Un Diccionario en Python funciona de manera similar al Diccionario en el mundo real. Las claves de un diccionario deben ser únicas y de tipos de datos inmutables, como strings, enteros y tuplas, pero los valores clave pueden repetirse y ser de cualquier tipo.
Consulte el siguiente artículo para hacerse una idea de los diccionarios:
Diccionario anidado: los diccionarios anidados en Python no son más que diccionarios dentro de un diccionario.
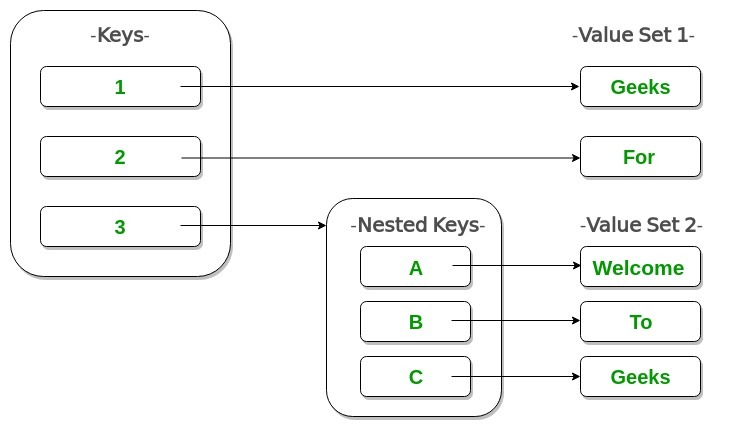
Considere un registro de empleado como se indica a continuación:
Employees
emp1:
name:Lisa
age:29
designation:Programmer
emp2:
name:Steve
age:45
designation:HR
Aquí, los empleados es el diccionario exterior. emp1, emp2 son claves que tienen otro diccionario como valor. La estructura del diccionario de la información anterior aparece como:
employees:
{
emp1:
{
'name':'Lisa',
'age':29,
'designation':'Programmer'
},
emp2:
{
'name':'Steve',
'age':45,
'designation':'HR'
}
}
Considere un diccionario simple como d={'a':1, 'b':2, 'c':3}. Si desea actualizar el valor de ‘b’ a 7 , puede escribir como d['b']=7. Sin embargo, el mismo método no se puede aplicar a los anidados. Eso creará una nueva clave ya que las claves en el diccionario externo solo se buscarán mientras intenta actualizar. Por ejemplo, vea el siguiente código:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '45',
'Designation':'HR'
}
}
# updating in the way similar to
# simple dictionary
Employee['name']='Kate'
print(Employee)
{‘name’: ‘Kate’, ‘emp1′: {‘Designation’: ‘Programmer’, ‘name’: ‘Lisa’, ‘age’: ’29’}, ‘emp2′: {‘Designation’: ‘HR ‘, ‘nombre’: ‘Steve’, ‘edad’: ’45’}}
En la salida, mire que ‘name’:’Kate’ se agrega como un nuevo par clave-valor que no es nuestra salida deseada. Consideremos que necesitamos actualizar el nombre del primer empleado como ‘Kate’. Veamos nuestro diccionario como una array 2D. Esto nos ayudará a actualizar la información fácilmente. La vista de array 2D del diccionario anterior se muestra a continuación:
Employee name age Designation emp1 Lisa 29 Programmer emp2 Steve 45 HR
Ahora tenemos que actualizar el nombre del primer empleado como ‘Kate’. Así que tenemos que actualizar Employee[‘emp1′][‘name’]. El código modificado se muestra a continuación:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# updating in the way similar to simple dictionary
Employee['emp1']['name']='Kate'
print(Employee)
{‘emp2′: {‘Designación’: ‘HR’, ‘edad’: ’25’, ‘nombre’: ‘Steve’}, ‘emp1′: {‘Designación’: ‘Programador’, ‘edad’: ’29 ‘, ‘nombre’: ‘Kate’}}
El método anterior actualiza el valor de la clave mencionada si está presente en el diccionario. De lo contrario, crea una nueva entrada. Por ejemplo, si desea agregar un nuevo atributo ‘salario’ para el primer empleado, puede escribir el código anterior como:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# updating in the way similar to
# simple dictionary
Employee['emp1']['name']='Kate'
# adding new key-value pair to first
# employee record
Employee['emp1']['salary']= 56000
print(Employee)
{‘emp1′: {‘Designation’: ‘Programmer’, ‘salary’: 56000, ‘name’: ‘Kate’, ‘age’: ’29’}, ‘emp2′: {‘Designation’: ‘HR’, ‘nombre’: ‘Steve’, ‘edad’: ’25’}}
Los métodos anteriores son estáticos. Ahora, para hacerlo interactivo con el usuario, podemos modificar ligeramente el código como se indica a continuación:
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# to make the updation dynamic
# Get input from the user for which
# employee he needs to update
empid = input("Employee id :")
# which attribute / key to update
attribute = input("Attribute to be updated :")
# what value to update
new_value = input("New value :")
# updation of the dictionary
Employee[empid][attribute]= new_value
print(Employee)
Employee id :emp1 Attribute to be updated :name New value :Kate
{‘emp1′: {‘edad’: ’29’, ‘Designación’: ‘Programador’, ‘nombre’: ‘Kate’}, ‘emp2′: {‘edad’: ’25’, ‘Designación’: ‘HR ‘, ‘nombre’: ‘Steve’}}
Tratemos de ser un poco más profesionales!!
Un enfoque alternativo
La idea es aplanar primero el diccionario anidado, luego actualizarlo y volver a aplanarlo. Para hacerlo más claro, considere el siguiente diccionario como ejemplo:
dict1={
'a':{
'b':1
},
'c':{
'd':2,
'e':5
}
}
Aplanar un diccionario anidado no es más que agregar la clave principal con la clave real usando los separadores apropiados. El separador puede ser cualquier símbolo. Puede ser una coma (, ), un guión (-), un guión bajo (_), un punto (.) o incluso un espacio ( ). Aquí, después de aplanar con un guión bajo como separador, este diccionario se verá así:
dict1={'a_b':1, 'c_d':2, 'c_e':5}
El aplanamiento se puede hacer fácilmente con los métodos integrados proporcionados por el paqueteflatten-dict en Python. Proporciona métodos para aplanar objetos similares a diccionarios y desacoplarlos. Instale el paquete usando el comando pip como se muestra a continuación:
pip install flatten-dict
flatten()método:
El método flatten tiene varios argumentos para formatearlo de una manera deseable, legible y comprensible. Los dos argumentos más importantes entre todos son:
- dict : El diccionario aplanado que tiene que ser convertido
- reducer : especifica cómo se une la clave principal con la clave secundaria. Los valores posibles son tupla, ruta, guión bajo o un nombre de función definido por el usuario.
- tupla: crea una tupla de claves primarias y secundarias como clave y le asigna el valor.
- ruta: agrega ‘/’ entre la clave principal y la clave secundaria.
- guión bajo: agrega ‘_’ entre la clave principal y la clave secundaria.
- Función definida por el usuario: las claves principal y secundaria deben pasarse a la función como argumentos. La función debería devolverlos como una string separada por el símbolo deseado
Otros argumentos enumerate_types, keep_empty_types son opcionales
método unflatten() :
Este método desincrusta el diccionario aplanado y lo convierte en uno anidado. Puede tomar tres argumentos:
- dict : el diccionario aplanado que debe revertirse
- splitter : El símbolo en el que se debe dividir el diccionario aplanado. Al igual que el método flatten, esto también toma la tupla de valor, la ruta, el guión bajo o una función definida por el usuario.
- inverse : toma un valor booleano que indica si la clave y el valor deben invertirse. Esto es opcional.
Consideremos el mismo ejemplo de empleado que probamos anteriormente. El código se da a continuación:
from flatten_dict import flatten
from flatten_dict import unflatten
# an employee record
Employee = {
'emp1': {
'name': 'Lisa',
'age': '29',
'Designation':'Programmer'
},
'emp2': {
'name': 'Steve',
'age': '25',
'Designation':'HR'
}
}
# flattening the dictionary, default
# reducer is 'tuple'
dict3 = flatten(Employee)
print("Flattened dictionary :", dict3)
# adding new key-value pair to second
# employee's record
dict3[('emp2', 'salary')]= 34000
print(dict3)
# unflattening the dictionary, default
# splitter is 'tuple'
Employee = unflatten(dict3)
print("\nUnflattened and updated dictionary :", Employee)
Producción:
Diccionario aplanado: {(‘emp1′, ‘nombre’): ‘Lisa’, (‘emp1′, ‘edad’): ’29’, (‘emp1′, ‘Designación’): ‘Programador’, (‘emp2′ , ‘nombre’): ‘Steve’, (‘emp2′, ‘edad’): ’25’, (‘emp2′, ‘Designación’): ‘HR’} {(‘emp1′, ‘nombre’):
‘ Lisa’, (‘emp1′, ‘edad’): ’29’, (‘emp1′, ‘Designación’): ‘Programador’, (‘emp2′, ‘nombre’): ‘Steve’, (‘emp2′, ‘edad’): ’25’, (‘emp2′, ‘Designation’): ‘HR’, (‘emp2′, ‘salary’): 34000}Diccionario sin aplanar y actualizado: {‘emp1′: {‘name’: ‘Lisa’, ‘age’: ’29’, ‘Designation’: ‘Programmer’}, ‘emp2′: {‘name’: ‘Steve’, ‘ edad’: ’25’, ‘Puesto’: ‘HR’, ‘salario’: 34000}}
Publicación traducida automáticamente
Artículo escrito por erakshaya485 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA