Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.append()se usa para agregar filas de otro marco de datos al final del marco de datos dado, devolviendo un nuevo objeto de marco de datos. Las columnas que no están en los marcos de datos originales se agregan como nuevas columnas y las nuevas celdas se llenan con NaNvalor.
Sintaxis: DataFrame.append(otro, ignore_index=Falso, verificar_integridad=Falso, ordenar=Ninguno)
Parámetros:
otro: marco de datos o serie/objeto similar a un dictado, o una lista de estos
ignore_index: si es verdadero, no use las etiquetas de índice.
verificar_integridad: si es verdadero, genera ValueError al crear un índice con duplicados.
sort : ordena las columnas si las columnas de self y other no están alineadas. La clasificación predeterminada está en desuso y cambiará a no clasificar en una versión futura de pandas. Pase explícitamente sort=True para silenciar la advertencia y ordenar. Pase explícitamente sort=False para silenciar la advertencia y no ordenar.Devoluciones: adjunto: DataFrame
Ejemplo n.º 1: Cree dos marcos de datos y agregue el segundo al primero.
# Importing pandas as pd
import pandas as pd
# Creating the first Dataframe using dictionary
df1 = df = pd.DataFrame({"a":[1, 2, 3, 4],
"b":[5, 6, 7, 8]})
# Creating the Second Dataframe using dictionary
df2 = pd.DataFrame({"a":[1, 2, 3],
"b":[5, 6, 7]})
# Print df1
print(df1, "\n")
# Print df2
df2
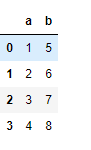
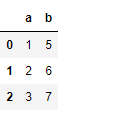
Ahora agregue df2 al final de df1.
# to append df2 at the end of df1 dataframe df1.append(df2)
Salida:
observe que el valor de índice del segundo marco de datos se mantiene en el marco de datos adjunto. Si no queremos que suceda, podemos configurar ignore_index=True.
# A continuous index value will be maintained # across the rows in the new appended data frame. df1.append(df2, ignore_index = True)

Salida: 
Ejemplo n. ° 2: agregar un marco de datos de forma diferente.
Por desigual no. de columnas en el marco de datos, el valor inexistente en uno de los marcos de datos se llenará con NaNvalores.
# Importing pandas as pd
import pandas as pd
# Creating the first Dataframe using dictionary
df1 = pd.DataFrame({"a":[1, 2, 3, 4],
"b":[5, 6, 7, 8]})
# Creating the Second Dataframe using dictionary
df2 = pd.DataFrame({"a":[1, 2, 3],
"b":[5, 6, 7],
"c":[1, 5, 4]})
# for appending df2 at the end of df1
df1.append(df2, ignore_index = True)
Producción :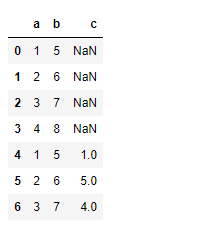
Observe que las nuevas celdas se rellenan con NaNvalores.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA