XGBoost es un algoritmo rápido y eficiente y lo utilizan los ganadores de muchas competencias de aprendizaje automático. XG Boost funciona solo con las variables numéricas.
XGBoost en R
Es una parte de la técnica boosting en la que la selección de la muestra se hace de forma más inteligente para clasificar las observaciones. Hay interfaces de XGBoost en C++, R , Python, Julia, Java y Scala. Las funciones principales de XGBoost se implementan en C++, por lo que es fácil compartir modelos entre diferentes interfaces. Según las estadísticas del espejo CRAN, el paquete se ha descargado más de 81 000 veces. El modelado de XgBoost consta de dos técnicas: Bagging y Boosting.
- Embolsado : es un enfoque en el que puede tomar muestras aleatorias de datos, crear algoritmos de aprendizaje y tomar medios simples para encontrar probabilidades de embolsado.
- Impulso : es un enfoque en el que una selección de enfoques se realiza de forma más inteligente, es decir, se da cada vez más peso para clasificar las observaciones.
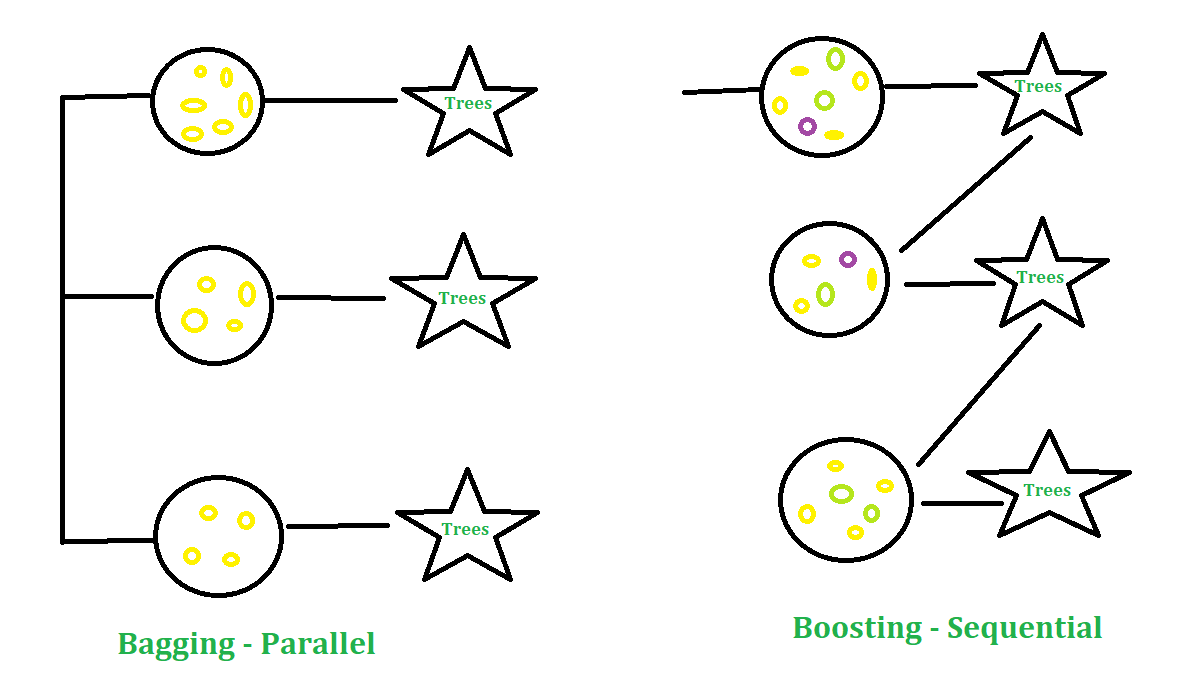
Parámetros en XGBoost
- eta: reduce los pesos de las características para que el proceso de impulso sea más conservador. El rango es de 0 a 1. También se conoce como tasa de aprendizaje o factor de reducción. Un valor eta bajo significa que el modelo es más resistente al sobreajuste.
- gamma: cuanto mayor sea el valor de gamma, más conservador será el algoritmo. Su rango es de 0 a infinito.
- max_ depth: la profundidad máxima de un árbol se puede especificar usando el parámetro max_ depth.
- Submuestra: Es la proporción de hileras que el modelo seleccionará aleatoriamente para cultivar árboles.
- colsample_bytree: Es la relación de variables elegidas aleatoriamente para construir cada árbol en el modelo.
El conjunto de datos
gran centro comercialEl conjunto de datos consta de 1559 productos en 10 tiendas en diferentes ciudades. Se han definido ciertos atributos de cada producto y tienda. Consta de 12 características, es decir, Item_Identifier (es una identificación de producto única asignada a cada artículo distinto), Item_Weight (incluye el peso del producto), Item_Fat_Content (describe si el producto es bajo en grasa o no), Item_Visibility (menciona el porcentaje de la área de exhibición total de todos los productos en una tienda asignados a un producto en particular), Item_Type (describe la categoría de alimentos a la que pertenece el artículo), Item_MRP (Precio máximo de venta al público (precio de lista) del producto), Outlet_Identifier (ID de tienda único asignado. Consiste en una string alfanumérica de longitud 6), Outlet_Establishment_Year (menciona el año en que se estableció la tienda),
R
# Loading data
train = fread("Train_UWu5bXk.csv")
test = fread("Test_u94Q5KV.csv")
# Structure
str(train)
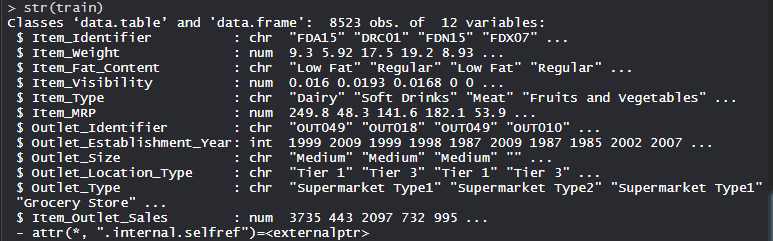
Ejecución de XGBoost en un conjunto de datos
Usando el algoritmo XGBoost en el conjunto de datos que incluye 12 funciones con 1559 productos en 10 tiendas en diferentes ciudades.
R
# Installing Packages
install.packages("data.table")
install.packages("dplyr")
install.packages("ggplot2")
install.packages("caret")
install.packages("xgboost")
install.packages("e1071")
install.packages("cowplot")
# Loading packages
library(data.table) # for reading and manipulation of data
library(dplyr) # for data manipulation and joining
library(ggplot2) # for ploting
library(caret) # for modeling
library(xgboost) # for building XGBoost model
library(e1071) # for skewness
library(cowplot) # for combining multiple plots
# Setting test dataset
# Combining datasets
# add Item_Outlet_Sales to test data
test[, Item_Outlet_Sales := NA]
combi = rbind(train, test)
# Missing Value Treatment
missing_index = which(is.na(combi$Item_Weight))
for(i in missing_index){
item = combi$Item_Identifier[i]
combi$Item_Weight[i] = mean(combi$Item_Weight
[combi$Item_Identifier == item],
na.rm = T)
}
# Replacing 0 in Item_Visibility with mean
zero_index = which(combi$Item_Visibility == 0)
for(i in zero_index){
item = combi$Item_Identifier[i]
combi$Item_Visibility[i] = mean(
combi$Item_Visibility[combi$Item_Identifier == item],
na.rm = T)
}
# Label Encoding
# To convert categorical in numerical
combi[, Outlet_Size_num :=
ifelse(Outlet_Size == "Small", 0,
ifelse(Outlet_Size == "Medium", 1, 2))]
combi[, Outlet_Location_Type_num :=
ifelse(Outlet_Location_Type == "Tier 3", 0,
ifelse(Outlet_Location_Type == "Tier 2", 1, 2))]
combi[, c("Outlet_Size", "Outlet_Location_Type") := NULL]
# One Hot Encoding
# To convert categorical in numerical
ohe_1 = dummyVars("~.",
data = combi[, -c("Item_Identifier",
"Outlet_Establishment_Year",
"Item_Type")], fullRank = T)
ohe_df = data.table(predict(ohe_1,
combi[, -c("Item_Identifier",
"Outlet_Establishment_Year", "Item_Type")]))
combi = cbind(combi[, "Item_Identifier"], ohe_df)
# Remove skewness
skewness(combi$Item_Visibility)
skewness(combi$price_per_unit_wt)
# log + 1 to avoid division by zero
combi[, Item_Visibility := log(Item_Visibility + 1)]
# Scaling and Centering data
# index of numeric features
num_vars = which(sapply(combi, is.numeric))
num_vars_names = names(num_vars)
combi_numeric = combi[, setdiff(num_vars_names,
"Item_Outlet_Sales"), with = F]
prep_num = preProcess(combi_numeric,
method = c("center", "scale"))
combi_numeric_norm = predict(prep_num, combi_numeric)
# removing numeric independent variables
combi[, setdiff(num_vars_names,
"Item_Outlet_Sales") := NULL]
combi = cbind(combi,
combi_numeric_norm)
# Splitting data back to train and test
train = combi[1:nrow(train)]
test = combi[(nrow(train) + 1):nrow(combi)]
# Removing Item_Outlet_Sales
test[, Item_Outlet_Sales := NULL]
# Model Building: XGBoost
param_list = list(
objective = "reg:linear",
eta = 0.01,
gamma = 1,
max_depth = 6,
subsample = 0.8,
colsample_bytree = 0.5
)
# Converting train and test into xgb.DMatrix format
Dtrain = xgb.DMatrix(
data = as.matrix(train[, -c("Item_Identifier",
"Item_Outlet_Sales")]),
label = train$Item_Outlet_Sales)
Dtest = xgb.DMatrix(
data = as.matrix(test[, -c("Item_Identifier")]))
# 5-fold cross-validation to
# find optimal value of nrounds
set.seed(112) # Setting seed
xgbcv = xgb.cv(params = param_list,
data = Dtrain,
nrounds = 1000,
nfold = 5,
print_every_n = 10,
early_stopping_rounds = 30,
maximize = F)
# Training XGBoost model at nrounds = 428
xgb_model = xgb.train(data = Dtrain,
params = param_list,
nrounds = 428)
xgb_model
# Variable Importance
var_imp = xgb.importance(
feature_names = setdiff(names(train),
c("Item_Identifier", "Item_Outlet_Sales")),
model = xgb_model)
# Importance plot
xgb.plot.importance(var_imp)
Producción:
- Entrenamiento del modelo Xgboost:
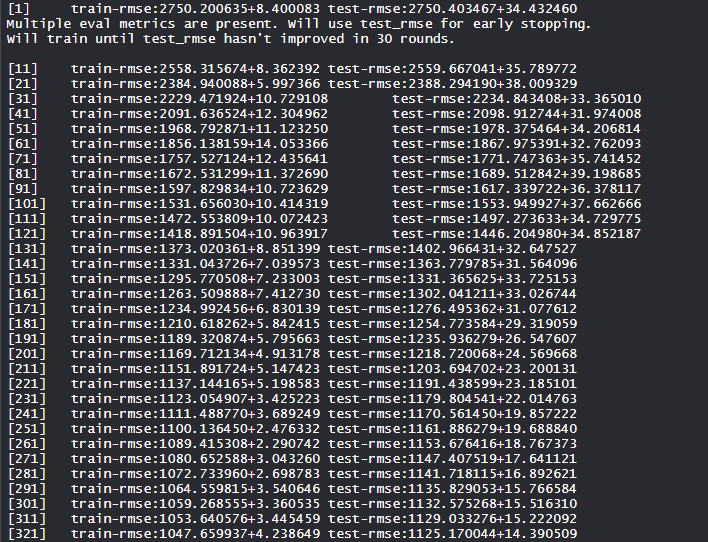
El modelo xgboost se entrena calculando la puntuación de tren-rmse y la puntuación de prueba-rmse y encontrando su valor más bajo en muchas rondas.
- Modelo xgb_modelo:
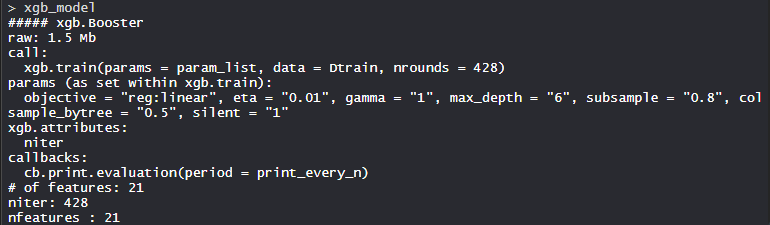
Los modelos XgBoost constan de 21 funciones con el objetivo de regresión lineal, eta es 0,01, gamma es 1, max_ depth es 6, submuestra es 0,8, colsample_bytree = 0,5 y silent es 1.
- Gráfica de importancia variable:
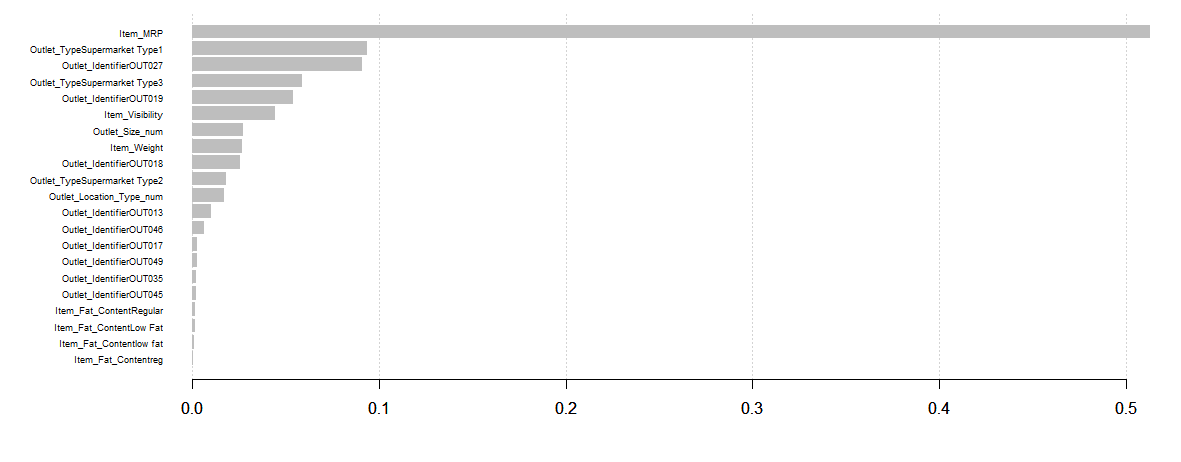
Item_MRP es la variable más importante seguida de Item_Visibility y Outlet_Location_Type_num.
Por lo tanto, Xgboost encuentra sus aplicaciones en muchos sectores de la industria y se utiliza con plena capacidad.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA