Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas dataframe.div() se usa para encontrar la división flotante del marco de datos y otros elementos. Esta función es similar a dataframe/other, pero con un soporte adicional para manejar el valor faltante en uno de los datos de entrada.
Sintaxis: DataFrame.div(otro, eje=’columnas’, nivel=Ninguno, valor_de_relleno=Ninguno)
Parámetros:
otro : Serie, Marco de datos o constante
eje : Para entrada de Serie, eje para coincidir Índice de serie en
valor_relleno : Relleno faltante (NaN ) valores con este valor. Si faltan ambas ubicaciones de DataFrame, faltará el resultado
level : Broadcast a través de un nivel, haciendo coincidir los valores de Index en el nivel de MultiIndex pasado
Devuelve: resultado : DataFrame
Ejemplo #1: use la función div() para encontrar la división flotante de los elementos del marco de datos con un valor constante. También maneje el valor de NaN presente en el marco de datos.
Python3
# importing pandas as pd
import pandas as pd
# Creating the dataframe with NaN value
df = pd.DataFrame({"A":[5, 3, None, 4],
"B":[None, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, None]})
# Print the dataframe
df
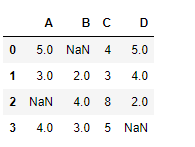
Ahora encuentre la división de cada elemento del marco de datos con 2
Python3
# Find the division with 50 being substituted # for all the missing values in the dataframe df.div(2, fill_value = 50)
Producción :
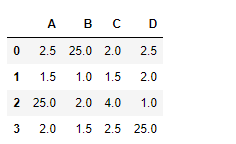
La salida es un marco de datos con celdas que contienen el resultado de la división de cada valor de celda con 2. Todas las celdas NaN se han llenado con 50 antes de realizar la división.
Ejemplo #2: use la función div() para encontrar la división flotante de un marco de datos con un objeto de serie sobre el eje de índice.
Python3
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[5, 3, 6, 4],
"B":[11, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, 8]})
# Create a series object with no. of elements
# equal to the element along the index axis.
# Creating a pandas series object
series_object = pd.Series([2, 3, 1.5, 4])
# Print the series_obejct
series_object
Producción :

Nota: Si la dimensión del eje de índice del marco de datos y el objeto de la serie no son iguales, se producirá un error.
Ahora, encuentre la división de los elementos del marco de datos con el objeto de la serie a lo largo del eje de índice
Python3
# To find the division df.div(series_object, axis = 0)
Producción :
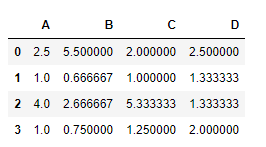
La salida es un marco de datos con celdas que contienen el resultado de la división del elemento de celda actual con la celda de objeto de serie correspondiente.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA