En este artículo, aprenderemos cómo ejecutar la misma función en paralelo con diferentes parámetros. Podemos ejecutar la misma función en paralelo con diferentes parámetros usando procesamiento paralelo.
El número de tareas realizadas por el programa se puede aumentar mediante el procesamiento en paralelo, lo que reduce el tiempo total de procesamiento. Estos ayudan a abordar problemas a gran escala. Usando el módulo de multiprocesamiento estándar, mediante la creación de procesos secundarios, podemos paralelizar tareas simples de manera efectiva. Este módulo proporciona una interfaz fácil de usar e incluye un conjunto de utilidades de manejo de sincronización y envío de tareas.
Acercarse:
- Podemos construir un proceso que se ejecute de forma independiente subclasificando el proceso de multiprocesamiento. Podemos inicializar el recurso extendiendo el método __init_ y podemos escribir el código para el subproceso implementando el método Process.run(). Vemos cómo construir un proceso en el código a continuación, que imprime la identificación asignada.
- Necesitamos inicializar nuestro objeto de proceso e invocar el método Process.start() para generar el proceso. Aquí, Process.start() creará un nuevo proceso e invocará un método llamado Process.run().
- El código después de p.start() se ejecuta inmediatamente antes de que el proceso p complete la misión. Puede usar Process.join para esperar a que se complete la tarea().
Entendamos esto con algunos ejemplos.
Ejemplo 1:
Python3
import multiprocessing
import time
# Process class
class Process(multiprocessing.Process):
def __init__(self, id):
super(Process, self).__init__()
self.id = id
def run(self):
time.sleep(1)
print("I'm the process with id: {}".format(self.id))
if __name__ == '__main__':
p = Process(0)
# Create a new process and invoke the
# Process.run() method
p.start()
# Process.join() to wait for task completion.
p.join()
p = Process(1)
p.start()
p.join()
Producción:
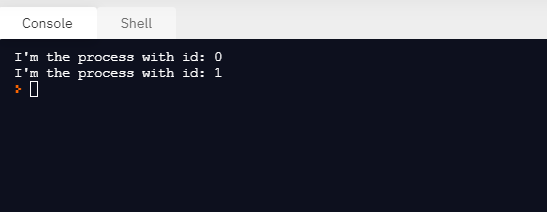
También podemos ejecutar la misma función en paralelo con diferentes parámetros usando la clase Pool. Para el mapeo paralelo, primero tenemos que inicializar el objeto multiprocessing.Pool(). El primer argumento es el número de trabajadores; si no se da, ese número será igual al número de elementos en el sistema.
Ejemplo 2:
Veamos con un ejemplo. En este ejemplo, veremos cómo pasar una función que calcula el cuadrado de un número. Usando Pool.map() podemos mapear la función a la lista y pasar la función y la lista de entradas como argumentos, de la siguiente manera:
Python3
import multiprocessing
import time
# square function
def square(x):
return x * x
if __name__ == '__main__':
# multiprocessing pool object
pool = multiprocessing.Pool()
# pool object with number of element
pool = multiprocessing.Pool(processes=4)
# input list
inputs = [0, 1, 2, 3, 4]
# map the function to the list and pass
# function and input list as arguments
outputs = pool.map(square, inputs)
# Print input list
print("Input: {}".format(inputs))
# Print output list
print("Output: {}".format(outputs))
Producción:
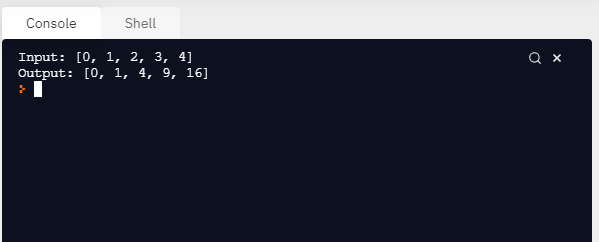
Ejemplo 3:
Python3
from multiprocessing import Pool
def print_range(range):
# print range
print('From {} to {}:'.format(range[0], range[1]))
def run_parallel():
# list of ranges
list_ranges = [[0, 10], [10, 20], [20, 30]]
# pool object with number of elements in the list
pool = Pool(processes=len(list_ranges))
# map the function to the list and pass
# function and list_ranges as arguments
pool.map(print_range, list_ranges)
# Driver code
if __name__ == '__main__':
run_parallel()
Producción:

Publicación traducida automáticamente
Artículo escrito por KapilChhipa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA