Pandas DataFrame es una estructura de datos tabulares potencialmente heterogénea, de tamaño mutable, bidimensional con ejes etiquetados (filas y columnas). Las operaciones aritméticas se alinean en las etiquetas de fila y columna. Se puede considerar como un contenedor similar a un dictado para objetos Series. Esta es la estructura de datos principal de Pandas.
El atributo Pandas DataFrame.blockses sinónimo de as_blocks()función. Básicamente, convierte el marco en un dict de dtype -> Tipos de constructores que cada uno tiene un dtype homogéneo.
Sintaxis: DataFrame.blocks
Parámetro: Ninguno
Devoluciones: dict
Ejemplo n.º 1: use DataFrame.blocksel atributo para devolver un diccionario que contenga los datos en bloques de tipos de datos separados.
# importing pandas as pd
import pandas as pd
# Creating the DataFrame
df = pd.DataFrame({'Weight':[45, 88, 56, 15, 71],
'Name':['Sam', 'Andrea', 'Alex', 'Robin', 'Kia'],
'Age':[14, 25, 55, 8, 21]})
# Create the index
index_ = ['Row_1', 'Row_2', 'Row_3', 'Row_4', 'Row_5']
# Set the index
df.index = index_
# Print the DataFrame
print(df)
Producción :
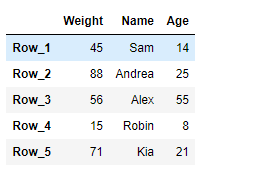
Ahora usaremos DataFrame.blocksel atributo para devolver la representación de bloque del marco de datos dado.
# return a dictionary result = df.blocks # Print the result print(result)
Producción :

Como podemos ver en la salida, el DataFrame.blocksatributo ha devuelto con éxito un diccionario que contiene los datos del marco de datos. Las columnas homogéneas son lugares en el mismo bloque.
Ejemplo n.º 2: use DataFrame.blocksel atributo para devolver un diccionario que contenga los datos en bloques de tipos de datos separados.
# importing pandas as pd
import pandas as pd
# Creating the DataFrame
df = pd.DataFrame({"A":[12, 4, 5, None, 1],
"B":[7, 2, 54, 3, None],
"C":[20, 16, 11, 3, 8],
"D":[14, 3, None, 2, 6]})
# Create the index
index_ = ['Row_1', 'Row_2', 'Row_3', 'Row_4', 'Row_5']
# Set the index
df.index = index_
# Print the DataFrame
print(df)
Producción :
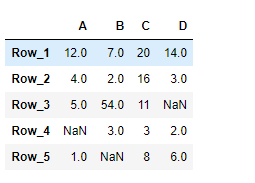
Ahora usaremos DataFrame.blocksel atributo para devolver la representación de bloque del marco de datos dado.
# return a dictionary result = df.blocks # Print the result print(result)
Producción :

Como podemos ver en la salida, el DataFrame.blocksatributo ha devuelto con éxito un diccionario que contiene los datos del marco de datos. Las columnas homogéneas son lugares en el mismo bloque.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA