 (Marcar Nodes visitados):
esta solución requiere modificaciones en la estructura básica de datos de la lista vinculada. Tenga una bandera visitada con cada Node. Recorra la primera lista enlazada y siga marcando los Nodes visitados. Ahora recorra la segunda lista enlazada. Si vuelve a ver un Node visitado, entonces hay un punto de intersección, devuelva el Node de intersección. Esta solución funciona en O(m+n) pero requiere información adicional con cada Node. Se puede implementar una variación de esta solución que no requiere modificar la estructura de datos básica mediante un hash. Recorra la primera lista enlazada y almacene las direcciones de los Nodes visitados en un hash. Ahora recorra la segunda lista enlazada y si ve una dirección que ya existe en el hash, devuelva el Node de intersección.
Método 3 (usando la diferencia de recuentos de Nodes):
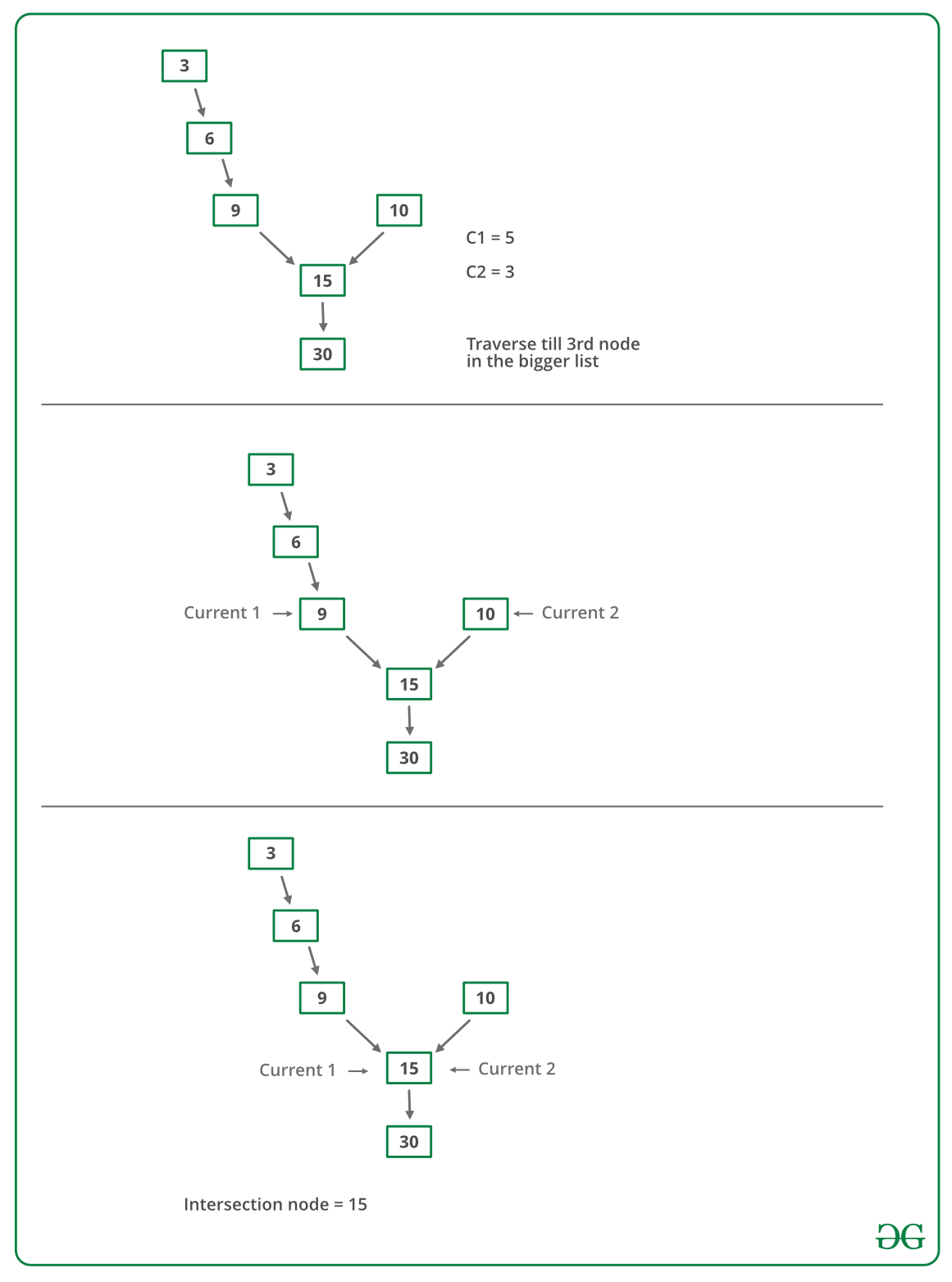
- Obtenga la cuenta de los Nodes en la primera lista, deje que la cuenta sea c1.
- Obtenga la cuenta de los Nodes en la segunda lista, deje que la cuenta sea c2.
- Obtener la diferencia de conteos d = abs(c1 – c2)
- Ahora recorra la lista más grande desde el primer Node hasta d Nodes para que de aquí en adelante ambas listas tengan el mismo número de Nodes
- Entonces podemos recorrer ambas listas en paralelo hasta que encontremos un Node común. (Tenga en cuenta que obtener un Node común se realiza comparando la dirección de los Nodes)
La imagen de abajo es una ejecución en seco del enfoque anterior:
A continuación se muestra la implementación del enfoque anterior:
C#
// C# program to get intersection point
// of two linked list
using System;
class LinkedList
{
Node head1, head2;
public class Node
{
public int data;
public Node next;
public Node(int d)
{
data = d;
next = null;
}
}
/* Function to get the intersection
point of two linked lists head1
and head2 */
int getNode()
{
int c1 = getCount(head1);
int c2 = getCount(head2);
int d;
if (c1 > c2)
{
d = c1 - c2;
return _getIntesectionNode(d, head1,
head2);
}
else
{
d = c2 - c1;
return _getIntesectionNode(d, head2,
head1);
}
}
/* Function to get the intersection point
of two linked lists head1 and head2
where head1 has d more nodes than head2 */
int _getIntesectionNode(int d, Node node1,
Node node2)
{
int i;
Node current1 = node1;
Node current2 = node2;
for (i = 0; i < d; i++)
{
if (current1 == null)
{
return -1;
}
current1 = current1.next;
}
while (current1 != null &&
current2 != null)
{
if (current1.data == current2.data)
{
return current1.data;
}
current1 = current1.next;
current2 = current2.next;
}
return -1;
}
/* Takes head pointer of the linked list
and returns the count of nodes in
the list */
int getCount(Node node)
{
Node current = node;
int count = 0;
while (current != null)
{
count++;
current = current.next;
}
return count;
}
public static void Main(String[] args)
{
LinkedList list = new LinkedList();
// creating first linked list
list.head1 = new Node(3);
list.head1.next = new Node(6);
list.head1.next.next = new Node(9);
list.head1.next.next.next = new Node(15);
list.head1.next.next.next.next = new Node(30);
// creating second linked list
list.head2 = new Node(10);
list.head2.next = new Node(15);
list.head2.next.next = new Node(30);
Console.WriteLine("The node of intersection is " +
list.getNode());
}
}
// This code is contributed by Arnab Kundu
Producción:
The node of intersection is 15
Complejidad temporal: O(m+n)
Espacio auxiliar: O(1)
Método 4 (haga un círculo en la primera lista):
gracias a Saravanan Man por proporcionar la solución a continuación.
1. Recorra la primera lista enlazada (cuente los elementos) y haga una lista enlazada circular. (Recuerde el último Node para que podamos romper el círculo más adelante).
2. Ahora vea el problema como encontrar el bucle en la segunda lista enlazada. Así que el problema está resuelto.
3. Como ya conocemos la longitud del bucle (tamaño de la primera lista enlazada), podemos recorrer esa cantidad de Nodes en la segunda lista y luego iniciar otro puntero desde el principio de la segunda lista. tenemos que atravesar hasta que sean iguales, y ese es el punto de intersección requerido.
4. elimine el círculo de la lista vinculada.
Complejidad temporal: O(m+n)
Espacio auxiliar: O(1)
Método 5 (Invertir la primera lista y hacer ecuaciones):
Gracias a Saravanan Mani por proporcionar este método.
1) Let X be the length of the first linked list until the intersection point.
Let Y be the length of the second linked list until the intersection point.
Let Z be the length of the linked list from the intersection point to End of
the linked list including the intersection node.
We Have
X + Z = C1;
Y + Z = C2;
2) Reverse first linked list.
3) Traverse Second linked list. Let C3 be the length of second list - 1.
Now we have
X + Y = C3
We have 3 linear equations. By solving them, we get
X = (C1 + C3 – C2)/2;
Y = (C2 + C3 – C1)/2;
Z = (C1 + C2 – C3)/2;
WE GOT THE INTERSECTION POINT.
4) Reverse first linked list.
Ventaja: No hay comparación de punteros.
Desventaja: modificación de la lista enlazada (lista de inversión).
Complejidad temporal: O(m+n)
Espacio auxiliar: O(1)
Método 6 (Recorre ambas listas y compara las direcciones de los últimos Nodes): Este método es solo para detectar si hay un punto de intersección o no. (Gracias a NeoTheSaviour por sugerir esto)
1) Traverse list 1, store the last node address 2) Traverse list 2, store the last node address. 3) If nodes stored in 1 and 2 are same then they are intersecting.
La complejidad temporal de este método es O(m+n) y el espacio auxiliar utilizado es O(1)
Método 7 (Usar Hashing):
Básicamente, necesitamos encontrar un Node común de dos listas enlazadas. Así que hacemos hash de todos los Nodes de la primera lista y luego verificamos la segunda lista.
1) Cree un conjunto hash vacío.
2) Atraviese la primera lista enlazada e inserte las direcciones de todos los Nodes en el conjunto hash.
3) Recorrer la segunda lista. Para cada Node, compruebe si está presente en el conjunto hash. Si encontramos un Node en el conjunto hash, devolvemos el Node.
C#
// C# program to get intersection
// point of two linked list
using System;
using System.Collections.Generic;
public class Node
{
public int data;
public Node next;
public Node(int d)
{
data = d;
next = null;
}
}
public class LinkedListIntersect
{
public static void Main(String[] args)
{
// list 1
Node n1 = new Node(1);
n1.next = new Node(2);
n1.next.next = new Node(3);
n1.next.next.next = new Node(4);
n1.next.next.next.next = new Node(5);
n1.next.next.next.next.next = new Node(6);
n1.next.next.next.next.next.next = new Node(7);
// list 2
Node n2 = new Node(10);
n2.next = new Node(9);
n2.next.next = new Node(8);
n2.next.next.next = n1.next.next.next;
Print(n1);
Print(n2);
Console.WriteLine(MegeNode(n1, n2).data);
}
// Function to print the list
public static void Print(Node n)
{
Node cur = n;
while (cur != null)
{
Console.Write(cur.data + " ");
cur = cur.next;
}
Console.WriteLine();
}
// function to find the intersection
// of two node
public static Node MegeNode(Node n1,
Node n2)
{
// Define hashset
HashSet<Node> hs = new HashSet<Node>();
while (n1 != null)
{
hs.Add(n1);
n1 = n1.next;
}
while (n2 != null)
{
if (hs.Contains(n2))
{
return n2;
}
n2 = n2.next;
}
return null;
}
}
// This code is contributed by 29AjayKumar
Producción:
1 2 3 4 5 6 7 10 9 8 4 5 6 7 4
Este método requería O(n) espacio adicional y no era muy eficiente si una lista era grande.
Complejidad de tiempo : O(n) donde n es el tamaño del hash
Consulte el artículo completo sobre Escribir una función para obtener el punto de intersección de dos listas vinculadas para obtener más detalles.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA