Seaborn es una increíble biblioteca de visualización para el trazado de gráficos estadísticos en Python. Proporciona hermosos estilos predeterminados y paletas de colores para hacer que los gráficos estadísticos sean más atractivos. Está construido en la parte superior de la biblioteca matplotlib y también está estrechamente integrado a las estructuras de datos de pandas .
método seaborn.Implot()
El método seaborn.lmplot() se utiliza para dibujar un diagrama de dispersión en un FacetGrid.
Sintaxis: seaborn.lmplot(x, y, data, hue=Ninguno, col=Ninguno, fila=Ninguno, palette=Ninguno, col_wrap=Ninguno, height=5, aspect=1, markers=’o’, sharex=True, sharey=Verdadero, hue_order=Ninguno, col_order=Ninguno, row_order=Ninguno, legend=True, legend_out=True, x_estimator=Ninguno, x_bins=Ninguno, x_ci=’ci’, scatter=True, fit_reg=True, ci=95, n_boot=1000, units=Ninguno, semilla=Ninguno, orden=1, logística=Falso, más bajo=Falso, robusto=Falso, logx=Falso, x_parcial=Ninguno, y_parcial=Ninguno, truncar=Verdadero, x_jitter=Ninguno, y_jitter= Ninguno, scatter_kws=Ninguno, line_kws=Ninguno, tamaño=Ninguno)
Parámetros: este método acepta los siguientes parámetros que se describen a continuación:
- x, y : (opcional) Estos parámetros son nombres de columna en los datos.
- data: Este parámetro es DataFrame.
- tono, col, fila: estos parámetros definen subconjuntos de los datos, que se dibujarán en facetas separadas en la cuadrícula. Consulte los parámetros *_order para controlar el orden de los niveles de esta variable.
- paleta : (opcional) Este parámetro es el nombre de la paleta, la lista o el dictado, los colores que se usarán para los diferentes niveles de la variable de tono. Debería ser algo que pueda ser interpretado por color_palette(), o un diccionario que mapee los niveles de tono a los colores matplotlib.
- col_wrap : (opcional) Este parámetro es de tipo int, «Envuelve» la variable de columna en este ancho, de modo que las facetas de la columna abarquen varias filas. Incompatible con una faceta de fila.
- altura: (opcional) Este parámetro es la altura (en pulgadas) de cada faceta.
- aspecto: (opcional) Este parámetro es la relación de aspecto de cada faceta, por lo que aspecto * altura da el ancho de cada faceta en pulgadas.
- marcadores: (opcional) Este parámetro es el código de marcador de matplotlib o una lista de códigos de marcador, Marcadores para el diagrama de dispersión. Si es una lista, cada marcador de la lista se utilizará para cada nivel de la variable de matiz.
- share{x, y} : (opcional) Este parámetro es de tipo bool, ‘col’ o ‘row’. Si es verdadero, las facetas compartirán ejes y entre columnas y/o ejes x entre filas.
- {hue, col, row}_order : (opcional) Este parámetro enumera, ordena los niveles de las variables de facetado. Por defecto, este será el orden en que aparecen los niveles en los datos o, si las variables son pandas categóricas, el orden de categoría.
- Leyenda: (opcional) Este parámetro acepta valor booleano, si es verdadero y hay una variable de matiz, agregue una leyenda.
- legend_out: (opcional) Este parámetro acepta el valor bool. Si es verdadero, el tamaño de la figura se ampliará y la leyenda se dibujará fuera del gráfico en el centro a la derecha.
- x_estimator: (opcional) Este parámetro es invocable y mapea vector -> escalar. Aplique esta función a cada valor único de x y trace la estimación resultante. Esto es útil cuando x es una variable discreta. Si se proporciona x_ci, esta estimación se pondrá en marcha y se dibujará un intervalo de confianza.
- x_bins : (opcional) Este parámetro es int o vector, agrupa la variable x en contenedores discretos y luego estima la tendencia central y un intervalo de confianza. Este agrupamiento solo influye en cómo se dibuja el diagrama de dispersión; la regresión aún se ajusta a los datos originales. Este parámetro se interpreta como el número de contenedores de tamaño uniforme (no necesariamente espaciados) o las posiciones de los centros de los contenedores. Cuando se usa este parámetro, implica que el valor predeterminado de x_estimator es numpy.mean.
- x_ci : (opcional) Este parámetro es “ci”, “sd”, int en [0, 100] o Ninguno, Tamaño del intervalo de confianza utilizado al trazar una tendencia central para valores discretos de x. Si es “ci”, refiera al valor del parámetro ci. Si es «sd», omita el arranque y muestre la desviación estándar de las observaciones en cada contenedor.
- scatter: (opcional) Este parámetro acepta valor bool. Si es Verdadero, dibuje un diagrama de dispersión con las observaciones subyacentes (o los valores de x_estimator).
- fit_reg: (opcional) Este parámetro acepta valor bool. Si es Verdadero, estime y trace un modelo de regresión que relacione las variables x e y.
- ci : (opcional) Este parámetro es int en [0, 100] o Ninguno, Tamaño del intervalo de confianza para la estimación de regresión. Esto se dibujará usando bandas translúcidas alrededor de la línea de regresión. El intervalo de confianza se estima utilizando un bootstrap; para grandes conjuntos de datos, puede ser recomendable evitar ese cálculo configurando este parámetro en Ninguno.
- n_boot: (opcional) este parámetro es el número de remuestreos de arranque utilizados para estimar el ci. El valor predeterminado intenta equilibrar el tiempo y la estabilidad; es posible que desee aumentar este valor para las versiones «finales» de los gráficos.
- unidades: (opcional) Este parámetro es el nombre de la variable en los datos. Si las observaciones x e y están anidadas dentro de las unidades de muestreo, se pueden especificar aquí. Esto se tendrá en cuenta al calcular los intervalos de confianza mediante la realización de un arranque multinivel que vuelva a muestrear tanto las unidades como las observaciones (dentro de la unidad). De lo contrario, esto no influye en cómo se estima o dibuja la regresión.
- seed : (opcional) Este parámetro es int, numpy.random.Generator o numpy.random.RandomState, Seed o generador de números aleatorios para un arranque reproducible.
- orden: (opcional) este parámetro, el orden es mayor que 1, use numpy.polyfit para estimar una regresión polinomial.
- logistic : (opcional) este parámetro acepta valor bool, si es verdadero, suponga que y es una variable binaria y use statsmodels para estimar un modelo de regresión logística. Tenga en cuenta que esto es sustancialmente más intensivo desde el punto de vista computacional que la regresión lineal, por lo que es posible que desee disminuir la cantidad de remuestreos de arranque (n_boot) o establecer ci en Ninguno.
- más bajo: (opcional) Este parámetro acepta el valor booleano. Si es verdadero, use statsmodels para estimar un modelo más bajo no paramétrico (regresión lineal ponderada localmente). Tenga en cuenta que actualmente no se pueden dibujar intervalos de confianza para este tipo de modelo.
- robusto: (opcional) Este parámetro acepta el valor booleano. Si es verdadero, use statsmodels para estimar una regresión robusta. Esto reducirá el peso de los valores atípicos. Tenga en cuenta que esto es sustancialmente más intensivo desde el punto de vista computacional que la regresión lineal estándar, por lo que es posible que desee disminuir la cantidad de remuestreos de arranque (n_boot) o establecer ci en Ninguno.
- logx: (opcional) Este parámetro acepta valor bool. Si es Verdadero, estime una regresión lineal de la forma y ~ log(x), pero trace el diagrama de dispersión y el modelo de regresión en el espacio de entrada. Tenga en cuenta que x debe ser positivo para que esto funcione.
- {x, y}_partial: (opcional) este parámetro son strings en datos o arrays, variables de confusión para retroceder de las variables x o y antes de trazar.
- truncar: (opcional) este parámetro acepta valor bool. Si es verdadero, la línea de regresión está delimitada por los límites de datos. Si es False, se extiende a los límites del eje x.
- {x, y}_jitter: (opcional) Este parámetro es Agregar ruido aleatorio uniforme de este tamaño a las variables x o y. El ruido se agrega a una copia de los datos después de ajustar la regresión y solo influye en el aspecto del diagrama de dispersión. Esto puede ser útil cuando se grafican variables que toman valores discretos.
- {dispersión, línea}_kws: (opcional) diccionarios
Devoluciones: este método devuelve el objeto FacetGrid con el gráfico para realizar más ajustes.
Nota: Para descargar el conjunto de datos de Consejos , haga clic aquí .
Los siguientes ejemplos ilustran el método lmplot() de la biblioteca seaborn.
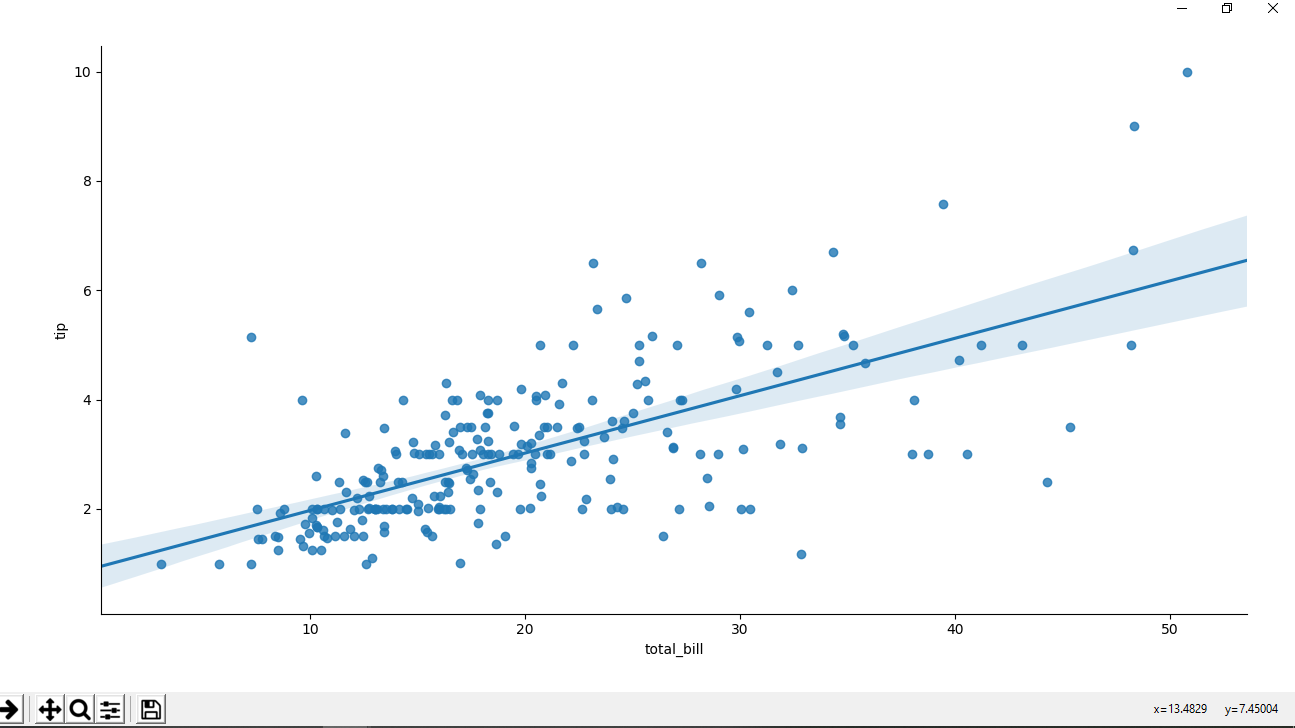
Ejemplo 1: diagrama de dispersión con línea de regresión (por defecto).
Python3
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# scatter plot with regression
# line(by default)
sns.lmplot(x ='total_bill', y ='tip', data = df)
# Show the plot
plt.show()
Producción :
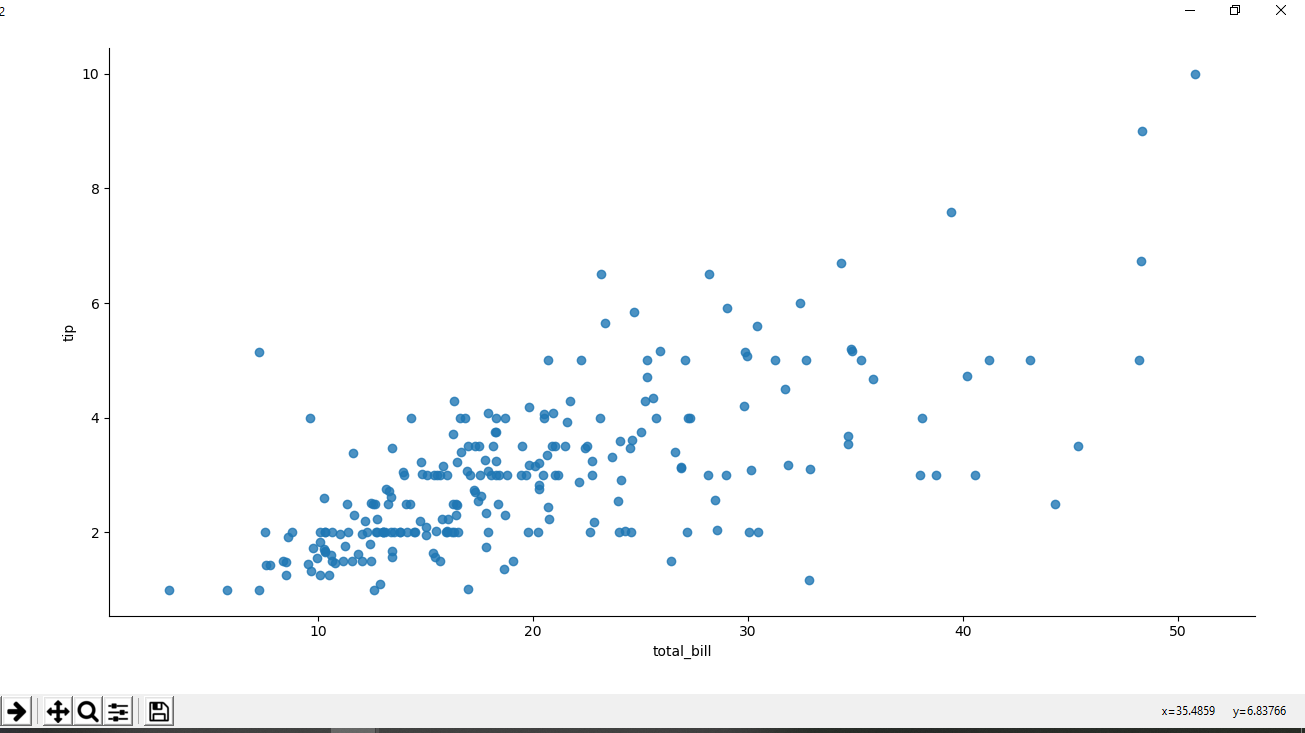
Ejemplo 2: Diagrama de dispersión sin línea de regresión.
Python3
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# scatter plot without regression
# line.
sns.lmplot(x ='total_bill', y ='tip',
fit_reg = False, data = df)
# Show the plot
plt.show()
Producción :
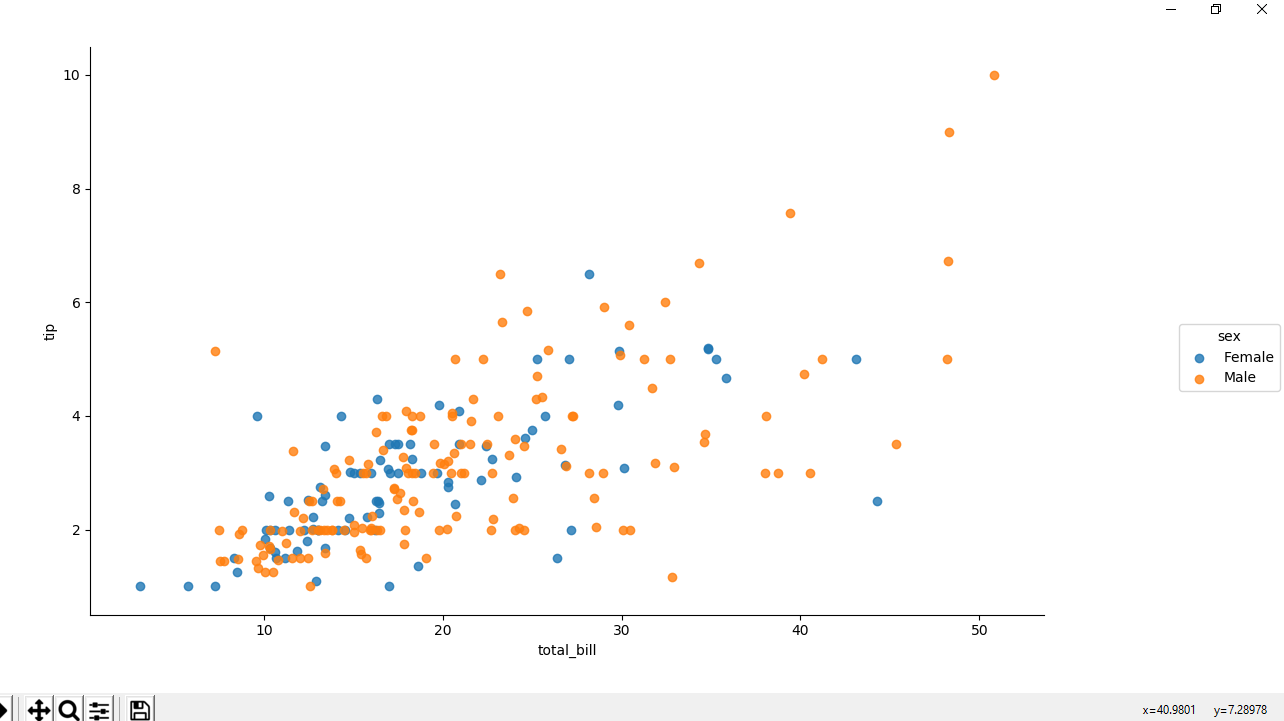
Ejemplo 3: Diagrama de dispersión usando el atributo hue para colorear puntos según el sexo.
Python3
# importing the required library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# read a csv file
df = pd.read_csv('Tips.csv')
# scatter plot using hue attribute
# for colouring out points
# according to the sex
sns.lmplot(x ='total_bill', y ='tip',
fit_reg = False, hue = 'sex',
data = df)
# Show the plot
plt.show()
Producción :