Python se usa ampliamente para analizar los datos, pero los datos no necesitan estar siempre en el formato requerido. En tales casos, convertimos ese formato (como PDF o JPG, etc.) al formato de texto, para poder analizar los datos de una mejor manera. Python ofrece muchas bibliotecas para realizar esta tarea. Hay varias formas de hacerlo, incluido el uso de bibliotecas como PyPDF2 en Python. La principal desventaja de usar estas bibliotecas es el esquema de codificación. Los documentos PDF pueden venir en una variedad de codificaciones, incluidas UTF-8, ASCII, Unicode, etc. Por lo tanto, convertir el PDF a texto puede provocar la pérdida de datos debido al esquema de codificación. Veamos cómo leer todo el contenido de un archivo PDF y almacenarlo en un documento de texto usando OCR. En primer lugar, necesitamos convertir las páginas del PDF en imágenes y luego usar OCR (reconocimiento óptico de caracteres) para leer el contenido de la imagen y almacenarlo en un archivo de texto.
Instalaciones requeridas:
pip3 install PIL pip3 install pytesseract pip3 install pdf2image sudo apt-get install tesseract-ocr
Hay dos partes en el programa de la siguiente manera:
La parte n.º 1 se ocupa de convertir el PDF en archivos de imagen. Cada página del PDF se almacena como un archivo de imagen. Los nombres de las imágenes almacenadas son: PDF página 1 -> página_1.jpg PDF página 2 -> página_2.jpg PDF página 3 -> página_3.jpg …. PDF página n -> página_n.jpg.
La parte n.º 2 trata sobre el reconocimiento de texto de los archivos de imagen y su almacenamiento en un archivo de texto. Aquí, procesamos las imágenes y las convertimos en texto. Una vez que tenemos el texto como una variable de string, podemos realizar cualquier procesamiento en el texto. Por ejemplo, en muchos archivos PDF, cuando se completa una línea, pero una palabra en particular no se puede escribir completamente en la misma línea, se agrega un guión (‘-‘) y la palabra continúa en la siguiente línea. Por ejemplo –
This is some sample text but this parti- cular word could not be written in the same line.
Ahora, para tales palabras, se realiza un procesamiento previo fundamental para convertir el guión y la nueva línea en una palabra completa. Una vez realizado todo el preprocesamiento, este texto se almacena en un archivo de texto separado. Para obtener los archivos PDF de entrada utilizados en el código, haga clic en d.pdf .
A continuación se muestra la implementación:
Python3
# Requires Python 3.6 or higher due to f-strings
# Import libraries
import platform
from tempfile import TemporaryDirectory
from pathlib import Path
import pytesseract
from pdf2image import convert_from_path
from PIL import Image
if platform.system() == "Windows":
# We may need to do some additional downloading and setup...
# Windows needs a PyTesseract Download
# https://github.com/UB-Mannheim/tesseract/wiki/Downloading-Tesseract-OCR-Engine
pytesseract.pytesseract.tesseract_cmd = (
r"C:\Program Files\Tesseract-OCR\tesseract.exe"
)
# Windows also needs poppler_exe
path_to_poppler_exe = Path(r"C:\.....")
# Put our output files in a sane place...
out_directory = Path(r"~\Desktop").expanduser()
else:
out_directory = Path("~").expanduser()
# Path of the Input pdf
PDF_file = Path(r"d.pdf")
# Store all the pages of the PDF in a variable
image_file_list = []
text_file = out_directory / Path("out_text.txt")
def main():
''' Main execution point of the program'''
with TemporaryDirectory() as tempdir:
# Create a temporary directory to hold our temporary images.
"""
Part #1 : Converting PDF to images
"""
if platform.system() == "Windows":
pdf_pages = convert_from_path(
PDF_file, 500, poppler_path=path_to_poppler_exe
)
else:
pdf_pages = convert_from_path(PDF_file, 500)
# Read in the PDF file at 500 DPI
# Iterate through all the pages stored above
for page_enumeration, page in enumerate(pdf_pages, start=1):
# enumerate() "counts" the pages for us.
# Create a file name to store the image
filename = f"{tempdir}\page_{page_enumeration:03}.jpg"
# Declaring filename for each page of PDF as JPG
# For each page, filename will be:
# PDF page 1 -> page_001.jpg
# PDF page 2 -> page_002.jpg
# PDF page 3 -> page_003.jpg
# ....
# PDF page n -> page_00n.jpg
# Save the image of the page in system
page.save(filename, "JPEG")
image_file_list.append(filename)
"""
Part #2 - Recognizing text from the images using OCR
"""
with open(text_file, "a") as output_file:
# Open the file in append mode so that
# All contents of all images are added to the same file
# Iterate from 1 to total number of pages
for image_file in image_file_list:
# Set filename to recognize text from
# Again, these files will be:
# page_1.jpg
# page_2.jpg
# ....
# page_n.jpg
# Recognize the text as string in image using pytesserct
text = str(((pytesseract.image_to_string(Image.open(image_file)))))
# The recognized text is stored in variable text
# Any string processing may be applied on text
# Here, basic formatting has been done:
# In many PDFs, at line ending, if a word can't
# be written fully, a 'hyphen' is added.
# The rest of the word is written in the next line
# Eg: This is a sample text this word here GeeksF-
# orGeeks is half on first line, remaining on next.
# To remove this, we replace every '-\n' to ''.
text = text.replace("-\n", "")
# Finally, write the processed text to the file.
output_file.write(text)
# At the end of the with .. output_file block
# the file is closed after writing all the text.
# At the end of the with .. tempdir block, the
# TemporaryDirectory() we're using gets removed!
# End of main function!
if __name__ == "__main__":
# We only want to run this if it's directly executed!
main()
Salida: Archivo PDF de entrada: Archivo 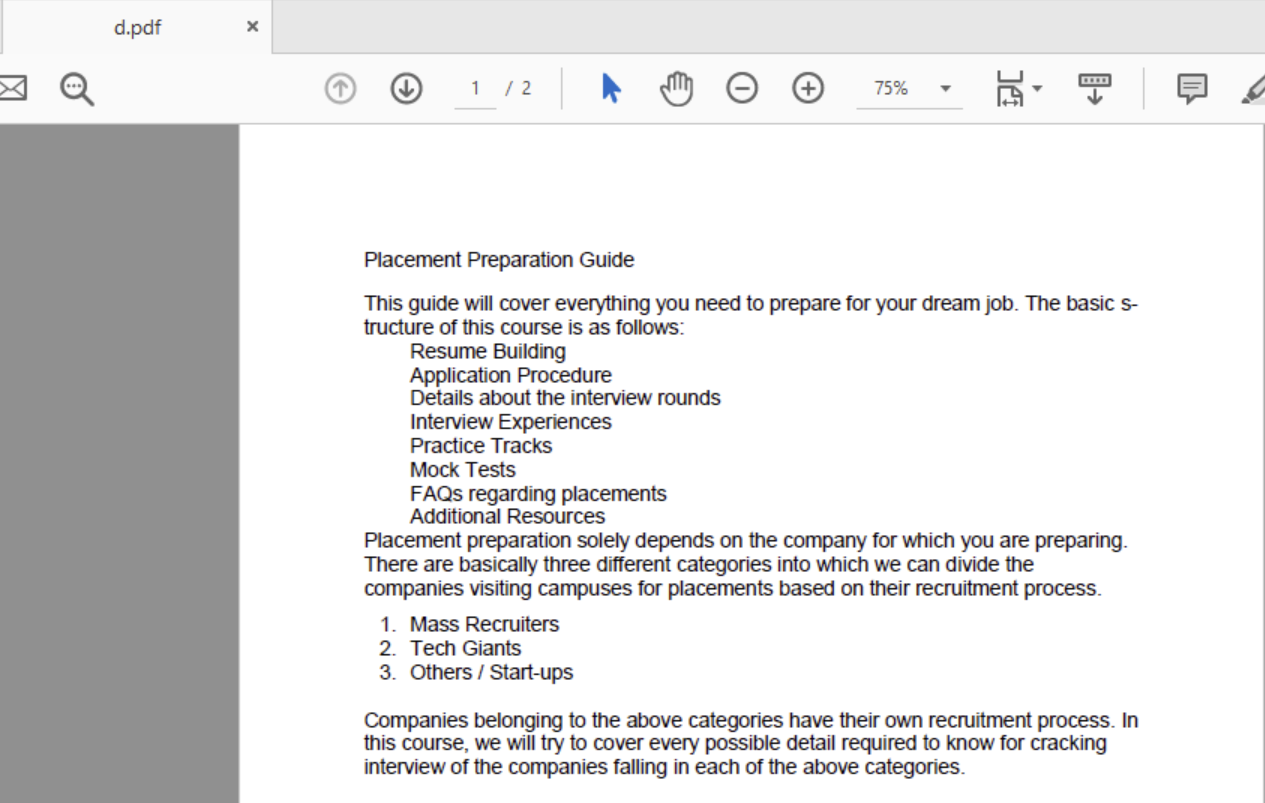 de texto de salida:
de texto de salida: 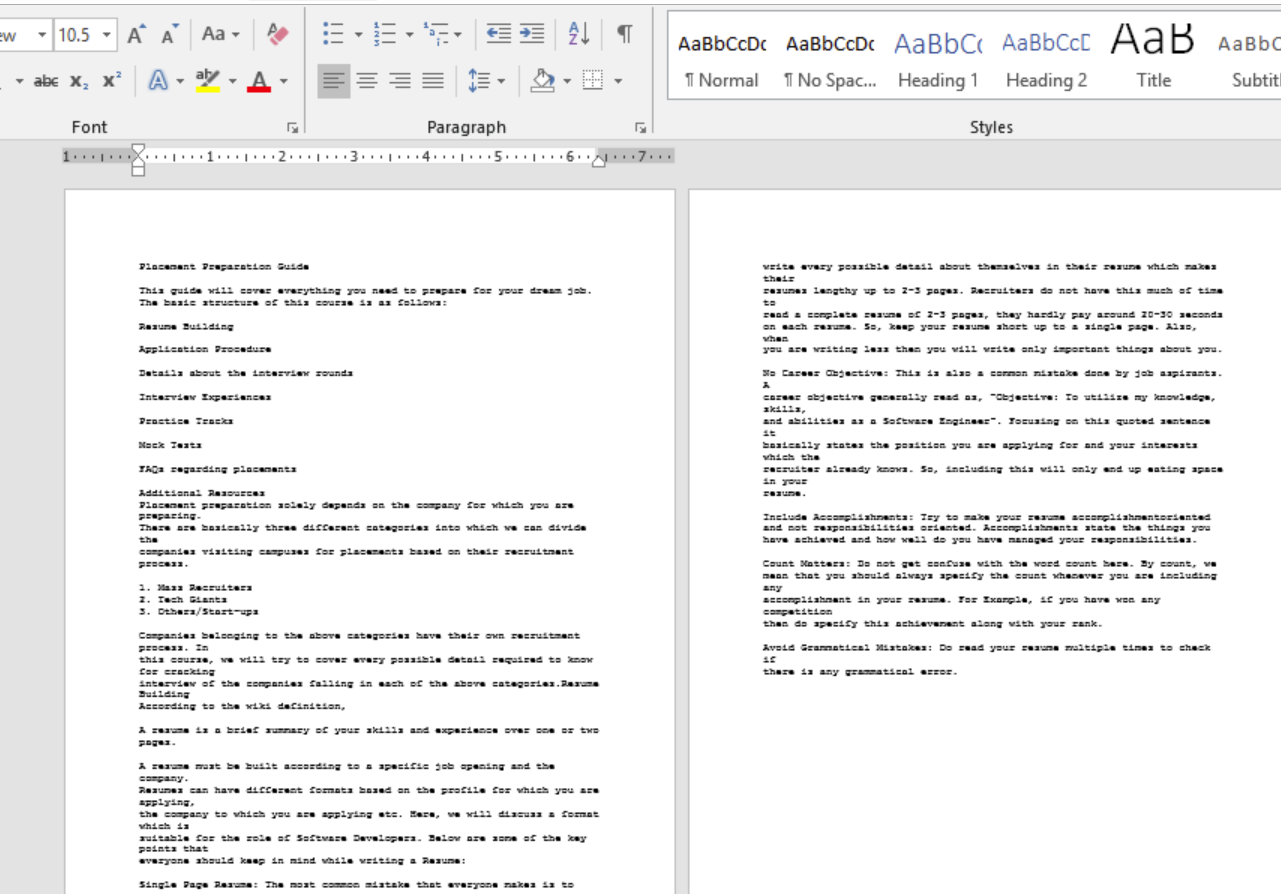 Como vemos, las páginas del PDF se convirtieron en imágenes. Luego se leyeron las imágenes y se escribió el contenido en un archivo de texto. Las ventajas de este método incluyen:
Como vemos, las páginas del PDF se convirtieron en imágenes. Luego se leyeron las imágenes y se escribió el contenido en un archivo de texto. Las ventajas de este método incluyen:
- Evitar la conversión basada en texto debido al esquema de codificación que provoca la pérdida de datos.
- Incluso el contenido escrito a mano en PDF se puede reconocer gracias al uso de OCR.
- También es posible reconocer solo páginas particulares del PDF.
- Obtener el texto como una variable para que se pueda realizar cualquier cantidad de preprocesamiento requerido.
Las desventajas de este método incluyen:
- El almacenamiento en disco se utiliza para almacenar las imágenes en el sistema local. Aunque estas imágenes son diminutas en tamaño.
- El uso de OCR no puede garantizar el 100 % de precisión. Dado un documento PDF TypeScript por computadora, se obtiene una precisión muy alta.
- Los archivos PDF escritos a mano aún se reconocen, pero la precisión depende de varios factores, como la escritura a mano, el color de la página, etc.
Publicación traducida automáticamente
Artículo escrito por AbhijeetSridhar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA