Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas dataframe.cov()se utiliza para calcular la covarianza de las columnas por pares .
Si algunas de las celdas de una columna contienen NaNvalor, se ignora.
Sintaxis: DataFrame.cov(min_periods=Ninguno)
Parámetros:
min_periods : Número mínimo de observaciones requeridas por par de columnas para tener un resultado válido.Devuelve: y : trama de datos
Ejemplo #1: Use cov()la función para encontrar la covarianza entre las columnas del marco de datos.
Nota: Se ignorarán las columnas no numéricas.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[5, 3, 6, 4],
"B":[11, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, 8]})
# Print the dataframe
df
Producción :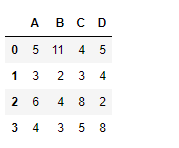
Ahora encuentre la covarianza entre las columnas del marco de datos
# To find the covariance df.cov()
Producción :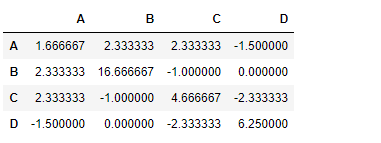
Ejemplo #2: use cov()la función para encontrar la covarianza entre las columnas del marco de datos que tienen NaNvalor.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[5, 3, None, 4],
"B":[None, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, None]})
# To find the covariance
df.cov()
Producción :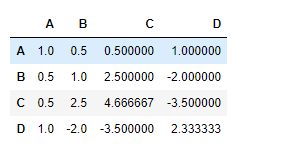
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA