Un marco de datos es una estructura de datos bidimensional que tiene varias filas y columnas. En un marco de datos, los datos se alinean solo en forma de filas y columnas. Un marco de datos puede realizar operaciones tanto aritméticas como condicionales. Tiene tamaño mutable.
A continuación se muestra la implementación usando Numpy y Pandas .
Módulos necesarios:
import numpy as np import pandas as pd
Código #1:
Concatenación de tramas de datos
concat()
hace todo el trabajo pesado de realizar operaciones de concatenación a lo largo de un eje mientras realiza una lógica de conjunto opcional (unión o intersección) de los índices (si los hay) en los otros ejes.
# Python program to concatenate
# dataframes using Panda
# Creating first dataframe
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index = [0, 1, 2, 3])
# Creating second dataframe
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index = [4, 5, 6, 7])
# Creating third dataframe
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index = [8, 9, 10, 11])
# Concatenating the dataframes
pd.concat([df1, df2, df3])
Producción:

Código #2: DataFrames Merge
Pandas proporciona una sola función, merge(), como punto de entrada para todas las operaciones estándar de combinación de bases de datos entre objetos DataFrame.
# Python program to merge
# dataframes using Panda
# Dataframe created
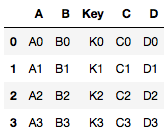
left = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# Merging the dataframes
pd.merge(left, right, how ='inner', on ='Key')
Producción:
Código n.º 3: unión de tramas de datos
# Python program to join
# dataframes using Panda
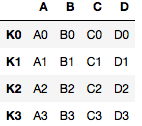
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']},
index = ['K0', 'K1', 'K2', 'K3'])
right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index = ['K0', 'K1', 'K2', 'K3'])
# Joining the dataframes
left.join(right)
Producción:
Publicación traducida automáticamente
Artículo escrito por aishwarya.27 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA