Introducción | Scikit-aprender
Scikit-learn es una biblioteca de aprendizaje automático para Python. Cuenta con varios algoritmos de clasificación, regresión y agrupación, que incluyen máquinas de vectores de soporte, bosques aleatorios, aumento de gradiente, k-means y DBSCAN, y está diseñado para interactuar con las bibliotecas numéricas y científicas de Python NumPy y SciPy. Aprenda más sobre Scikit-learn desde aquí .
Estudio de caso | Whisky agrupado
Objetivo y descripción: el whisky escocés es apreciado por su complejidad y variedad de sabores. Y se cree que las regiones de Escocia donde se produce tienen distintos perfiles de sabor. En este estudio de caso, clasificaremos los whiskies escoceses según sus características de sabor. El conjunto de datos que usaremos contiene una selección de whiskies escoceses de varias destilerías e intentaremos agrupar los whiskies en grupos que tengan un sabor similar. Este estudio de caso profundizará su comprensión de Pandas, NumPy y scikit-learn, y tal vez de whisky escocés.
Fuente: Descargue el conjunto de datos de regiones de whisky y el conjunto de datos de variedades de whiskyPondremos estos conjuntos de datos en el directorio de la ruta de trabajo. El conjunto de datos que usaremos consiste en calificaciones de degustación de un whisky escocés de malta simple fácilmente disponible de casi todas las destilerías de whisky activas en Escocia. El conjunto de datos resultante tiene 86 whiskies de malta que se califican entre 0 y 4 en 12 categorías de sabor diferentes. Las puntuaciones se han agregado de 10 catadores diferentes. Las categorías de sabor describen si los whiskies son dulces, ahumados, medicinales, especiados, etc.
◊ Correlación por pares ◊
El conjunto de datos de variedades de whisky contiene 86 filas de puntajes de prueba de whisky de malta y 17 columnas de categorías de sabor. Agregamos otra columna al conjunto de datos usando el código whisky[“Región”] = pd.read_csv(“regiones.txt”) , ahora es 86 filas y 18 columnas (la nueva columna es información de la región). Los nombres de las 18 columnas se pueden encontrar con la ayuda del comando >>>whisky.columns . Redujimos nuestro alcance a 18 filas y 12 columnas usando whisky.iloc[: , 2:14] y almacenamos los resultados en una variable llamada sabores. Utilizando el método corr() calculamos la correlación por pares de las columnas de la variable sabor. Codificamos,
Python
import numpy as np
import pandas as pd
whisky = pd.read_csv("whiskies.txt")
whisky["Region"] = pd.read_csv("regions.txt")
# >>>whisky.head(), iloc method to index a data frame by location.
# >>>whisky.iloc[0:10], we specified the rows from 0 - 9
# >>>whisky.iloc[0:10, 0:5], we specified the rows from 0 - 9 & columns from 0-5
# >>>whisky.columns
flavors = whisky.iloc[:, 2:14]
corr_flavors = pd.DataFrame.corr(flavors)
print(corr_flavors)
Salida: El DataFrame de correlación es:

◊ Trazado de correlación por pares ◊
Vamos a trazar el DataFrame de correlación usando el gráfico matplotlib. Para mayor comodidad, mostraremos una barra de colores junto con el gráfico. Codificamos,
Python
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.pcolor(corr_flavors)
plt.colorbar()
#>>>plt.savefig("corlate-whisky1.pdf")
corr_whisky = pd.DataFrame.corr(flavors.transpose())
plt.figure(figsize=(10, 10))
plt.pcolor(corr_whisky)
plt.axis("tight")
plt.colorbar()
#>>>plt.savefig("corlate-whisky2.pdf")
plt.show()
Resultado: En las gráficas 1 y 2 , el color azul representa la correlación mínima y el color rojo muestra la correlación máxima. La primera gráfica es una correlación normal de todas las categorías de sabor y la segunda gráfica es la correlación entre los puntajes de las pruebas de whisky de malta. La segunda gráfica la trama parece más compleja en relación con la primera, debido al mayor número de columnas (86).
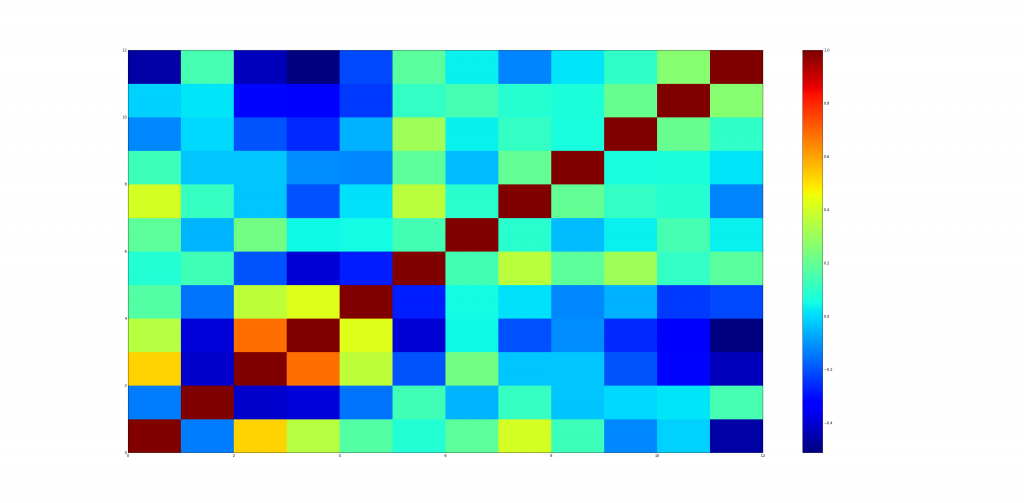

◊ Coclustering espectral ◊
El objetivo de la agrupación conjunta es agrupar simultáneamente las filas y las columnas de una array de datos de entrada. La array se pasa al algoritmo de agrupación conjunta espectral.
Python
from sklearn.cluster.bicluster import SpectralCoclustering import numpy as np import pandas as pd import matplotlib.pyplot as plt model = SpectralCoclustering(n_clusters=6, random_state=0) model.fit(corr_whisky) model.rows_ #>>>np.sum(model.rows_, axis=1) #>>>np.sum(model.rows_, axis=0) model.row_labels_
Salida: Usamos SpectralCoclustering() para agrupar filas y columnas de la array. La salida del código anterior es:

◊ Comparación de datos correlacionados ◊
Importaremos los módulos necesarios y ordenaremos los datos por grupo. Tratamos de comparar el gráfico entre las correlaciones reorganizadas frente a la original una al lado de la otra. Codificamos,
Python
from sklearn.cluster.bicluster import SpectralCoclustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
whisky['Group'] = pd.Series(model.row_labels_, index = whisky.index)
whisky = whisky.ix[np.argsort(model.row_labels_)]
whisky = whisky.reset_index(drop=True)
correlations = pd.DataFrame.corr(whisky.iloc[:, 2:14].transpose())
correlations = np.array(correlations)
plt.figure(figsize = (14, 7))
plt.subplot(121)
plt.pcolor(corr_whisky)
plt.title("Original")
plt.axis("tight")
plt.subplot(122)
plt.pcolor(correlations)
plt.title("Rearranged")
plt.axis("tight")
plt.show()
plt.savefig("correlations.pdf")
Resultado: en el gráfico de salida , el primer gráfico es el gráfico de correlación original y el segundo es para el gráfico ordenado y reorganizado. La diagonal roja marcada en ambas figuras representa una relación de correlación de 1.

Referencia :
Este artículo es una contribución de Amartya Ranjan Saikia . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA