Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas describe()se utiliza para ver algunos detalles estadísticos básicos como percentil, media, estándar, etc. de un marco de datos o una serie de valores numéricos. Cuando este método se aplica a una serie de strings, devuelve una salida diferente que se muestra en los ejemplos a continuación.
Sintaxis: DataFrame.describe(percentiles=Ninguno, incluir=Ninguno, excluir=Ninguno)
Parámetros:
percentil: lista como tipo de datos de números entre 0-1 para devolver el percentil respectivo
incluye: Lista de tipos de datos que se incluirán al describir el marco de datos. El valor predeterminado es Ninguno
excluir: lista de tipos de datos que se excluirán al describir el marco de datos. El valor predeterminado es NingunoTipo de retorno: resumen estadístico del marco de datos.
Para descargar el conjunto de datos utilizado en el siguiente ejemplo, haga clic aquí.
En los siguientes ejemplos, el marco de datos utilizado contiene datos de algunos jugadores de la NBA. La imagen del marco de datos antes de cualquier operación se adjunta a continuación.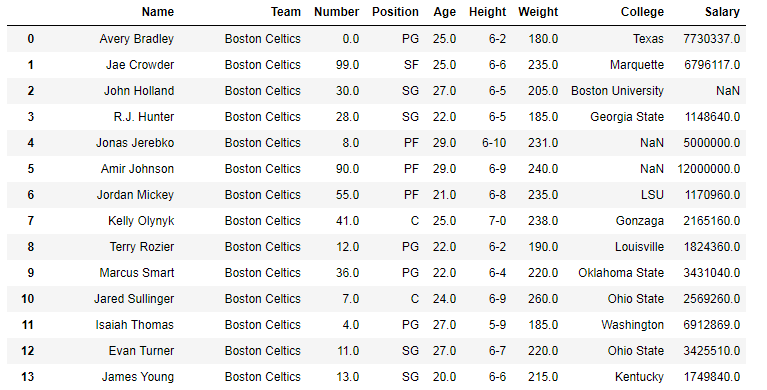
Ejemplo n.º 1: descripción del marco de datos con el tipo de datos de objeto y numérico
En este ejemplo, se describe el marco de datos y se pasa [‘objeto’] para incluir el parámetro para ver la descripción de la serie de objetos. [.20, .40, .60, .80] se pasa al parámetro percentil para ver el percentil respectivo de la serie numérica.
# importing pandas module
import pandas as pd
# importing regex module
import re
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True)
# percentile list
perc =[.20, .40, .60, .80]
# list of dtypes to include
include =['object', 'float', 'int']
# calling describe method
desc = data.describe(percentiles = perc, include = include)
# display
desc
Salida:
como se muestra en la imagen de salida, se devolvió la descripción estadística del marco de datos con los respectivos percentiles pasados. Para las columnas con strings, se devolvió NaN para operaciones numéricas. 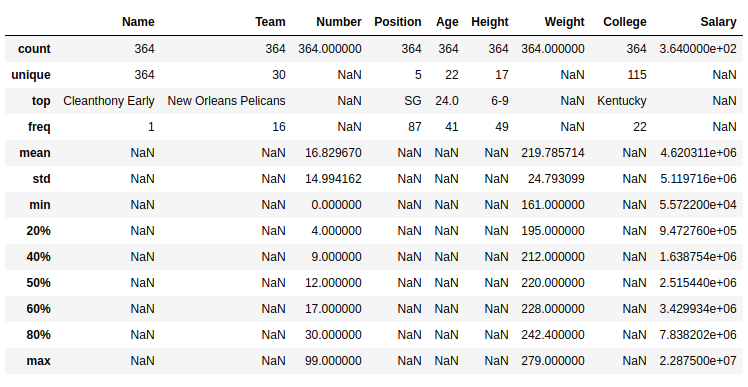
Ejemplo #2: Describiendo una serie de strings
En este ejemplo, la columna Nombre llama al método de descripción para ver el comportamiento con el tipo de datos del objeto.
# importing pandas module
import pandas as pd
# importing regex module
import re
# making data frame
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# removing null values to avoid errors
data.dropna(inplace = True)
# calling describe method
desc = data["Name"].describe()
# display
desc
Salida:
como se muestra en la imagen de salida, el comportamiento de describe() es diferente con series de strings.
Se devolvieron diferentes estadísticas como recuento de valores, valores únicos, top y frecuencia de ocurrencia en este caso.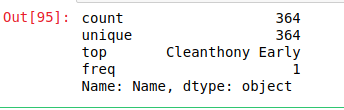
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA