Supongamos que tenemos un DataFrame que contiene columnas que tienen diferentes tipos de valores como strings, enteros, etc. y, a veces, los datos de la columna también están en formato de array. Trabajar con la array a veces es difícil y, para eliminar la dificultad, queríamos dividir los datos de la array en filas.
Para dividir múltiples datos de columnas de array en filas, pyspark proporciona una función llamada explotar() . Usando explotar, obtendremos una nueva fila para cada elemento de la array. Cuando se pasa una array a esta función, crea una nueva columna predeterminada y contiene todos los elementos de la array, ya que se ignorarán sus filas y los valores nulos presentes en la array. Esta es una función incorporada que está disponible en el módulo pyspark.sql.functions .
Sintaxis: pyspark.sql.functions.explode(col)
Parámetros:
- col es un nombre de columna de array que queremos dividir en filas.
Nota: Solo se necesita un argumento posicional, es decir, a la vez solo se puede dividir una columna.
Ejemplo: columna de array dividida usando explotar()
En este ejemplo, crearemos un marco de datos que contiene tres columnas, una columna es ‘Nombre’ que contiene el nombre de los estudiantes, la otra columna es ‘Edad’ que contiene la edad de los estudiantes, y la última y tercera columna ‘Cursos_inscritos’ contiene los cursos inscritos. por estos estudiantes. Las dos primeras columnas contienen datos simples de tipo string, pero la tercera columna contiene datos en formato de array. Dividiremos la columna ‘Courses_inrolled’ que contiene datos en formato de array en filas.
Python3
# importing pyspark
import pyspark
# importing sparksessio
from pyspark.sql import SparkSession
# importing all from pyspark.sql.functions
# like Row, array, explode etc.
from pyspark.sql.functions import *
# creating a sparksession object and
# providing appName
spark=SparkSession.builder.appName("sparkdf").getOrCreate()
# now creating dataframe
# creating the row data and giving array
# values for dataframe
data = [('Jaya', '20', ['SQL','Data Science']),
('Milan', '21', ['ML','AI']),
('Rohit', '19', ['Programming', 'DSA']),
('Maria', '20', ['DBMS', 'Networking']),
('Jay', '22', ['Data Analytics','ML'])]
# column names for dataframe
columns = ['Name', 'Age', 'Courses_enrolled']
# creating dataframe with createDataFrame()
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
Producción:
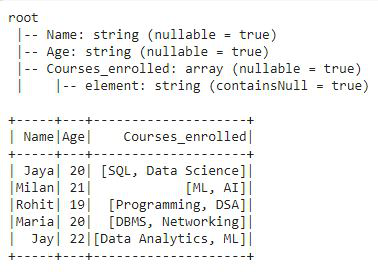
En el esquema del marco de datos podemos ver que las dos primeras columnas tienen datos de tipo string y la tercera columna tiene datos de array. Ahora, dividiremos la columna de la array en filas usando explotar().
Python3
# using select function applying # explode on array column df2 = df.select(df.Name,explode(df.Courses_enrolled)) # printing the schema of the df2 df2.printSchema() # show df2 df2.show()
Producción:

En este resultado, podemos ver que la columna de la array se divide en filas. La función explotar() creó una columna predeterminada ‘col’ para la columna de la array, cada elemento de la array se convierte en una fila, y también el tipo de la columna se cambia a string, anteriormente su tipo era una array como se menciona en la salida df anterior.
Tipos de explotar()
Hay tres formas de explotar una columna de array:
- explotar_exterior()
- posexplotar()
- posexplotar_exterior()
Entendamos cada uno de ellos con un ejemplo. Para esto, crearemos un marco de datos que también contenga algunos arreglos nulos y dividiremos la columna del arreglo en filas usando diferentes tipos de explosión.
Python3
# creating the row data and giving array
# values for dataframe along with null values
data = [('Jaya', '20', ['SQL', 'Data Science']),
('Milan', '21', ['ML', 'AI']),
('Rohit', '19', None),
('Maria', '20', ['DBMS', 'Networking']),
('Jay', '22', None)]
# column names for dataframe
columns = ['Name', 'Age', 'Courses_enrolled']
# creating dataframe with createDataFrame()
df = spark.createDataFrame(data, columns)
# printing dataframe schema
df.printSchema()
# show dataframe
df.show()
Producción:

1.explote_outer(): La función explosion_outer divide la columna de la array en una fila para cada elemento del elemento de la array, ya sea que contenga un valor nulo o no. Mientras que el simple explotar() ignora el valor nulo presente en la columna.
Python3
# now using select function applying # explode_outer on array column df4 = df.select(df.Name, explode_outer(df.Courses_enrolled)) # printing the schema of the df4 df4.printSchema() # show df2 df4.show()
Producción:

Como hemos definido anteriormente, explosion_outer() no ignora los valores nulos de la columna de la array. Claramente, podemos ver que los valores nulos también se muestran como filas del marco de datos.
2. posexplode(): posexplode() divide la columna de la array en filas para cada elemento de la array y también proporciona la posición de los elementos en la array. Crea dos columnas «pos» para llevar la posición del elemento de la array y la ‘col’ para llevar los elementos de la array en particular e ignora los valores nulos. Ahora, aplicaremos posexplode() en la columna de array ‘Courses_inrolled’.
Python3
# using select function applying # explode on array column df2 = df.select(df.Name, posexplode(df.Courses_enrolled)) # printing the schema of the df2 df2.printSchema() # show df2 df2.show()
Producción:

Como posexplode() divide las arrays en filas y también proporciona la posición de los elementos de la array y en esta salida, tenemos las posiciones de los elementos de la array en la columna ‘pos’. E ignoró los valores nulos presentes en la columna de la array.
3. posexplode_outer(): posexplode_outer() divide la columna de la array en filas para cada elemento de la array y también proporciona la posición de los elementos en la array. Crea dos columnas «pos» para llevar la posición del elemento de la array y ‘col’ para llevar los elementos de la array en particular, ya sea que también contenga un valor nulo. Eso significa que posexplode_outer() tiene la funcionalidad de las funciones explosion_outer() y posexplode(). Veamos esto en el ejemplo:
Ahora, aplicaremos posexplode_outer() en la columna de array ‘Courses_inrolled’.
Python3
# using select function applying # explode on array column df2 = df.select(df.Name, posexplode_outer(df.Courses_enrolled)) # printing the schema of the df2 df2.printSchema() # show df2 df2.show()
Producción:
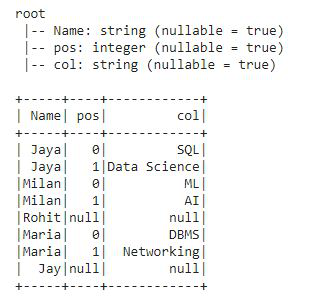
Como, posexplode_outer() proporciona funcionalidades de las funciones de explosión explosion_outer() y posexplode(). En la salida, claramente, podemos ver que tenemos las filas y los valores de posición de todos los elementos de la array, incluidos los valores nulos también en la columna ‘pos’ y ‘col’.
Publicación traducida automáticamente
Artículo escrito por neelutiwari y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA