Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
La función Pandas dataframe.filter()se utiliza para crear subconjuntos de filas o columnas del marco de datos de acuerdo con las etiquetas en el índice especificado. Tenga en cuenta que esta rutina no filtra un marco de datos en su contenido. El filtro se aplica a las etiquetas del índice.
Sintaxis: DataFrame.filter(items=Ninguno, like=Ninguno, regex=Ninguno, axis=Ninguno)
Parámetros:
elementos: Lista de ejes de información para restringir (no todos deben estar presentes)
como: Mantener el eje de información donde «arg in col == True»
expresión regular: Mantener el eje de información con re.search (regex, col) ==
Eje verdadero : El eje sobre el que filtrar. De forma predeterminada, este es el eje de información, ‘índice’ para Series, ‘columnas’ para DataFrameDevoluciones: mismo tipo que el objeto de entrada
Los parámetros items, like y regex están obligados a ser mutuamente excluyentes. Por defecto, el eje es el eje de información que se usa cuando se indexa con [].
Para el enlace al archivo CSV, haga clic aquí
Ejemplo n.º 1: use filter()la función para filtrar tres columnas cualesquiera del marco de datos.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
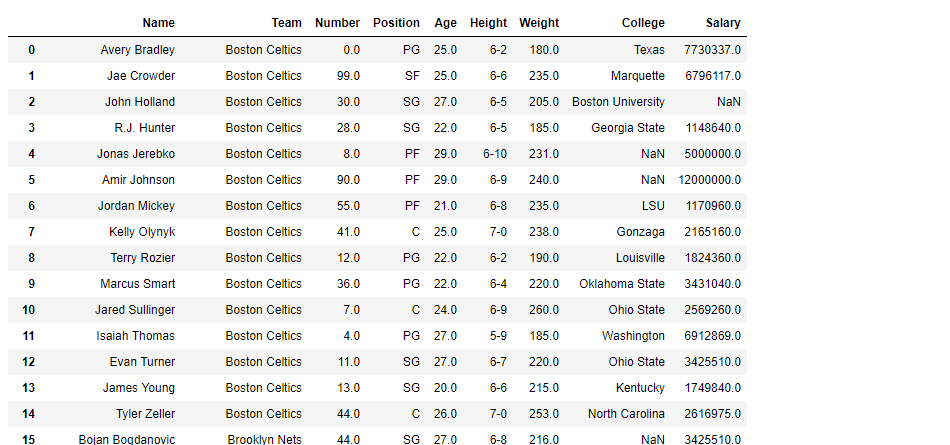
Ahora filtre las columnas «Nombre», «Colegio» y «Salario».
# applying filter function df.filter(["Name", "College", "Salary"])
Producción :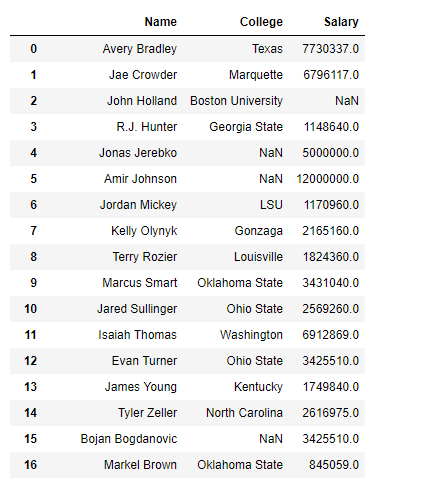
Ejemplo n.º 2: use filter()la función para crear un subconjunto de todas las columnas en un marco de datos que tenga la letra ‘a’ o ‘A’ en su nombre.
Nota: filter() la función también toma una expresión regular como uno de sus parámetros.
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Using regular expression to extract all
# columns which has letter 'a' or 'A' in its name.
df.filter(regex ='[aA]')
Producción :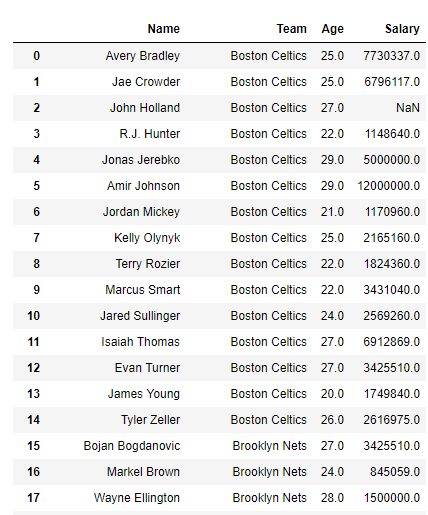
La expresión regular ‘[aA]’ busca todos los nombres de columna que tienen una ‘a’ o una ‘A’ en su nombre.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA