La mayoría de los datos extraídos de la web a través del raspado están en forma de tipo de datos JSON porque JSON es un tipo de datos preferido para transmitir datos en aplicaciones web. La razón por la que se prefiere JSON es que es extremadamente liviano para enviar y recibir requests y respuestas HTTP debido al tamaño pequeño del archivo.
Tal archivo JSON a veces puede ser complicado al tener diferentes niveles y jerarquías. Dichos formatos de datos sin procesar no se pueden utilizar para un procesamiento posterior. Es una práctica general convertir la estructura de datos JSON en un marco de datos de Pandas, ya que puede ayudar a manipular y visualizar los datos de manera más conveniente. En este artículo, consideremos diferentes estructuras de datos JSON anidadas y aplanémoslas usando funciones integradas y definidas de forma personalizada.
Pandas tiene una buena función incorporada llamada json_normalize() para aplanar las estructuras JSON anidadas simples a moderadamente semiestructuradas en tablas planas.
Sintaxis: pandas.json_normalize(datos, errores=’aumentar’, sep=’.’, max_level=Ninguno)
Parámetros:
- data – dict o lista de dicts
- errores – {‘aumentar’, ‘ignorar’}, predeterminado ‘aumentar’
- sep – str, por defecto ‘.’ los registros anidados generarán nombres separados por un separador específico.
- max_level – int, predeterminado Ninguno. Número máximo de niveles (profundidad de dict) para normalizar.
Ejemplo 1:
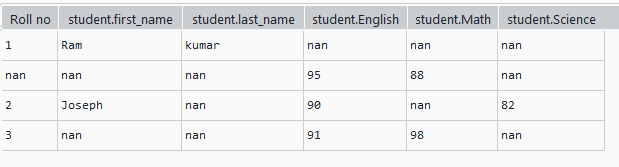
Considere una lista de diccionarios anidados que contiene detalles sobre los estudiantes y sus calificaciones, como se muestra. Use pandas json_normalize en esta estructura de datos JSON para aplanarlo en una tabla plana como se muestra
Python3
import pandas as pd
data = [
{"Roll no": 1,
"student": {"first_name": "Ram", "last_name": "kumar"}
},
{"student": {"English": "95", "Math": "88"}
},
{"Roll no": 2,
"student": {"first_name": "Joseph", "English": "90", "Science": "82"}
},
{"Roll no": 3,
"student": {"first_name": "abinaya", "last_name": "devi"},
"student": {"English": "91", "Math": "98"}
},
]
df = pd.json_normalize(data)
print(df)
Producción:
Ejemplo 2:
Ahora hagamos uso de la opción max_level para aplanar una estructura JSON ligeramente complicada en una tabla plana. Para este ejemplo, hemos considerado el max_level de 0 , lo que significa aplanar solo el primer nivel de JSON y poder experimentar con los resultados.
Aquí, hemos considerado un ejemplo de los registros de salud de diferentes personas en formato JSON.
Python3
import pandas as pd
data = [
{
"id": 1,
"candidate": "Roberto mathews",
"health_index": {"bmi": 22, "blood_pressure": 130},
},
{"candidate": "Shane wade", "health_index": {"bmi": 28, "blood_pressure": 160}},
{
"id": 2,
"candidate": "Bruce tommy",
"health_index": {"bmi": 31, "blood_pressure": 190},
},
]
pd.json_normalize(data, max_level=0)
Producción:
Como hemos usado solo 1 nivel de aplanamiento, el segundo nivel se retiene como un par clave-valor como se muestra

Ejemplo 3:
Ahora usemos la misma estructura de datos JSON que la anterior, con max_level de 1, lo que significa aplanar los dos primeros niveles de JSON y poder experimentar con los resultados.
Python3
import pandas as pd
data = [
{
"id": 1,
"candidate": "Roberto mathews",
"health_index": {"bmi": 22, "blood_pressure": 130},
},
{"candidate": "Shane wade", "health_index": {"bmi": 28, "blood_pressure": 160}},
{
"id": 2,
"candidate": "Bruce tommy",
"health_index": {"bmi": 31, "blood_pressure": 190},
},
]
pd.json_normalize(data, max_level=1)
Producción:
Aquí, a diferencia del ejemplo anterior, aplanamos las dos primeras filas del JSON, lo que proporciona una estructura completa para la tabla plana.

Ejemplo 4:
Finalmente, consideremos una estructura JSON profundamente anidada que se puede convertir en una tabla plana pasando los metaargumentos a la función json_normalize como se muestra a continuación.
Aquí, en el siguiente código, hemos pasado el orden cronológico en el que se debe analizar el JSON a una tabla plana. En el siguiente código, primero sugerimos que se analice la clave del departamento seguida de la empresa y el eslogan, luego, pasamos la clave de la gerencia y del director ejecutivo como una lista anidada que indica que deben analizarse como un solo campo.
Python3
import pandas as pd
data = [
{
"company": "Google",
"tagline": "Dont be evil",
"management": {"CEO": "Sundar Pichai"},
"department": [
{"name": "Gmail", "revenue (bn)": 123},
{"name": "GCP", "revenue (bn)": 400},
{"name": "Google drive", "revenue (bn)": 600},
],
},
{
"company": "Microsoft",
"tagline": "Be What's Next",
"management": {"CEO": "Satya Nadella"},
"department": [
{"name": "Onedrive", "revenue (bn)": 13},
{"name": "Azure", "revenue (bn)": 300},
{"name": "Microsoft 365", "revenue (bn)": 300},
],
},
]
result = pd.json_normalize(
data, "department", ["company", "tagline", ["management", "CEO"]]
)
result
Producción:

Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA