Discutamos el concepto de análisis sintáctico usando python. En python tenemos muchos módulos, pero para analizar solo necesitamos urllib y re , es decir, una expresión regular. Mediante el uso de estas dos bibliotecas podemos obtener los datos en las páginas web.
Tenga en cuenta que el análisis de sitios web significa que obtiene el código fuente completo y que queremos buscar usando un enlace de URL dado, le dará el resultado como la mayor parte del contenido HTML que no puede entender. Veamos la demostración con una explicación para que entiendas más sobre el análisis.
Código #1: Se necesitan bibliotecas
# importing libraries import urllib.request import urllib.parse import re
Código #2:
url = 'https://www.geeksforgeeks.org/'
values = {'s':'python programming',
'submit':'search'}
Hemos definido una url y algunos valores relacionados que queremos buscar. Recuerde que definimos los valores como un diccionario y en este par de valores clave definimos la programación de Python para buscar en la URL definida.
Código #3:
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
resp = urllib.request.urlopen(req)
respData = resp.read()
En la primera línea codificamos los valores que hemos definido anteriormente, luego (línea 2) codificamos los mismos datos que entiende la máquina.
En la tercera línea de código, solicitamos valores en la URL definida, luego usamos el módulo urlopen()para abrir el documento web ese HTML.
En la última línea read(), ayudará a leer el documento línea por línea y asignarlo a la variable nombrada respData .
Código #4:
paragraphs = re.findall(r'<p>(.*?)</p>', str(respData)) for eachP in paragraphs: print(eachP)
Para extraer los datos relevantes, aplicamos expresiones regulares. El segundo argumento debe ser de tipo string y si queremos imprimir los datos, aplicamos la función de impresión simple.
A continuación se muestran algunos ejemplos:
Ejemplo 1:
import urllib.request
import urllib.parse
import re
url = 'https://www.geeksforgeeks.org/'
values = {'s':'python programming',
'submit':'search'}
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
resp = urllib.request.urlopen(req)
respData = resp.read()
paragraphs = re.findall(r'<p>(.*?)</p>',str(respData))
for eachP in paragraphs:
print(eachP)
Producción:
Ejemplo #2:
import urllib.request
import urllib.parse
import re
url = 'https://www.geeksforgeeks.org/'
values = {'s':'pandas',
'submit':'search'}
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
req = urllib.request.Request(url, data)
resp = urllib.request.urlopen(req)
respData = resp.read()
paragraphs = re.findall(r'<p>(.*?)</p>',str(respData))
for eachP in paragraphs:
print(eachP)
Producción: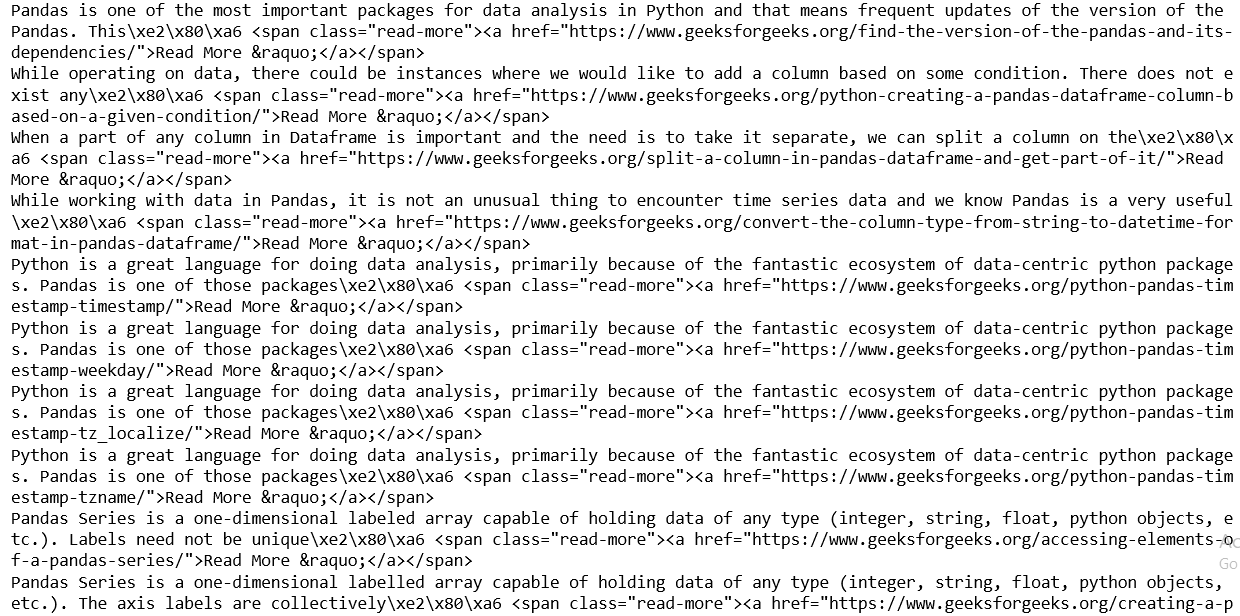
Publicación traducida automáticamente
Artículo escrito por Jitender_1998 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA