Dada una lista de diccionarios anidados, escriba un programa de Python para crear un marco de datos de Pandas usándolo. Comprendamos el procedimiento paso a paso para crear Pandas Dataframe usando una lista de diccionarios anidados.
Paso #1: Crear una lista de diccionarios anidados.
# importing pandas
import pandas as pd
# List of nested dictionary initialization
list = [
{
"Student": [{"Exam": 90, "Grade": "a"},
{"Exam": 99, "Grade": "b"},
{"Exam": 97, "Grade": "c"},
],
"Name": "Paras Jain"
},
{
"Student": [{"Exam": 89, "Grade": "a"},
{"Exam": 80, "Grade": "b"}
],
"Name": "Chunky Pandey"
}
]
#print(list)
Producción:
Paso n.º 2: agregar valores de dictamen a las filas.
# rows list initialization rows = [] # appending rows for data in list: data_row = data['Student'] time = data['Name'] for row in data_row: row['Name']= time rows.append(row) # using data frame df = pd.DataFrame(rows) # print(df)
Salida: 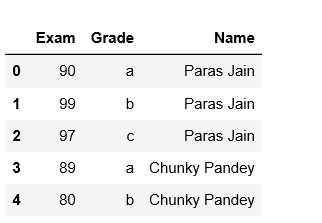
Paso n.º 3: marco de datos dinámico y asignación de nombres de columna.
# using pivot_table df = df.pivot_table(index ='Name', columns =['Grade'], values =['Exam']).reset_index() # Defining columns df.columns =['Name', 'Maths', 'Physics', 'Chemistry'] # print dataframe print(df)
Producción: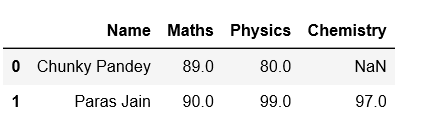
A continuación se muestra el código completo:
# Python program to convert list of nested
# dictionary into Pandas dataframe
# importing pandas
import pandas as pd
# List of list of dictionary initialization
list = [
{
"Student": [{"Exam": 90, "Grade": "a"},
{"Exam": 99, "Grade": "b"},
{"Exam": 97, "Grade": "c"},
],
"Name": "Paras Jain"
},
{
"Student": [{"Exam": 89, "Grade": "a"},
{"Exam": 80, "Grade": "b"}
],
"Name": "Chunky Pandey"
}
]
# rows list initialization
rows = []
# appending rows
for data in list:
data_row = data['Student']
time = data['Name']
for row in data_row:
row['Name']= time
rows.append(row)
# using data frame
df = pd.DataFrame(rows)
# using pivot_table
df = df.pivot_table(index ='Name', columns =['Grade'],
values =['Exam']).reset_index()
# Defining columns
df.columns =['Name', 'Maths', 'Physics', 'Chemistry']
# print dataframe
print(df)
Producción:
Name Maths Physics Chemistry 0 Chunky Pandey 89 80 NaN 1 Paras Jain 90 99 97
Publicación traducida automáticamente
Artículo escrito por everythingispossible y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA