En este artículo, discutiremos cómo realizar la agregación en varias columnas en Pyspark usando Python. Podemos hacer esto usando la función Groupby()
Vamos a crear un marco de datos para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.show()
Producción:
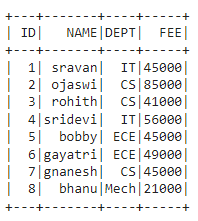
En PySpark, groupBy() se usa para recopilar datos idénticos en grupos en PySpark DataFrame y realizar funciones agregadas en los datos agrupados.
La operación de agregación incluye:
- count(): esto devolverá el recuento de filas para cada grupo.
dataframe.groupBy(‘column_name_group’).count()
- mean(): Esto devolverá la media de los valores para cada grupo.
dataframe.groupBy(‘column_name_group’).mean(‘column_name’)
- max(): Esto devolverá el máximo de valores para cada grupo.
dataframe.groupBy(‘column_name_group’).max(‘column_name’)
- min(): Esto devolverá el mínimo de valores para cada grupo.
dataframe.groupBy(‘column_name_group’).min(‘column_name’)
- sum(): Esto devolverá los valores totales para cada grupo.
dataframe.groupBy(‘column_name_group’).sum(‘column_name’)
- avg(): Esto devolverá el promedio de valores para cada grupo.
dataframe.groupBy(‘column_name_group’).avg(‘column_name’).show()
Podemos agrupar y agregar en varias columnas a la vez usando la siguiente sintaxis:
dataframe.groupBy(‘column_name_group1′,’column_name_group2′,…………,’column_name_group n’).aggregate_operation(‘column_name’)
Ejemplo 1 : Groupby con la función mean() con DEPT y NAME
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT and NAME with mean()
dataframe.groupBy('DEPT', 'NAME').mean('FEE').show()
Producción:
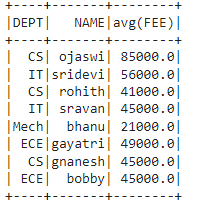
Ejemplo 2: Agregación en todas las columnas
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT,ID and NAME with mean()
dataframe.groupBy('DEPT', 'ID', 'NAME').mean('FEE').show()
Producción:
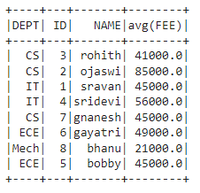
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA