Cuando hay un gran conjunto de datos, es mejor dividirlos en partes iguales y luego procesar cada marco de datos individualmente. Esto es posible si la operación en el marco de datos es independiente de las filas. Cada fragmento o marco de datos igualmente dividido puede procesarse en paralelo haciendo un uso más eficiente de los recursos. En este artículo, discutiremos cómo dividir marcos de datos de PySpark en un número igual de filas.
Creando Dataframe para demostración:
Python
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# Column names for the dataframe
columns = ["Brand", "Product"]
# Row data for the dataframe
data = [
("HP", "Laptop"),
("Lenovo", "Mouse"),
("Dell", "Keyboard"),
("Samsung", "Monitor"),
("MSI", "Graphics Card"),
("Asus", "Motherboard"),
("Gigabyte", "Motherboard"),
("Zebronics", "Cabinet"),
("Adata", "RAM"),
("Transcend", "SSD"),
("Kingston", "HDD"),
("Toshiba", "DVD Writer")
]
# Create the dataframe using the above values
prod_df = spark.createDataFrame(data=data,
schema=columns)
# View the dataframe
prod_df.show()
Producción:
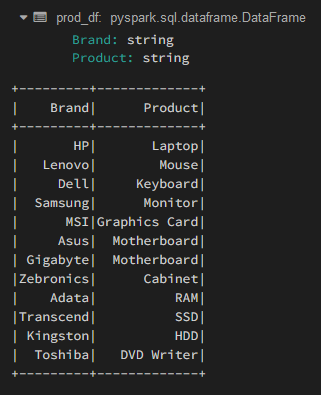
En el bloque de código anterior, hemos definido la estructura del esquema para el marco de datos y proporcionamos datos de muestra. Nuestro marco de datos consta de 2 columnas de tipo string con 12 registros.
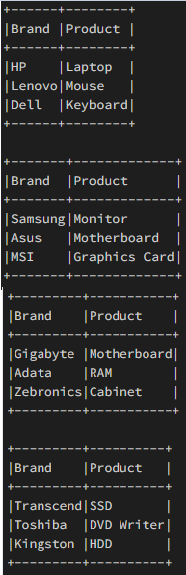
Ejemplo 1: marco de datos dividido usando ‘DataFrame.limit()’
Haremos uso del método split() para crear ‘n’ marcos de datos iguales.
Sintaxis: DataFrame.limit(num)
Donde, limita el recuento de resultados al número especificado.
Código:
Python
# Define the number of splits you want n_splits = 4 # Calculate count of each dataframe rows each_len = prod_df.count() // n_splits # Create a copy of original dataframe copy_df = prod_df # Iterate for each dataframe i = 0 while i < n_splits: # Get the top `each_len` number of rows temp_df = copy_df.limit(each_len) # Truncate the `copy_df` to remove # the contents fetched for `temp_df` copy_df = copy_df.subtract(temp_df) # View the dataframe temp_df.show(truncate=False) # Increment the split number i += 1
Producción:
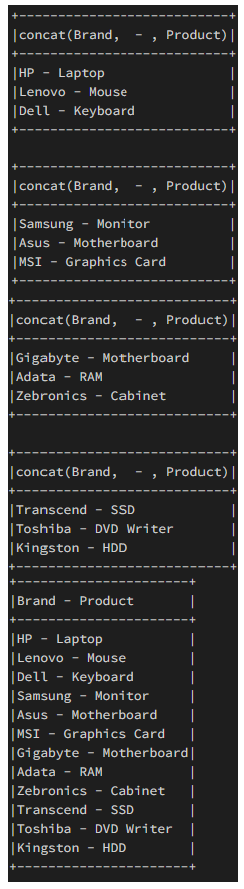
Ejemplo 2: dividir el marco de datos, realizar la operación y concatenar el resultado
Ahora dividiremos el marco de datos en ‘n’ partes iguales y realizaremos una operación de concatenación en cada una de estas partes individualmente y luego concatenaremos el resultado a un `result_df`. Esto es para demostrar cómo podemos usar la extensión del código anterior para realizar una operación de marco de datos por separado en cada marco de datos y luego agregar estos marcos de datos individuales para producir un nuevo marco de datos que tenga una longitud igual al marco de datos original.
Python
# Define the number of splits you want
from pyspark.sql.types import StructType, StructField, StringType
from pyspark.sql.functions import concat, col, lit
n_splits = 4
# Calculate count of each dataframe rows
each_len = prod_df.count() // n_splits
# Create a copy of original dataframe
copy_df = prod_df
# Function to modify columns of each individual split
def modify_dataframe(data):
return data.select(
concat(col("Brand"), lit(" - "),
col("Product"))
)
# Create an empty dataframe to
# store concatenated results
schema = StructType([
StructField('Brand - Product', StringType(), True)
])
result_df = spark.createDataFrame(data=[],
schema=schema)
# Iterate for each dataframe
i = 0
while i < n_splits:
# Get the top `each_len` number of rows
temp_df = copy_df.limit(each_len)
# Truncate the `copy_df` to remove
# the contents fetched for `temp_df`
copy_df = copy_df.subtract(temp_df)
# Perform operation on the newly created dataframe
temp_df_mod = modify_dataframe(data=temp_df)
temp_df_mod.show(truncate=False)
# Concat the dataframe
result_df = result_df.union(temp_df_mod)
# Increment the split number
i += 1
result_df.show(truncate=False)
Producción:
Publicación traducida automáticamente
Artículo escrito por apathak092 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA