La coincidencia de plantillas es una técnica de procesamiento de imágenes que se utiliza para encontrar la ubicación de piezas pequeñas/plantillas de una imagen grande. Esta técnica se usa ampliamente para proyectos de detección de objetos, como la calidad del producto, el seguimiento de vehículos, la robótica, etc.
En este artículo, aprenderemos cómo usar la coincidencia de plantillas para detectar los campos relacionados en una imagen de documento.
Solución :
la tarea anterior se puede lograr mediante la coincidencia de plantillas. Recorte las imágenes de campo y aplique coincidencias de plantilla utilizando imágenes de campo recortadas y la imagen del documento. El algoritmo es simple pero reproducible en versiones complejas para resolver el problema de detección de campo y localización de imágenes de documentos que pertenecen a dominios específicos.
Enfoque :
- Recorte/Recorte imágenes de campo del documento principal y utilícelas como plantillas separadas.
- Definir/ajustar umbrales para diferentes campos.
- Aplique la coincidencia de plantillas para cada plantilla de campo recortado usando la función OpenCV cv2.matchTemplate()
- Dibuje cuadros delimitadores utilizando las coordenadas de los rectángulos obtenidos de la comparación de plantillas.
- Opcional: aumente las plantillas de campo y ajuste el umbral para mejorar el resultado de diferentes imágenes de documentos.
Imagen de entrada:

Imagen de salida:
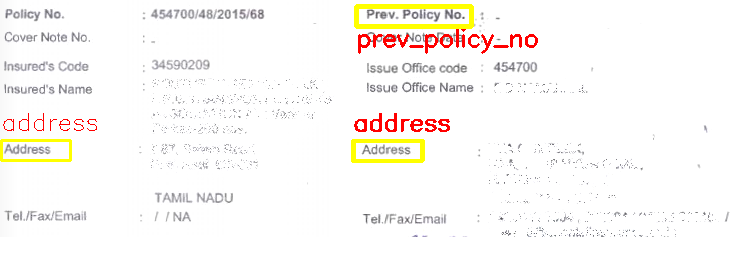
A continuación se muestra el código de Python:
Python3
# importing libraries
import numpy as np
import imutils
import cv2
field_threshold = { "prev_policy_no" : 0.7,
"address" : 0.6,
}
# Function to Generate bounding
# boxes around detected fields
def getBoxed(img, img_gray, template, field_name = "policy_no"):
w, h = template.shape[::-1]
# Apply template matching
res = cv2.matchTemplate(img_gray, template,
cv2.TM_CCOEFF_NORMED)
hits = np.where(res >= field_threshold[field_name])
# Draw a rectangle around the matched region.
for pt in zip(*hits[::-1]):
cv2.rectangle(img, pt, (pt[0] + w, pt[1] + h),
(0, 255, 255), 2)
y = pt[1] - 10 if pt[1] - 10 > 10 else pt[1] + h + 20
cv2.putText(img, field_name, (pt[0], y),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 1)
return img
# Driver Function
if __name__ == '__main__':
# Read the original document image
img = cv2.imread('doc.png')
# 3-d to 2-d conversion
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Field templates
template_add = cv2.imread('doc_address.png', 0)
template_prev = cv2.imread('doc_prev_policy.png', 0)
img = getBoxed(img.copy(), img_gray.copy(),
template_add, 'address')
img = getBoxed(img.copy(), img_gray.copy(),
template_prev, 'prev_policy_no')
cv2.imshow('Detected', img)
Ventajas de usar la coincidencia de plantillas :
- Computacionalmente barato.
- Fácil de usar y modificable para diferentes casos de uso.
- Da buenos resultados en caso de escasez de datos del documento.
Desventajas :
- Los resultados no son muy precisos en comparación con las técnicas de segmentación que utilizan el aprendizaje profundo.
- Carece de resolución de problemas de patrones superpuestos.
Publicación traducida automáticamente
Artículo escrito por Harshit Saini y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA