CSV (valores separados por comas) es un formato de archivo simple que se utiliza para almacenar datos tabulares, como una hoja de cálculo o una base de datos. El archivo CSV almacena datos tabulares (números y texto) en texto sin formato. Cada línea del archivo es un registro de datos. Cada registro consta de uno o más campos, separados por comas. El uso de la coma como separador de campo es el origen del nombre de este formato de archivo.
Los archivos CSV se pueden leer usando la biblioteca de Python llamada Pandas. Esta biblioteca se puede utilizar para leer varios tipos de archivos, incluidos los archivos CSV. Usamos la función de biblioteca read_csv(input) para leer el archivo CSV. La URL/ruta del archivo CSV que desea leer se proporciona como entrada para la función.
Sintaxis:
pd.leer_csv(filepath_or_buffer, sep=’, ‘, delimitador=Ninguno, encabezado=’inferir’, nombres=Ninguno, index_col=Ninguno, usecols=Ninguno, squeeze=False, prefix=Ninguno, mangle_dupe_cols=True, dtype=Ninguno, motor=Ninguno, convertidores=Ninguno, valores_verdaderos=Ninguno, valores_falsos=Ninguno, skipinitialspace=False, skiprows=Ninguno, nrows=Ninguno, na_values=Ninguno, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format= Falso, keep_date_col=False, date_parser=Ninguno, dayfirst=False, iterator=False, chunksize=Ninguno, compresión=’inferir’, miles=Ninguno, decimal=b’.’, lineterminator=Ninguno, quotechar=’”’, citando =0, escapechar=Ninguno, comentario=Ninguno, codificación=Ninguno, dialecto=Ninguno, tupleize_cols=Ninguno, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False , float_precision=Ninguno)
No todos son muy importantes, pero recordarlos realmente ahorra tiempo de realizar las mismas funciones por su cuenta. Uno puede ver los parámetros de cualquier función presionando shift + tab en jupyter notebook. Los útiles se dan a continuación con su uso:
| Parámetro | Usar |
|---|---|
| ruta_archivo_o_búfer | Ubicación URL o directorio del archivo |
| sep | Significa separador, el valor predeterminado es ‘,’ como en csv (valores separados por comas) |
| index_col | Hace que la columna pasada sea un índice en lugar de 0, 1, 2, 3…r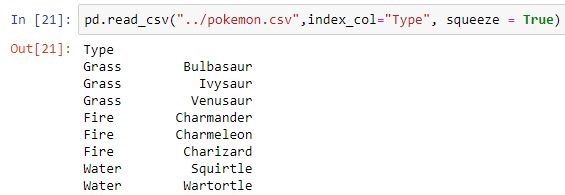 |
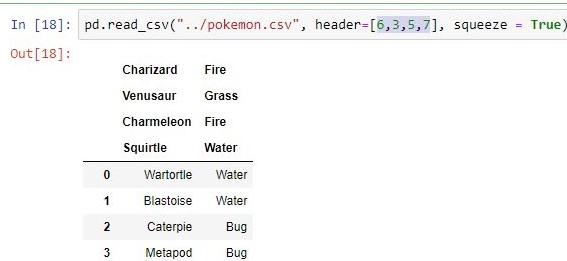
| encabezamiento | Hace pasada la fila/s[int/int list] como encabezado
|
| use_cols | Solo usa la columna pasada [lista de strings] para hacer un marco de datos |
| estrujar | Si es verdadero y solo se pasa una columna, devuelve la serie pandas |
| salteadores | Omite las filas pasadas en el nuevo marco de datos |
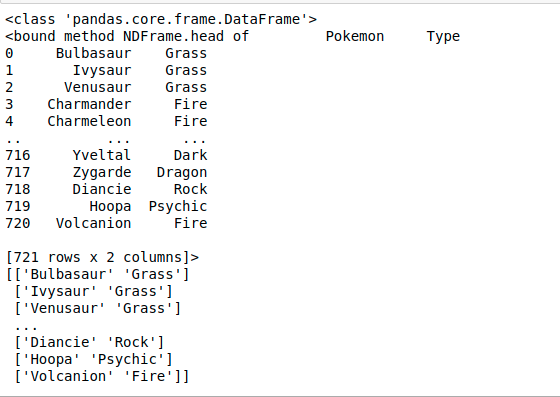
Si la ruta dada no es válida, es decir, el archivo no está presente en la ruta dada, entonces la función da un archivo FileNotFoundError. Pero si la función lee correctamente el archivo, devuelve un objeto de tipo class pandas.core.frame.DataFrame. El marco de datos devuelto (Objeto) se puede convertir en una array numpy mediante el uso de la función. dataframe.to_numpy()Esta función viene con pandas y devuelve la representación de array numpy del marco de datos. Luego, podemos usar arrcomo una array numpy para realizar las operaciones deseadas.
Ejemplo:
# PYthon program to read
# CSV file without csv module
import pandas as pd
#reading a csv file with pandas
data_frame = pd.read_csv("pokemon.csv")
#give the datatype of a pandas
# object
print(type(data_frame))
#this function gives us a
# brief view of the data.
print(data_frame.head)
#converting pandas dataframe
# to a numpy array.
arr = data_frame.to_numpy()
print(arr)
Producción:
Publicación traducida automáticamente
Artículo escrito por NiteshNijhawan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA