Seaborn es una increíble biblioteca de visualización para el trazado de gráficos estadísticos en Python. Proporciona hermosos estilos predeterminados y paletas de colores para hacer que los gráficos estadísticos sean más atractivos. Está construido en la parte superior de la biblioteca matplotlib y también está estrechamente integrado a las estructuras de datos de pandas .
El método seaborn.factorplot() se utiliza para dibujar un gráfico categórico en un FacetGrid.
Sintaxis: seaborn.factorplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno, fila=Ninguno, col=Ninguno, col_wrap=Ninguno, estimador=, ci=95, n_boot=1000, units=Ninguno, seed =Ninguno, order=Ninguno, hue_order=Ninguno, row_order=Ninguno, col_order=Ninguno, kind=’strip’, height=5, aspect=1, orient=Ninguno, color=Ninguno, palette=Ninguno, legend=True, legend_out =Verdadero, sharex=Verdadero, sharey=Verdadero, margin_titles=False, facet_kws=Ninguno, **kwargs) Parámetros: este método acepta los siguientes parámetros que se describen a continuación:
- x, y : este parámetro toma nombres de variables en datos, Entradas para trazar datos de formato largo.
- matiz: (opcional) Este parámetro toma el nombre de la columna para la codificación de color
- datos: este parámetro toma DataFrame, conjunto de datos de formato largo (ordenado) para trazar. Cada columna debe corresponder a una variable, y cada fila debe corresponder a una observación.
- fila, columna: (opcional) Este parámetro toma nombres de variables en los datos, variables categóricas que determinarán las facetas de la cuadrícula.
- col_wrap: (opcional) Este parámetro toma un valor entero, «Envuelve» la variable de la columna en este ancho, de modo que las facetas de la columna abarquen varias filas. Incompatible con una faceta de fila.
- estimador: (opcional) Este parámetro toma invocable que mapea vector -> escalar, función estadística para estimar dentro de cada contenedor categórico.
- ci : (opcional) Este parámetro toma el valor flotante o “sd” o Ninguno, tamaño de los intervalos de confianza para dibujar valores estimados. Si es «sd», omita el arranque y dibuje la desviación estándar de las observaciones. Si es Ninguno, no se realizará ningún arranque y no se dibujarán barras de error.
- n_boot : (opcional) Este parámetro toma un valor entero, Número de iteraciones de arranque para usar al calcular los intervalos de confianza.
- unidades: (opcional) Este parámetro toma el nombre de la variable en datos o datos vectoriales, Identificador de unidades de muestreo, que se utilizará para realizar un arranque multinivel y dar cuenta del diseño de medidas repetidas.
- seed : (opcional) Este parámetro toma un valor entero, numpy.random.Generator o numpy.random.RandomState, Seed o generador de números aleatorios para un arranque reproducible.
- order, hue_order: (opcional) Este parámetro toma listas de strings, Order para trazar los niveles categóricos, de lo contrario, los niveles se infieren de los objetos de datos.
- row_order, col_order: (opcional) Este parámetro toma listas de strings, Order para organizar las filas y/o columnas de la cuadrícula, de lo contrario, los órdenes se infieren de los objetos de datos.
- tipo: (opcional) Este parámetro toma valor de string, el tipo de gráfico a dibujar (corresponde al nombre de una función de gráfico categórica. Las opciones son: «punto», «barra», «tira», «enjambre», «caja» , “violín” o “caja”.
- altura: (opcional) Este parámetro toma el valor flotante, Altura (en pulgadas) de cada faceta.
- aspecto: (opcional) este parámetro toma el valor flotante, la relación de aspecto de cada faceta, de modo que el aspecto * la altura da el ancho de cada faceta en pulgadas.
- orient : (opcional) Este parámetro toma valor que debería ser “v” | “h”, Orientación de la parcela (vertical u horizontal). Esto generalmente se deduce del tipo de las variables de entrada, pero se puede usar para especificar cuándo la variable «categórica» es numérica o cuando se grafican datos de formato ancho.
- color : (opcional) Este parámetro toma matplotlib color, Color para todos los elementos o semilla para una paleta de degradado.
- paleta: (opcional) Este parámetro toma el nombre de la paleta, lista o dictado, Colores para usar para los diferentes niveles de la variable de tono. Debería ser algo que pueda ser interpretado por color_palette(), o un diccionario que mapee los niveles de tono a los colores matplotlib.
- Leyenda: (opcional) Este parámetro toma un valor booleano, si es verdadero y hay una variable de matiz, dibuja una leyenda en el gráfico.
- legend_out: (opcional) Este parámetro toma un valor booleano. Si es verdadero, el tamaño de la figura se ampliará y la leyenda se dibujará fuera del gráfico en el centro a la derecha.
- share{x, y} : (opcional) Este parámetro toma bool, ‘col’ o ‘row’. Si es verdadero, las facetas compartirán ejes y entre columnas y/o ejes x entre filas.
- margin_titles: (opcional) este parámetro toma un valor booleano, si es verdadero, los títulos de la variable de fila se dibujan a la derecha de la última columna. Esta opción es experimental y puede no funcionar en todos los casos.
- facet_kws: (opcional) este parámetro toma el objeto del diccionario, el diccionario de otros argumentos de palabras clave para pasar a FacetGrid.
- kwargs : este parámetro toma clave, pares de valores, otros argumentos de palabras clave se pasan a través de la función de trazado subyacente.
Devoluciones: este método devuelve el objeto FacetGrid con el gráfico para realizar más ajustes.
Nota: Para descargar el conjunto de datos de Consejos, haga clic aquí . Los siguientes ejemplos ilustran el método factorplot() de la biblioteca seaborn. Ejemplo 1 :
Python3
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# point plot(by default)
sns.factorplot(x ='size', y ='tip', data = df)
# Show the plot
plt.show()
Salida: 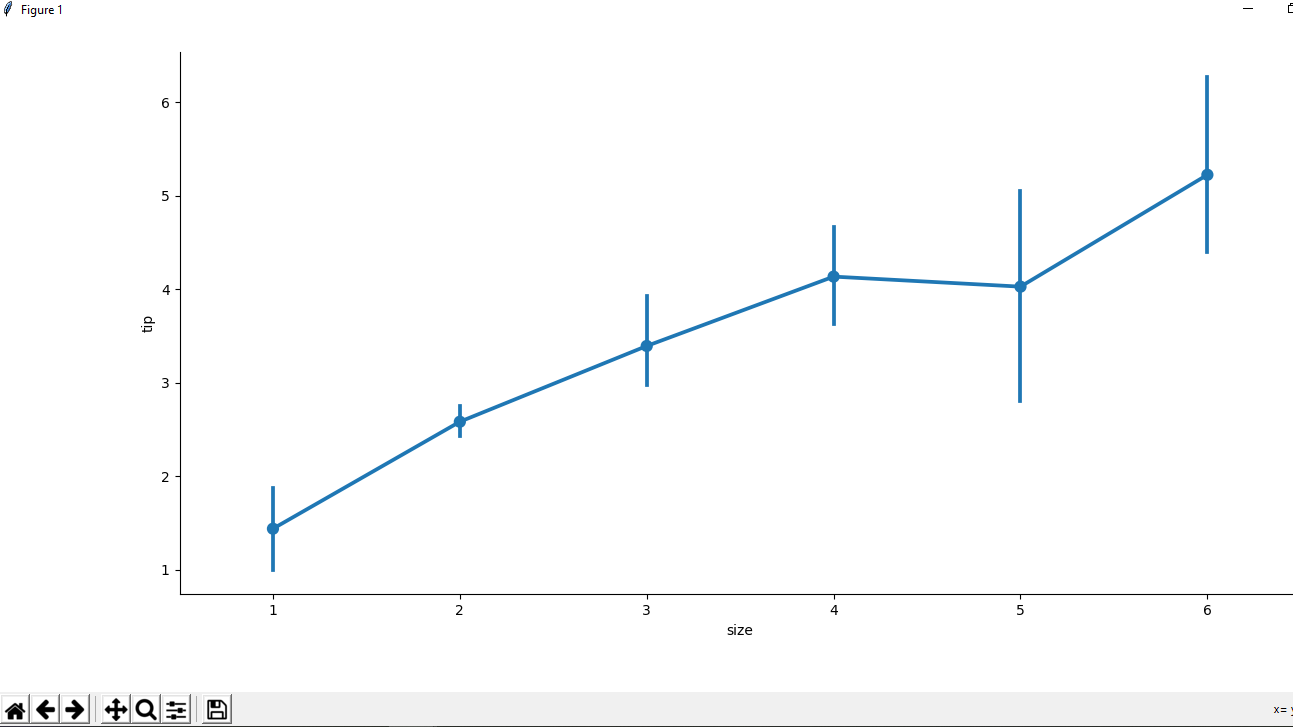 Ejemplo 2:
Ejemplo 2:
Python3
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
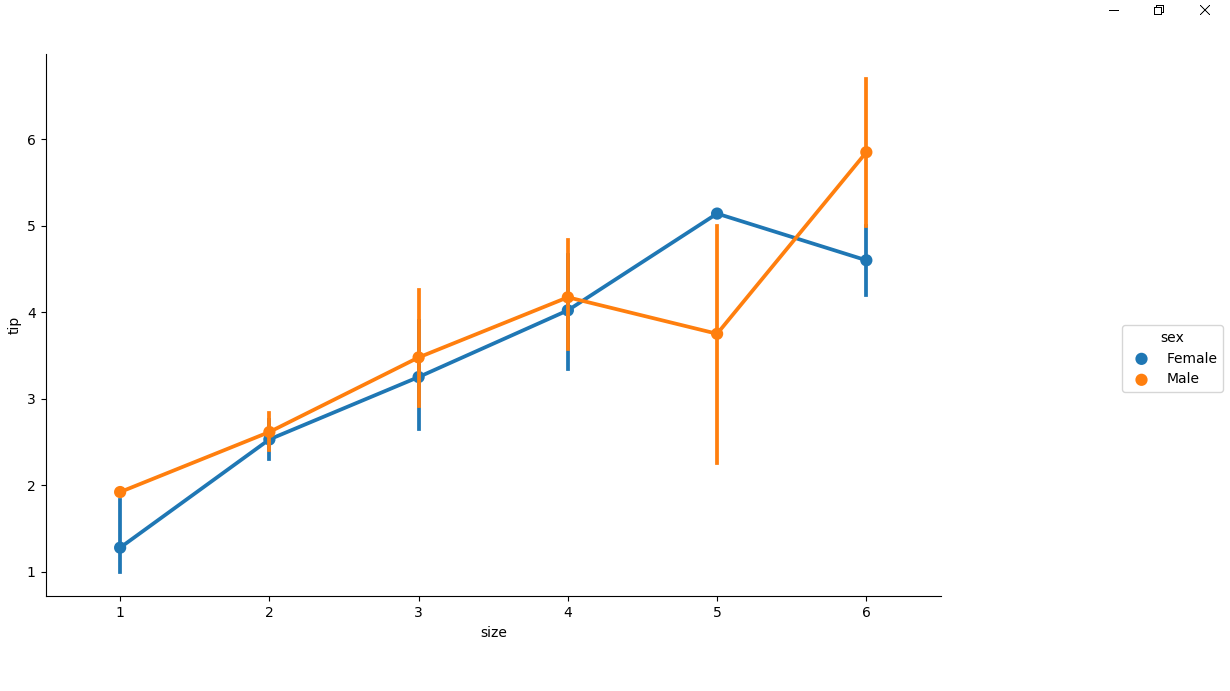
# point plot using hue attribute
# for colouring out points
# according to the sex
sns.factorplot(x ='size', y ='tip',
hue = 'sex', data = df)
# Show the plot
plt.show()
Producción :