A veces, mientras manejamos datos dentro de un marco de datos, podemos obtener valores nulos. Para limpiar el conjunto de datos, debemos eliminar todos los valores nulos en el marco de datos. Entonces, en este artículo, aprenderemos cómo colocar filas con valores NULL o None en PySpark DataFrame.
Función utilizada
En pyspark, la función drop() se puede usar para eliminar valores nulos del marco de datos. Toma los siguientes parámetros: –
Sintaxis: dataframe_name.na.drop(how=”any/all”,thresh=threshold_value,subset=[“column_name_1″,”column_name_2”])
- how – Esto toma cualquiera de los dos valores ‘any’ o ‘all’ . ‘cualquiera’, suelte una fila si contiene NULL en cualquier columna y ‘todos’, suelte una fila solo si todas las columnas tienen valores NULL. Por defecto se establece en ‘cualquiera’
- umbral: esto toma un valor entero y elimina las filas que tienen menos que ese umbral que contiene valores no nulos. Por defecto está configurado en ‘Ninguno’.
- subconjunto: este parámetro se usa para seleccionar una columna específica para apuntar a los valores NULL en ella. Por defecto es ‘Ninguno
Nota: DataFrame tiene una variable na que representa una instancia de la clase DataFrameNaFunctions. Por lo tanto, usamos una variable en DataFrame para usar la función drop().
Estamos especificando nuestra ruta al directorio de chispa usando la función findspark.init() para permitir que nuestro programa encuentre la ubicación de apache spark en nuestra máquina local. Ignore esta línea si está ejecutando el programa en la nube. Supongamos que tenemos nuestra carpeta chispa en la unidad c con el nombre de chispa, por lo que la función se parecería a:- findspark.init(‘c:/spark’). No especificar la ruta a veces puede provocar el error py4j.protocol.Py4JError al ejecutar el programa localmente.
Ejemplos
Ejemplo 1: Descartar todas las filas con cualquier valor nulo
En este ejemplo, vamos a crear nuestro propio conjunto de datos personalizado y usaremos la función drop() para eliminar las filas que tienen valores nulos. Vamos a soltar todas las filas que tienen valores nulos en el marco de datos. Dado que estamos creando nuestros propios datos, necesitamos especificar nuestro esquema junto con ellos para crear el conjunto de datos.
Python3
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
# spark location
# add the respective path to your spark
findspark.init('_path-to-spark_')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# create the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# drop None Values
df.na.drop(how="any").show(truncate=False)
# stop spark session
spark.stop()
Producción:
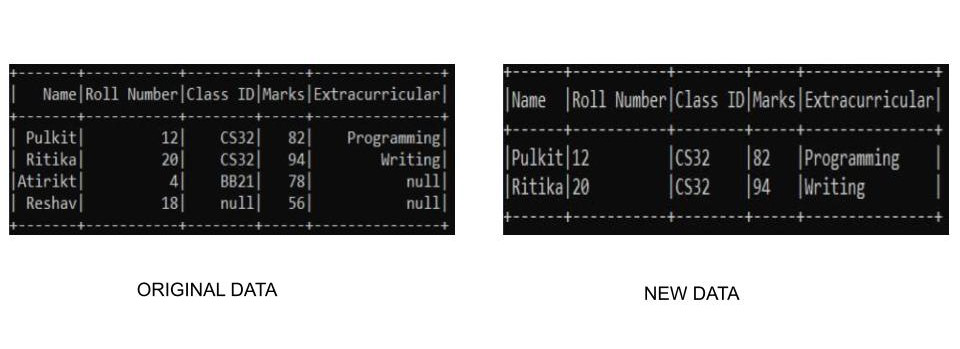
Ejemplo 2: Descartar todas las filas con cualquier valor nulo en una columna específica
También podemos seleccionar columnas particulares para verificar usando el campo de subconjunto. En este ejemplo, estamos utilizando nuestro conjunto de datos personalizado y eliminaremos los datos de la fila que tiene un valor nulo solo en la columna de ID de clase. Dado que estamos creando nuestros propios datos, necesitamos especificar nuestro esquema junto con ellos para crear el conjunto de datos. Podemos realizar la operación de la siguiente manera:-
Python3
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
# spark location
# add the respective path to your spark
findspark.init('_path-to-spark_')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# create the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# drop None Values
df.na.drop(subset=["Class ID"]).show(truncate=False)
# stop spark session
spark.stop()
Producción:
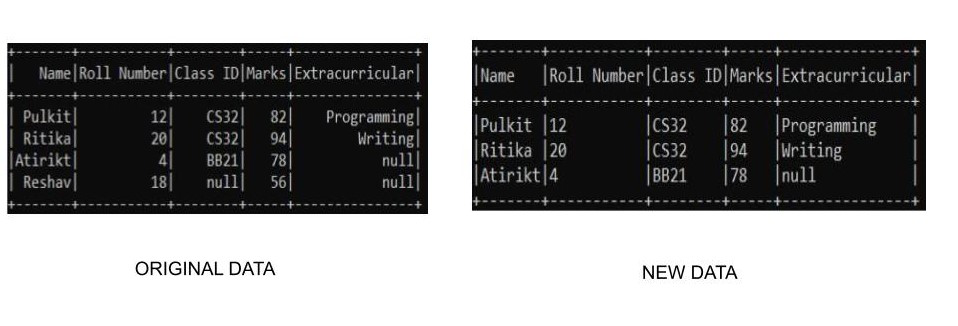
Ejemplo 3: Descartar todas las filas con cualquier valor nulo usando el método dropna()
Una tercera forma de eliminar filas con valores nulos es usar la función dropna() . La función dropna() funciona de manera similar a como lo hace na.drop(). Aquí no necesitamos especificar ninguna variable, ya que detecta los valores nulos y elimina las filas por sí mismo. Dado que estamos creando nuestros propios datos, necesitamos especificar nuestro esquema junto con ellos para crear el conjunto de datos. Podemos usarlo en pyspark de la siguiente manera:
Python3
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
# spark location
# add the respective path to your spark
findspark.init('_path-to-spark_')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# create the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# drop None Values
df.dropna().show(truncate=False)
# stop spark session
spark.stop()
Producción:
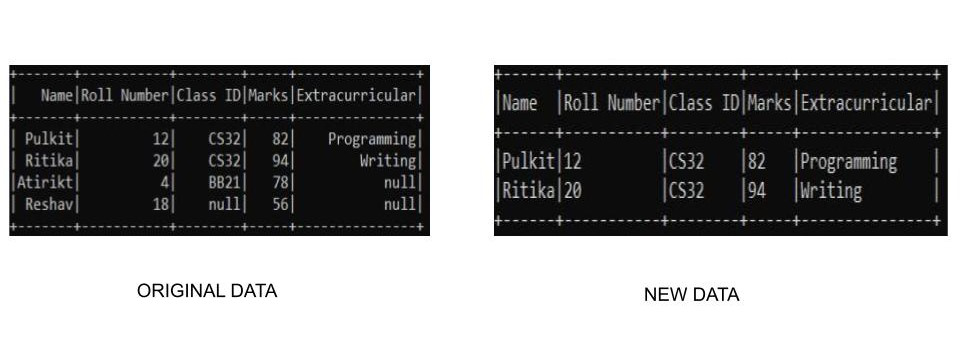
Publicación traducida automáticamente
Artículo escrito por pulkit12dhingra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA