Este artículo habla sobre la construcción de un índice invertido para un sistema de recuperación de información (IR). Sin embargo, en un sistema IR de la vida real, no solo encontramos consultas de una sola palabra (como “perro”, “computadora” o “alex”) sino también consultas de frases (como “se acerca el invierno”, “nueva york”). ”, o “dónde está Kevin”). Para manejar este tipo de consultas, el uso de un índice invertido no es suficiente.
Para comprender mejor la motivación, considere que un usuario consulta «escuela santa maría». Ahora, el índice invertido nos proporcionará una lista de documentos que contienen los términos «santo», «maria» y «escuela» de forma independiente. Sin embargo, lo que en realidad requerimos son documentos en los que aparezca textualmente la frase completa “escuela de santa maría”. Para responder con éxito a tales consultas, necesitamos un índice de documentos que también almacene las posiciones de los términos.
Lista
de publicaciones En el caso del índice invertido, una lista de publicaciones es una lista de documentos donde aparece el término. Por lo general, se ordena por ID de documento y se almacena en forma de lista enlazada.
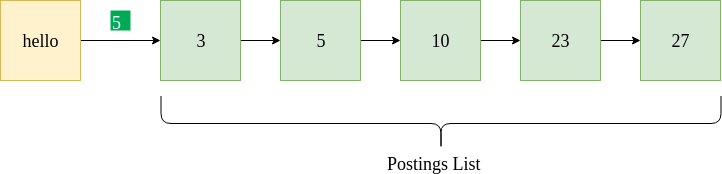
La figura anterior muestra una lista de publicaciones de muestra para el término «hola». Indica que “hola” aparece en documentos con docIDs 3, 5, 10, 23 y 27. También especifica la frecuencia del documento 5 (resaltado en verde). Se proporciona un formato de datos de Python de muestra que contiene un diccionario y listas vinculadas para almacenar la lista de publicaciones.
{"hello" : [5, [3, 5, 10, 23, 27] ] }
En el caso del índice posicional, las posiciones en las que aparece el término en un documento en particular también se almacenan junto con el docID.
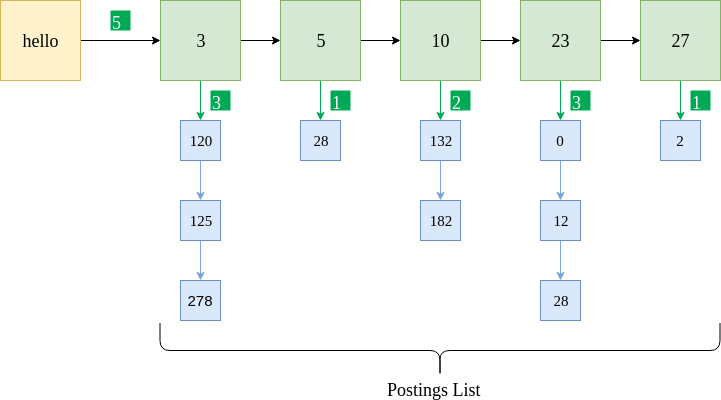
La figura anterior muestra la misma lista de publicaciones implementada para un índice posicional. Los recuadros azules indican la posición del término “hola” en los documentos correspondientes. Por ejemplo, «hola» aparece en el documento 5 en tres posiciones: 120, 125 y 278. Además, la frecuencia del término se almacena para cada documento. Se proporciona un formato de datos de Python de muestra para el mismo.
{"hello" : [5, [ {3 : [3, [120, 125, 278]]}, {5 : [1, [28] ] }, {10 : [2, [132, 182]]}, {23 : [3, [0, 12, 28]]}, {27 : [1, [2]]} ] }
También se puede omitir el término frecuencia en los documentos individuales en aras de la simplicidad (como se hace en el código de ejemplo). El formato de datos entonces se ve como sigue.
{"hello" : [5, {3 : [120, 125, 278]}, {5 : [28]}, {10 : [132, 182]}, {23 : [0, 12, 28]}, {27 : [2]} ] }
Pasos para construir un índice posicional
- Obtener el documento.
- Elimine las palabras vacías, detenga las palabras resultantes.
- Si la palabra ya está presente en el diccionario, agregue el documento y las posiciones correspondientes en las que aparece. De lo contrario, cree una nueva entrada.
- También actualice la frecuencia de la palabra para cada documento, así como el no. de los documentos en los que aparece.
Código
Para implementar un índice posicional, utilizamos un conjunto de datos de muestra llamado «20 grupos de noticias».
Python3
# importing libraries
import numpy as np
import os
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import TweetTokenizer
from natsort import natsorted
import string
def read_file(filename):
with open(filename, 'r', encoding ="ascii", errors ="surrogateescape") as f:
stuff = f.read()
f.close()
# Remove header and footer.
stuff = remove_header_footer(stuff)
return stuff
def remove_header_footer(final_string):
new_final_string = ""
tokens = final_string.split('\n\n')
# Remove tokens[0] and tokens[-1]
for token in tokens[1:-1]:
new_final_string += token+" "
return new_final_string
def preprocessing(final_string):
# Tokenize.
tokenizer = TweetTokenizer()
token_list = tokenizer.tokenize(final_string)
# Remove punctuations.
table = str.maketrans('', '', '\t')
token_list = [word.translate(table) for word in token_list]
punctuations = (string.punctuation).replace("'", "")
trans_table = str.maketrans('', '', punctuations)
stripped_words = [word.translate(trans_table) for word in token_list]
token_list = [str for str in stripped_words if str]
# Change to lowercase.
token_list =[word.lower() for word in token_list]
return token_list
# In this example, we create the positional index for only 1 folder.
folder_names = ["comp.graphics"]
# Initialize the stemmer.
stemmer = PorterStemmer()
# Initialize the file no.
fileno = 0
# Initialize the dictionary.
pos_index = {}
# Initialize the file mapping (fileno -> file name).
file_map = {}
for folder_name in folder_names:
# Open files.
file_names = natsorted(os.listdir("20_newsgroups/" + folder_name))
# For every file.
for file_name in file_names:
# Read file contents.
stuff = read_file("20_newsgroups/" + folder_name + "/" + file_name)
# This is the list of words in order of the text.
# We need to preserve the order because we require positions.
# 'preprocessing' function does some basic punctuation removal,
# stopword removal etc.
final_token_list = preprocessing(stuff)
# For position and term in the tokens.
for pos, term in enumerate(final_token_list):
# First stem the term.
term = stemmer.stem(term)
# If term already exists in the positional index dictionary.
if term in pos_index:
# Increment total freq by 1.
pos_index[term][0] = pos_index[term][0] + 1
# Check if the term has existed in that DocID before.
if fileno in pos_index[term][1]:
pos_index[term][1][fileno].append(pos)
else:
pos_index[term][1][fileno] = [pos]
# If term does not exist in the positional index dictionary
# (first encounter).
else:
# Initialize the list.
pos_index[term] = []
# The total frequency is 1.
pos_index[term].append(1)
# The postings list is initially empty.
pos_index[term].append({})
# Add doc ID to postings list.
pos_index[term][1][fileno] = [pos]
# Map the file no. to the file name.
file_map[fileno] = "20_newsgroups/" + folder_name + "/" + file_name
# Increment the file no. counter for document ID mapping
fileno += 1
# Sample positional index to test the code.
sample_pos_idx = pos_index["andrew"]
print("Positional Index")
print(sample_pos_idx)
file_list = sample_pos_idx[1]
print("Filename, [Positions]")
for fileno, positions in file_list.items():
print(file_map[fileno], positions)
Producción:
Positional Index
[10, {215: [2081], 539: [66], 591: [879], 616: [462, 473], 680: [135], 691: [2081], 714: [4], 809: [333], 979: [0]}]
Filename, [Positions]
20_newsgroups/comp.graphics/38376 [2081]
20_newsgroups/comp.graphics/38701 [66]
20_newsgroups/comp.graphics/38753 [879]
20_newsgroups/comp.graphics/38778 [462, 473]
20_newsgroups/comp.graphics/38842 [135]
20_newsgroups/comp.graphics/38853 [2081]
20_newsgroups/comp.graphics/38876 [4]
20_newsgroups/comp.graphics/38971 [333]
20_newsgroups/comp.graphics/39663 [0]
Publicación traducida automáticamente
Artículo escrito por Anannya Uberoi 1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA