Convertir HTML/página web a PDF
Hay muchos sitios web que no permiten descargar el contenido en formato pdf, piden comprar su versión premium o no tienen dicho servicio de descarga en formato pdf.
Conversión en 3 pasos de página web/HTML a PDF
Paso 1: Descarga la biblioteca pdfkit
$ pip install pdfkit
Paso 2: Descargue wkhtmltopdf
para Ubuntu/Debian:
sudo apt-get install wkhtmltopdf
Para Windows:
(a) Enlace de descarga: WKHTMLTOPDF
(b) Conjunto: Carpeta binaria del conjunto de variables PATH en Variables de entorno.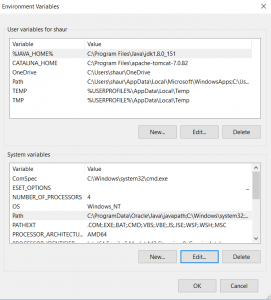
Paso 3: Código en Python para descargar:
(i) Página HTML ya guardada
import pdfkit
pdfkit.from_file('test.html', 'out.pdf')
(ii) Convertir por URL del sitio web
import pdfkit
pdfkit.from_url('https://www.google.co.in/','shaurya.pdf')
(iii) Almacenar texto en PDF
import pdfkit
pdfkit.from_string('Shaurya GFG','GfG.pdf')
Felicitaciones : su archivo pdf se creará y guardará en el mismo directorio donde existe el archivo python.
Contenido de conocimiento misceláneo:
1. Puede pasar una lista con múltiples URL o archivos:
pdfkit.from_url(['google.com', 'geeksforgeeks.org', 'facebook.com'], 'shaurya.pdf') pdfkit.from_file(['file1.html', 'file2.html'], 'out.pdf')
2. Guardar contenido en una variable
# Use False instead of output path to save pdf to a variable
pdf = pdfkit.from_url('http://google.com', False)
Publicación traducida automáticamente
Artículo escrito por shaurya uppal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA