Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas dataframe.cumprod()se utiliza para encontrar el producto acumulativo de los valores vistos hasta ahora en cualquier eje.
Cada celda se rellena con el producto acumulativo de los valores vistos hasta el momento.
Sintaxis: DataFrame.cumprod(axis=Ninguno, skipna=True, *args, **kwargs)
Parámetros:
eje: {índice (0), columnas (1)}
skipna: Excluir NA/valores nulos. Si una fila/columna completa es NA, el resultado será NADevoluciones: cumprod : Serie
Ejemplo #1: Use cumprod()la función para encontrar el producto acumulativo de los valores vistos hasta ahora a lo largo del eje del índice.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[5, 3, 6, 4],
"B":[11, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, 8]})
# Print the dataframe
df
Producción :
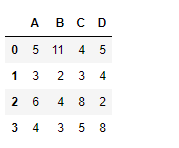
Ahora encuentre el producto acumulativo de los valores vistos hasta ahora sobre el eje del índice
# To find the cumulative prod df.cumprod(axis = 0)
Producción :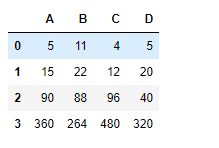
Ejemplo #2: Use cumprod()la función para encontrar el producto acumulativo de los valores vistos hasta ahora a lo largo del eje de la columna.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[5, 3, 6, 4],
"B":[11, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, 8]})
# cumulative product along column axis
df.cumprod(axis = 1)
Producción :
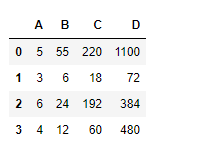
Ejemplo #3: Use cumprod()la función para encontrar el producto acumulativo de los valores vistos hasta ahora a lo largo del eje de índice en un marco de datos con NaNvalor presente en el marco de datos.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[5, 3, None, 4],
"B":[None, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, None]})
# To find the cumulative product
df.cumprod(axis = 0, skipna = True)
Producción :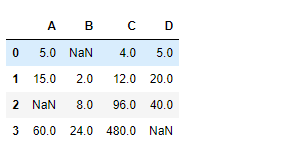
La salida es un marco de datos con celdas que contienen el producto acumulativo de los valores vistos hasta ahora a lo largo del eje del índice. NanSe omite cualquier valor en el marco de datos.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA