Todos estamos familiarizados con el desastre que ocurrió el 14 de abril de 1912. El gran barco gigante de 46000 toneladas de peso se hundió a una profundidad de 13,000 pies en el Océano Atlántico Norte. Nuestro objetivo es analizar los datos obtenidos tras este desastre. Hadoop MapReduce se puede utilizar para manejar estos grandes conjuntos de datos de manera eficiente para encontrar cualquier solución para un problema en particular.
Declaración del problema: analizar el conjunto de datos del desastre del Titanic para encontrar la edad promedio de las personas que murieron en este desastre, tanto hombres como mujeres, con MapReduce Hadoop.
Paso 1:
Podemos descargar el Titanic Dataset desde este enlace . A continuación se muestra la estructura de columnas de nuestro conjunto de datos Titanic. Consta de 12 columnas donde cada fila describe la información de una persona en particular.

Paso 2:
Los primeros 10 registros del conjunto de datos se muestran a continuación.

Paso 3:
Haga el proyecto en Eclipse con los siguientes pasos:
- Primero abra Eclipse -> luego seleccione Archivo -> Nuevo -> Proyecto Java -> Nómbrelo Titanic_Data_Analysis -> luego seleccione usar un entorno de ejecución -> elija JavaSE-1.8 luego siguiente -> Finalizar .
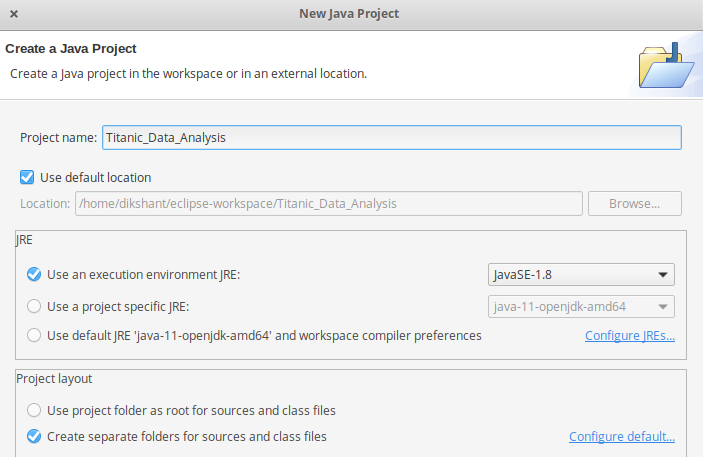
- En este proyecto, cree una clase Java con el nombre Average_age -> luego haga clic en Finalizar
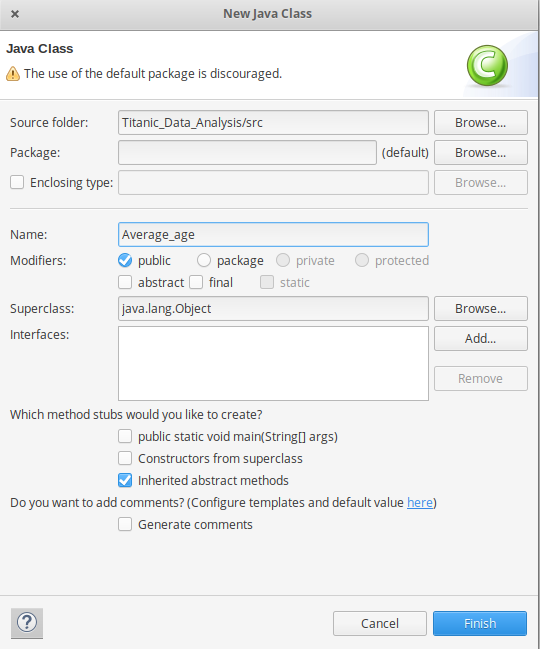
- Copie el código fuente a continuación a esta clase java de Average_age
Java
// import libraries
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
// Making a class with name Average_age
public class Average_age {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
// private text gender variable which
// stores the gender of the person
// who died in the Titanic Disaster
private Text gender = new Text();
// private IntWritable variable age will store
// the age of the person for MapReduce. where
// key is gender and value is age
private IntWritable age = new IntWritable();
// overriding map method(run for one time for each record in dataset)
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
// storing the complete record
// in a variable name line
String line = value.toString();
// splitting the line with ', ' as the
// values are separated with this
// delimiter
String str[] = line.split(", ");
/* checking for the condition where the
number of columns in our dataset
has to be more than 6. This helps in
eliminating the ArrayIndexOutOfBoundsException
when the data sometimes is incorrect
in our dataset*/
if (str.length > 6) {
// storing the gender
// which is in 5th column
gender.set(str[4]);
// checking the 2nd column value in
// our dataset, if the person is
// died then proceed.
if ((str[1].equals("0"))) {
// checking for numeric data with
// the regular expression in this column
if (str[5].matches("\\d+")) {
// converting the numeric
// data to INT by typecasting
int i = Integer.parseInt(str[5]);
// storing the person of age
age.set(i);
}
}
}
// writing key and value to the context
// which will be output of our map phase
context.write(gender, age);
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
// overriding reduce method(runs each time for every key )
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
{
// declaring the variable sum which
// will store the sum of ages of people
int sum = 0;
// Variable l keeps incrementing for
// all the value of that key.
int l = 0;
// foreach loop
for (IntWritable val : values) {
l += 1;
// storing and calculating
// sum of values
sum += val.get();
}
sum = sum / l;
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
@SuppressWarnings("deprecation")
Job job = new Job(conf, "Averageage_survived");
job.setJarByClass(Average_age.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
Path out = new Path(args[1]);
out.getFileSystem(conf).delete(out);
job.waitForCompletion(true);
}
}
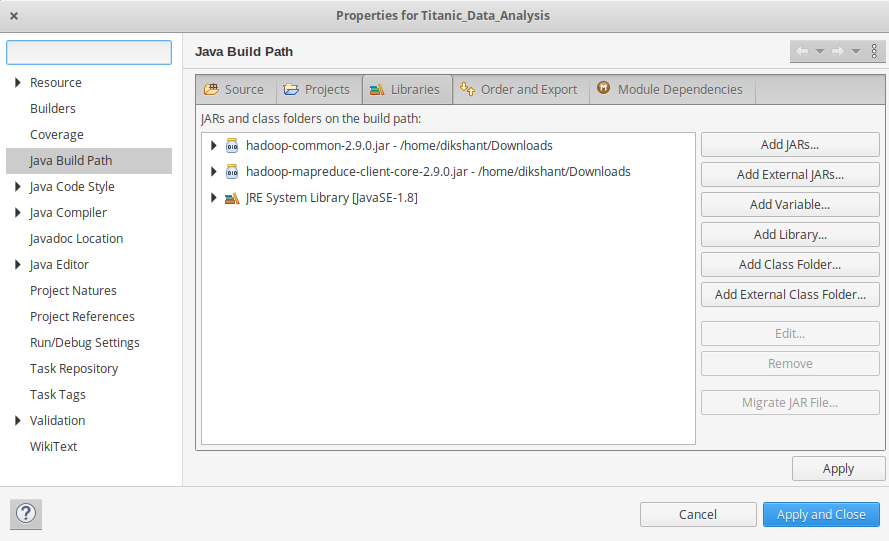
- Ahora necesitamos agregar un jar externo para los paquetes que hemos importado. Descargue el paquete jar Hadoop Common y Hadoop MapReduce Core según su versión de Hadoop.
Compruebe la versión de Hadoop:
hadoop version

- Ahora agregamos estos frascos externos a nuestro proyecto Titanic_Data_Analysis . Haga clic derecho en Titanic_Data_Analysis -> luego seleccione Build Path -> Haga clic en Configure Build Path y seleccione Add External jars…. y agregue frascos desde su ubicación de descarga, luego haga clic en -> Aplicar y cerrar .
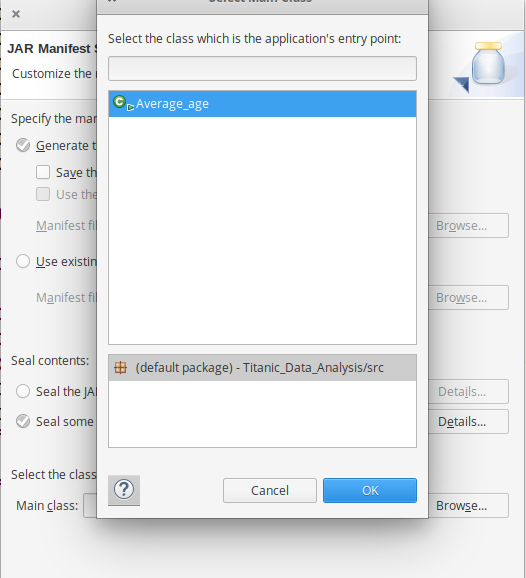
- Ahora exporte el proyecto como archivo jar. Haga clic con el botón derecho en Titanic_Data_Analysis , elija Exportar… y vaya a Java -> Archivo JAR, haga clic en -> Siguiente y elija su destino de exportación, luego haga clic en -> Siguiente . Elija Main Class como Average_age haciendo clic en -> Examinar y luego haga clic en -> Finalizar -> Aceptar .

Paso 4:
Inicie los demonios de Hadoop
start-dfs.sh
start-yarn.sh
Luego, marque Ejecutar demonios de Hadoop.
jps
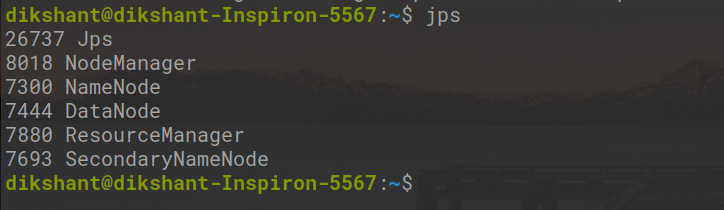
Paso 5:
Mueva su conjunto de datos a Hadoop HDFS.
Sintaxis:
hdfs dfs -put /file_path /destination
En el siguiente comando / muestra el directorio raíz de nuestro HDFS.
hdfs dfs -put /home/dikshant/Documents/titanic_data.txt /
Verifique el archivo enviado a nuestro HDFS.
hdfs dfs -ls /

Paso 6:
Ahora ejecute su archivo Jar con el siguiente comando y produzca la salida en Titanic_Output File.
Sintaxis:
hadoop jar /jar_file_location /dataset_location_in_HDFS /output-file_name
Dominio:
hadoop jar /home/dikshant/Documents/Average_age.jar /titanic_data.txt /Titanic_Output
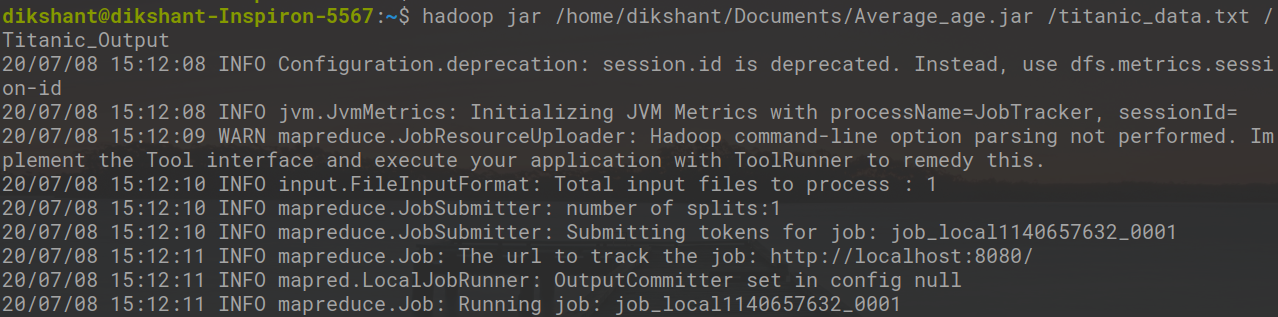
Paso 7:
Ahora muévase a localhost:50070/ , en utilidades, seleccione Examinar el sistema de archivos y descargue part-r-00000 en el directorio /MyOutput para ver el resultado.
Nota: También podemos ver el resultado con el siguiente comando
hdfs dfs -cat /Titanic_Output/part-r-00000

En la imagen de arriba, podemos ver que la edad promedio de la mujer es 28 y el hombre es 30 según nuestro conjunto de datos que murió en el desastre del Titanic.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA