En este artículo, aprenderemos cómo importar datos para conjuntos de datos en PyBrain.
Los conjuntos de datos son los datos que se proporcionarán para probar, validar y entrenar en las redes. El tipo de dataset a utilizar depende de las tareas que vayamos a realizar con Machine Learning. Los conjuntos de datos más utilizados que admite Pybrain son SupervisedDataSet y ClassificationDataSet . Como su nombre sugiere, ClassificationDataSet se usa en los problemas de clasificación y SupervisedDataSet para tareas de aprendizaje supervisado.
Método 1: Importación de datos para conjuntos de datos mediante archivos CSV
Este es el método más simple para importar cualquier conjunto de datos desde un archivo CSV. Para esto, usaremos Panda, por lo que es imprescindible importar la biblioteca de Pandas.
Sintaxis: pd.read_csv(‘ruta del archivo csv’)
Considere que el archivo CSV que queremos importar es price.csv .
Python3
import pandas as pd
print('Read data...')
# enter the complete path of the csv file
df = pd.read_csv('../price.csv',header=0).head(1000)
data = df.values
Método 2: Importación de datos para conjuntos de datos usando Sklearn
Hay muchos conjuntos de datos prefabricados disponibles en la biblioteca Sklearn. Se pueden usar tres tipos principales de interfaces de conjuntos de datos para obtener conjuntos de datos según el tipo de conjunto de datos deseado.
- Los cargadores de conjuntos de datos : se pueden usar para cargar conjuntos de datos estándar pequeños, que se describen en la sección Conjuntos de datos de juguetes.
Ejemplo 1: cargar el conjunto de datos de Iris
Python3
from pybrain.datasets import ClassificationDataSet from sklearn import datasets nums = datasets.load_iris() x, y = nums.data, nums.target ds = ClassificationDataSet(4, 1, nb_classes=3) for j in range(len(x)): ds.addSample(x[j], y[j]) ds
Producción:
<pybrain.datasets.classification.ClassificationDataSet en 0x7f7004812a50>
Ejemplo 2: Cargando conjunto de datos de dígitos
Python3
from sklearn import datasets from pybrain.datasets import ClassificationDataSet digits = datasets.load_digits() X, y = digits.data, digits.target ds = ClassificationDataSet(64, 1, nb_classes=10) for i in range(len(X)): ds.addSample(ravel(X[i]), y[i])
Producción:
<pybrain.datasets.classification.ClassificationDataSet en 0x5d4054612v80>
- Los buscadores de conjuntos de datos: se pueden usar para descargar y cargar conjuntos de datos más grandes
Ejemplo:
Python3
import sklearn as sk sk.datasets.fetch_california_housing
Producción:
<función sklearn.datasets._california_housing.fetch_california_housing>
- Las funciones de generación de conjuntos de datos : se pueden utilizar para generar conjuntos de datos sintéticos controlados, descritos en la sección Conjuntos de datos generados. Estas funciones devuelven una tupla (X, y) que consta de una array n_samples * n_features NumPy X y una array de longitud n_samples que contiene los objetivos y.
Ejemplo:
Python3
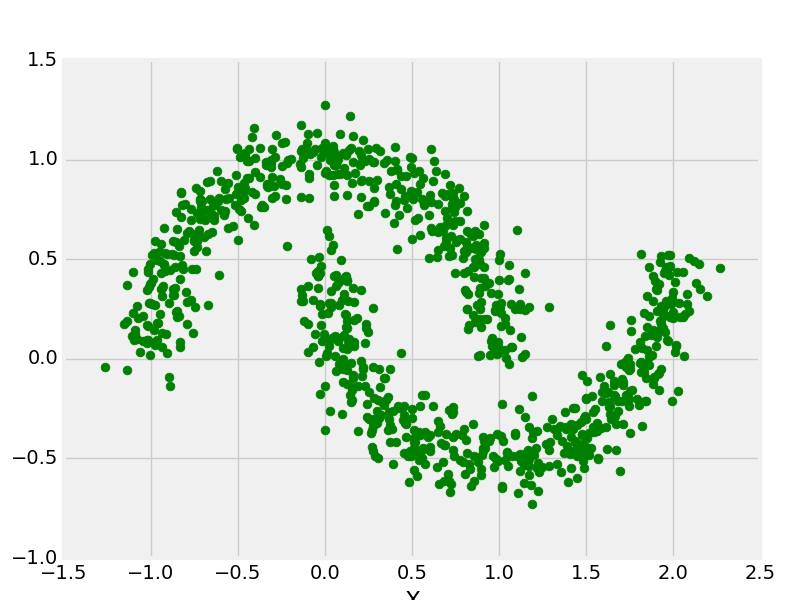
from sklearn.datasets import make_moon
from matplotlib import pyplot as plt
from matplotlib import style
X, y = make_moons(n_samples = 1000, noise = 0.1)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
Producción:
Publicación traducida automáticamente
Artículo escrito por patilanurag661 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA